别让上游宕机变成你的宕机。AIHubMix 提供两个Key 级别的能力,在控制台配置一次即可生效,客户端代码无需改动:
- 模型名映射(Model Mapping)是指在网关层把客户端请求里的模型别名改写为真实上游模型的能力。
- 错误时回退模型(Fallback)是指当主模型调用失败时,网关按预先配置的优先级顺序自动尝试备用模型,对客户端无感。
AIHubMix 支持在 Key 级别配置模型名映射与错误回退,并按最终响应模型计费。两者都在 AIHubMix Key 管理页 为单个 API Key 配置。
Model name mapping 和 Fallback models on error 两个区块分别配置:
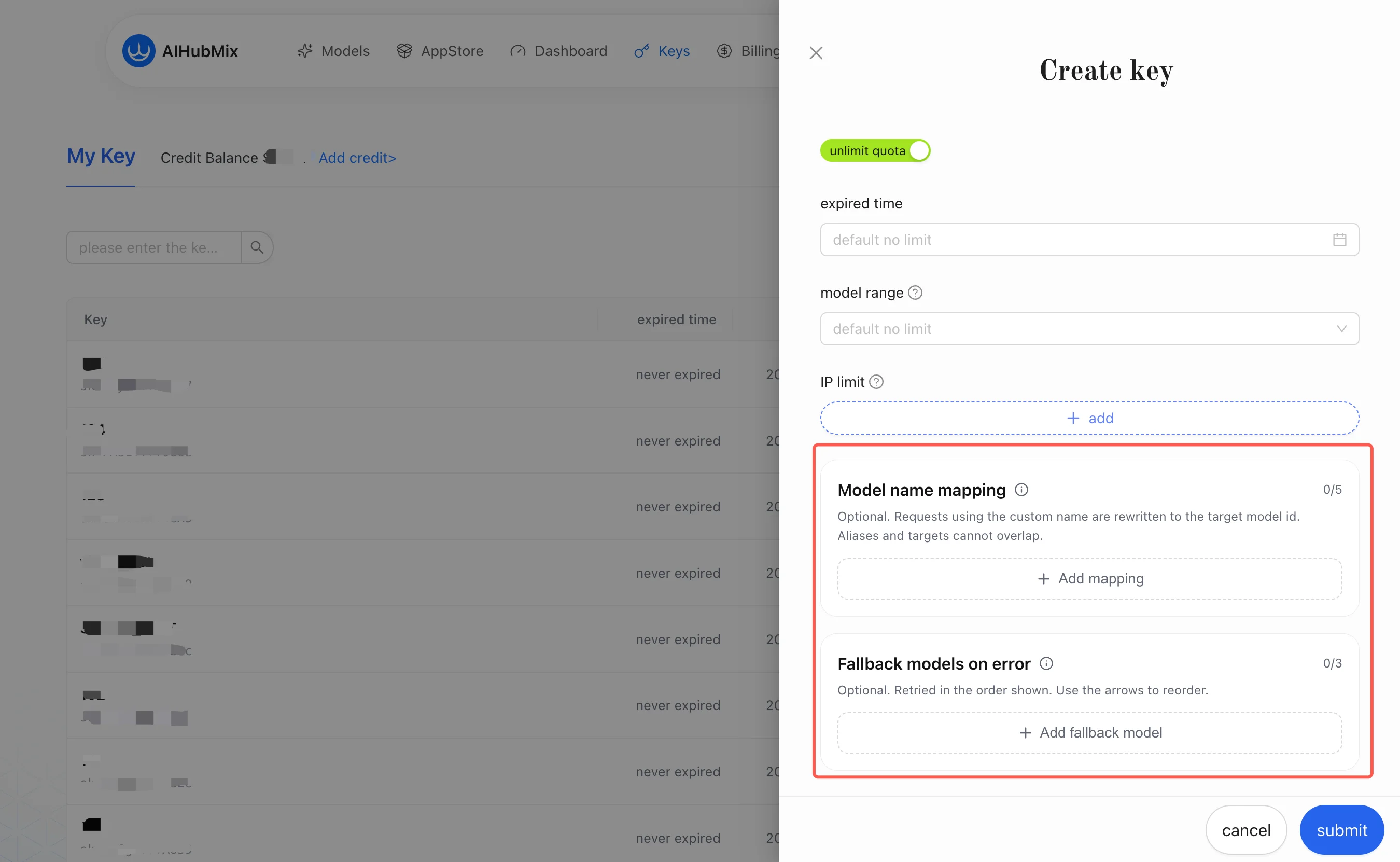
1. 模型名映射(Model Mapping)
模型名映射用于处理「客户端看到的模型名」和「AIHubMix 实际调用的模型」不一致的问题。它是Key 级(per-key)的别名改写:把请求里的别名改写成你在 Key 里配置的目标模型。目标模型在选定渠道后,平台内部还会做一层渠道级映射到真实上游模型;该层对用户透明、无需配置。你只需要关心「别名 → 目标模型」这一层。示例:
上表模型名均可在 AIHubMix 模型页 查询。常见用途:
- 客户端限制模型名格式,例如 Claude Desktop 要求模型名符合 Claude 风格(见 第 5 节)。
- 给复杂模型 ID 设置更短、更稳定的别名。
- 客户端配置保持不变,AIHubMix 后台切换真实模型。
- 多个平台共用一套接入命名,但根据 Key 路由到不同模型。
逐字符一致:客户端发送的模型名必须和映射左侧逐字符一致。例如my-gpt-5.5和my-gpt-5-5是两个不同的字符串,不一致就不会命中映射。
2. 错误时回退模型(Fallback)
