不同 Claude 模型的最小可缓存 Token 门槛不同(512 / 1,024 / 2,048 / 4,096 不等),该门槛由各模型单独设定、并非随版本升级而提高:例如 Claude Opus 4.8 为 1,024、Claude Opus 4.7 为 2,048、Claude Opus 4.6 / 4.5 与 Claude Haiku 4.5 为 4,096。完整分档见下文「缓存限制」。低于门槛的前缀即使显式设置
cache_control 也不会被缓存,且不会返回错误。提示词缓存的工作原理
当你发送启用了提示词缓存的请求时:- 系统会检查是否已经缓存了最近查询中指定缓存断点之前的提示词前缀
- 如果找到,就使用缓存版本,减少处理时间和成本
- 否则,系统会处理完整提示词,并在开始响应时缓存前缀部分
- 包含大量示例的提示词
- 大量的上下文或背景信息
- 具有一致指令的重复任务
- 长时间的多轮对话
常见错误:写了缓存却”只写不读”
最常见的失效场景是:每轮请求cache_creation_input_tokens 都很大(一直在写缓存),但 cache_read_input_tokens 始终为 0(从来读不到),等于完全没省到钱。
根因只有一个:缓存断点(cache_control)之前的内容,在两次请求之间发生了变化。 缓存命中要求断点及其之前的所有内容(按 tools → system → messages 顺序)逐字节完全一致;只要断点前有任何一个字变了,整段前缀缓存全部作废、重新写入。
❌ 错误写法:把每轮会变的问题放在断点前面
✅ 正确写法:大文档放最前 + 断点 + 问题放最后
实测对照(claude-opus-4-6,两次调用间隔数秒)
要点:
- 固定不变的大块(参考文档、长上下文)放在
messages用户消息的最前面,cache_control打在它末尾,这段内容一个字都不能动; - 每轮变化的问题/指令放到断点之后(同一条
user消息里大文档之后,或后续消息);多轮对话只往后追加,不要回头修改历史消息; - 开启
thinking时,历史助手轮里的思考块要原样回传,否则前缀同样会断(见下文「无法缓存的内容」); - 若该块小于最小缓存门槛(不同模型 512–4,096 Token 不等,见下文「缓存限制」),即使显式设置
cache_control也不会被缓存——这是预期行为。
缓存定价
提示词缓存采用新的定价结构。下表显示了每个支持模型的百万 Token 价格:
注意:
- 5 分钟缓存写入 Token 价格为基础输入 Token 价格的 1.25 倍
- 1 小时缓存写入 Token 价格为基础输入 Token 价格的 2 倍
- 缓存读取 Token 价格为基础输入 Token 价格的 0.1 倍
- 常规输入和输出 Token 按平台标准费率计价
如何实现提示词缓存
支持的模型
Anthropic Claude 全系模型均支持提示词缓存,包括 Claude Opus 4.8 / 4.7 / 4.6 / 4.5、Claude Sonnet 5 / 4.6 / 4.5、Claude Haiku 4.5、Claude Fable 5 等当前模型,以及 Claude Opus 4、Sonnet 4、Sonnet 3.7、Sonnet 3.5、Haiku 3.5、Haiku 3、Opus 3 等早期模型。不同模型的最小可缓存 Token 门槛见下文「缓存限制」。自动缓存(顶层 cache_control)
在请求体顶层添加一个cache_control 字段即可启用自动缓存:系统自动将缓存断点应用到最后一个可缓存块,并随对话增长自动前移,适合多轮对话滚动缓存。自动断点占用 4 个断点槽位中的 1 个,可与块级显式断点组合使用。Amazon Bedrock 平台不支持自动缓存。
构建提示词结构
将静态内容 (工具定义、系统指令、上下文、示例) 放在提示词的开头。使用cache_control 参数标记要缓存的可重用内容的结束位置。
缓存前缀按以下顺序创建:tools、system,然后是 messages。
使用 cache_control 参数,你可以定义最多 4 个缓存断点,允许分别缓存不同的可重用部分。对于每个断点,系统会自动检查之前位置的缓存命中情况,如果找到就使用最长的匹配前缀。
缓存限制
最小可缓存提示词长度按模型区分,该门槛并非随版本升级而提高:
即使标记了
cache_control,更短的提示词也无法缓存。任何请求缓存少于这个数量的 Token 都会在不使用缓存的情况下处理。要查看提示词是否被缓存,请查看响应使用情况字段。
对于并发请求,注意缓存条目只有在第一个响应开始后才可用。如果需要并行请求的缓存命中,请等待第一个响应后再发送后续请求。
目前支持的缓存生存期:
- “ephemeral”:默认 5 分钟生存期
- 1 小时缓存:在
cache_control中设置"ttl": "1h",适用于需要更长缓存时间的场景
1 小时缓存持续时间
对于需要更长缓存时间的场景,我们提供 1 小时缓存选项。 在cache_control 定义中