错误时回退模型用于在主模型失败时按顺序尝试备用模型。它不是客户端侧重试,而是 AIHubMix 网关侧在同一个 Key 配置下完成的模型切换;接入方不需要在每次请求里传额外路由参数。 可以把 Fallback 理解成「映射到一个有序列表」:主模型失败后,网关自动沿列表往下一个备用模型走。 示例(在同一个 Key 里配置):2.1 触发条件(必须全部满足才回退)
只有以下条件全部成立时才会发生回退:- Key 配置了非空的备用模型列表。
- 主模型的所有渠道都被试过、且都以「可重试错误」失败(渠道耗尽)。
- 响应尚未开始返回(首字节 / header 还没发给客户端)。
- 错误不是 Key / 用户级错误(见下方 2.2 对照表)。
2.2 哪些会回退、哪些不会
说明:这里「Key 失效」指的是你自己的 AIHubMix Key失效,不会回退。若是某个上游渠道的 key 坏了,网关会换渠道,渠道耗尽后仍可回退——两者不要混淆。
2.3 计费口径
按最终响应模型计费。 如果最终由回退模型响应,计费、能力和上下文限制都以最终响应的那个模型为准。这个模型也会体现在响应头里(见 第 4 节)。2.4 免费模型规则(重要)
免费模型不能作为 fallback 选项——免费模型只能作主模型,放进备用列表会被静默跳过,继续往下一个。所以不要把免费模型写进 fallback 列表。典型用法:把免费模型设为主模型、付费模型放进备用列表。免费主模型触发额度 / 频率限流时,会自动回退到备用的付费模型——平时省成本用免费额度,限流后无缝切到付费模型保证可用。这是 fallback 最常见的用法之一。
3. 和 OpenRouter / LiteLLM 的区别
模型映射和回退并不是新概念,OpenRouter、LiteLLM 等都提供类似能力。AIHubMix 的差异在于配置成本最低:
一句话:不用自建网关、不用改一行客户端代码,在 Key 上配一次就生效。
4. 配置与验证
4.1 配置
- 在Key里配置别名映射:左侧别名要和客户端实际发送的模型名逐字符一致。
- 在同一 Key里配置备用模型列表(有序优先级列表)。
- 备用列表只放付费 / 可用模型,不放免费模型(会被跳过)。
- 备用列表里的模型必须在该 Key 的可用模型范围内(越权模型会被跳过)。
4.2 验证(优先看响应头,而不是翻日志)
排查时不要只看客户端选了哪个模型,最权威、可自动化的方式是读响应头:X-Aihubmix-Fallback: true:本次请求发生了回退(最终模型 ≠ 主模型时附加)。X-Aihubmix-Model:本次实际响应、且据此计费的模型。
5. 场景一:Claude Desktop
Claude Desktop 通过Gateway 接入 AIHubMix,是模型名映射的典型场景。
本节假设你已经完成 Claude Desktop 的基础接入。完整接入步骤(下载安装、开发者模式、Gateway 配置、auth scheme 等)见 在 Claude Desktop 中接入 AIHubMix,本节只讲映射与回退的增量配置。
5.1 为什么需要映射
Claude Desktop 以Gateway(Anthropic-compatible)方式接入,客户端会按 Claude 风格约束模型名,因此模型名必须使用 claude- 前缀。
于是产生一个矛盾:客户端那侧只能写 claude- 风格的名字,但你真正想调用的是 gpt-5.5、gemini-3.1-pro-preview 这些。模型名映射正是为此而生——客户端写别名 claude-g-p-t-5.5,AIHubMix 侧映射到真实的 gpt-5.5。
Claude Desktop 走的是 Claude 原生 /v1/messages 接口,所以本文示例里映射和 Fallback 都生效。
5.2 AIHubMix 映射与回退配置
示例配置: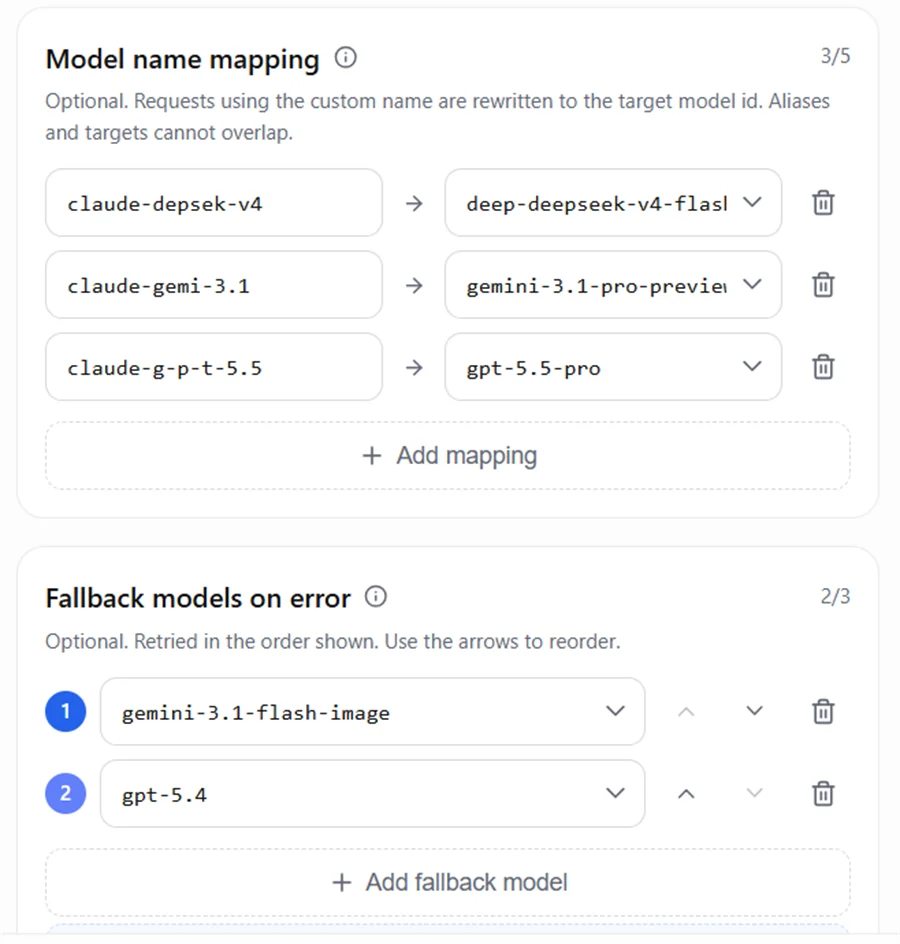
5.3 Claude Desktop 模型列表
在 Claude Desktop 的Model list 里配置的是映射前的别名——也就是 Claude Desktop 发给 AIHubMix 的模型名,不是真实上游模型名。
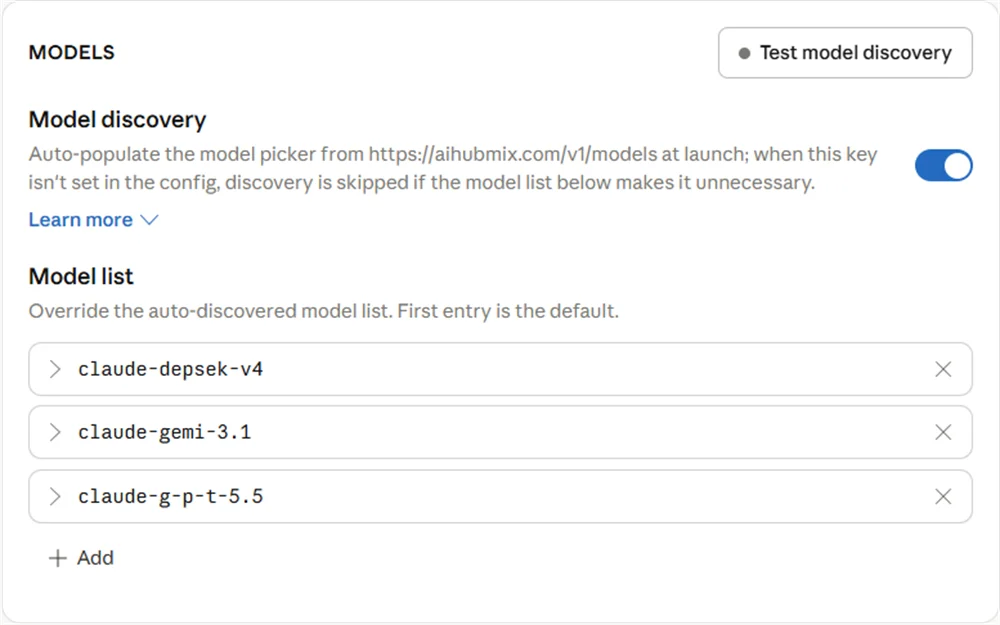
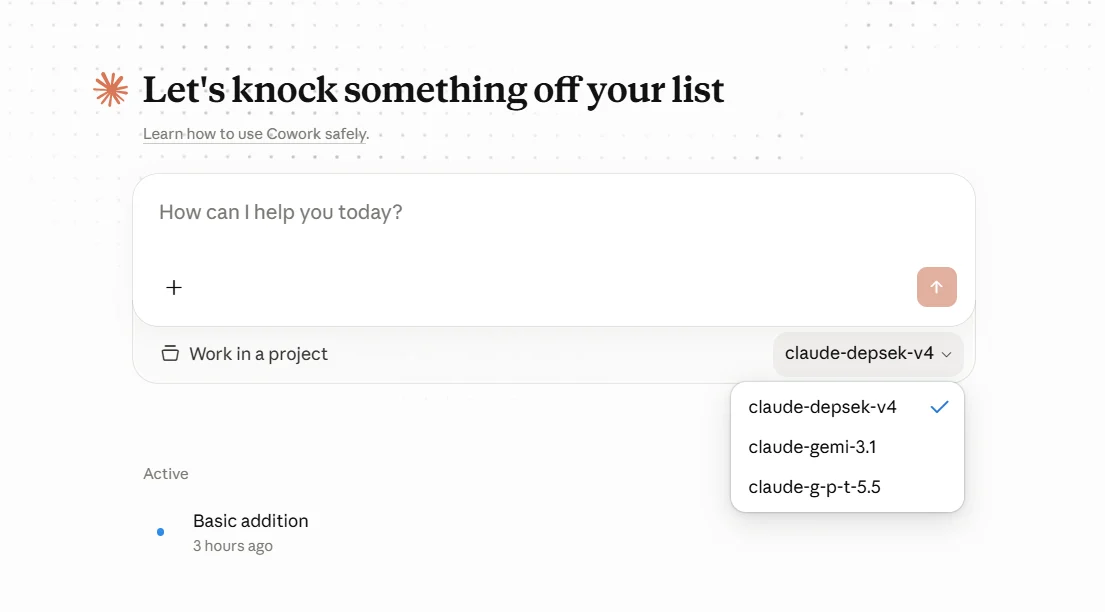
Model ID使用claude-前缀。- 不要直接写
gpt、gemini、deepseek等真实模型系列名,可使用g-p-t、gemi、depsek等别名。 Model ID必须和 AIHubMix 映射左侧逐字符一致,否则请求不会命中预期映射,可能继续走错误回退模型。
6. 场景二:多模态能力兜底
多模态能力兜底用于处理「主模型能回答文本,但不支持当前输入类型」的场景。比如客户端发送了图片或视频,主模型只有文本输入能力,AIHubMix 可以继续尝试回退列表里支持对应模态的模型。 下面是一条实际测试链路。这条 Key 的映射与 fallback 配置如下(见下方截图),重点是 fallback 列表里既有文本模型也有支持图片理解的模型:claude-g-l-m-4.6——一个只支持文本输入的模型。用户上传了一张 AIHubMix 模型列表页面截图,并询问「这个网站是做什么的」。因为请求里包含图片,文本模型无法直接处理该输入,于是触发了 fallback。
Google AI Studio/gemini-3.1-flash-image,也就是 fallback 列表里的第 2 个。第 1 个 gpt-5.4 同样不支持该图片输入、对这次请求继续返回可重试错误,于是网关接着往下,落到了支持图片理解的 gemini-3.1-flash-image。
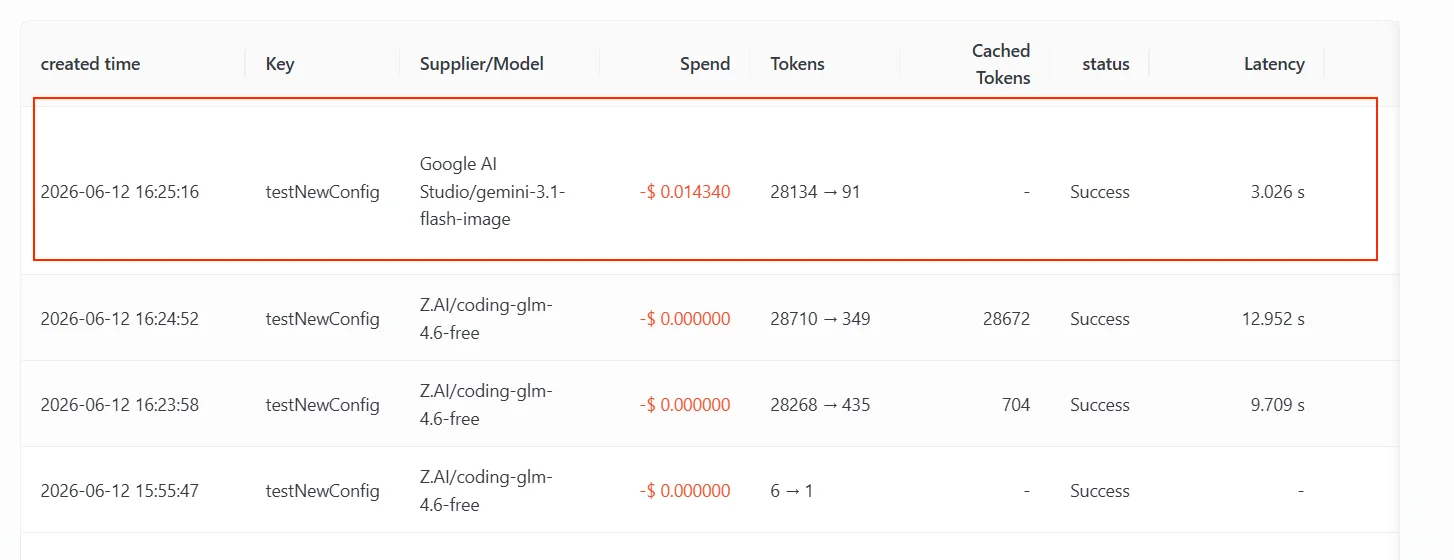
触发原因要讲清:这里兜底是因为上游对该图片输入返回了可重试错误、且主模型渠道耗尽——和「主模型限流后回退」是同一套回退机制,只是触发的错误类型不同(前者是输入不被支持,后者是额度 / 频率限流)。
注意区分理解与生成:这里说的是图片 / 视频理解兜底,不是图片生成或视频生成。聊天请求不会自动变成生成接口;要测试画图或视频生成,应走对应的生成接口和模型。模型能力以 AIHubMix 模型页当前标注的 Input Modalities 为准。
7. 场景三:免费模型兜底(省成本 + 保可用)
这是 fallback 最常见的用法之一:把免费模型设为主模型、付费模型放进备用列表。平时请求都走免费模型、省成本;一旦免费主模型触发额度 / 频率限流,网关自动回退到备用的付费模型,保证服务不中断。 示例 Key 配置:- 免费额度还够用时,请求由主模型
coding-glm-5.2-free响应,按免费计费。 - 免费主模型触发限流后,自动回退到
gpt-5.4;若gpt-5.4也不可用,再尝试gemini-3.1-pro-preview。 - 最终由哪个模型响应,就按那个模型计费(见 2.3)。
注意:免费模型只能作主模型,不能放进 fallback 列表(放进去会被跳过,见 2.4)。所以「免费兜底」的正确姿势是:免费在主、付费在备,而不是反过来。验证方式同样是看响应头:发生回退时返回
X-Aihubmix-Fallback: true,X-Aihubmix-Model 显示最终响应模型(见 第 4 节)。
8. 支持的端点
模型映射与错误回退目前支持以下接口类别:
要点:
- 模型映射与错误回退支持 OpenAI 兼容接口、Claude 原生
/v1/messages、OpenAI Responses/v1/responses三类接口。 - 其他原生透传接口(Gemini 原生、Ideogram、视频、TTS、Stability、OCR、predictions 等)、指定渠道透传、以及按资源 ID 检索 / 文件类接口暂不支持。
- Claude Desktop 走的是 Claude 原生
/v1/messages,所以本文示例里映射和 Fallback 都生效。
9. 常见问题 FAQ
Q:Claude Desktop 提示 model not found 怎么办? A:检查 Claude Desktop 里的Model ID 是否和 AIHubMix 映射左侧逐字符一致;不一致就不会命中映射。
Q:回退会不会影响计费?
A:按最终响应模型计费。最终是哪个模型响应,就按那个模型的价格、能力和上下文限制计算。
Q:怎么确认这次请求到底走没走回退?
A:看响应头 X-Aihubmix-Fallback: true(发生了回退)和 X-Aihubmix-Model(最终响应模型),见 第 4 节。
Q:哪些错误会触发回退,哪些不会?
A:见 2.2 的对照表。简单说:上游可重试失败、渠道耗尽、响应未开始才会回退;指定渠道、响应已开始、客户端断开 / 超时、Key / 用户级错误都不回退。
Q:免费模型能放进 fallback 列表吗?
A:不能,会被跳过。免费模型只能作主模型。
Q:和 OpenRouter / LiteLLM 的 model alias / fallback 有什么区别?
A:AIHubMix 是Key 级、平台托管,在控制台配一次就生效,不用改客户端代码、也不用自建网关。详见 第 3 节。
相关资源
- 在 Claude Desktop 中接入 AIHubMix:开发者模式、Gateway 配置、auth scheme 等完整步骤。
- AIHubMix 模型页:查询模型名称、价格与
Input Modalities。 - 在 LiteLLM 中接入 AIHubMix:需要自建网关 + 模型映射 / 回退时的参考。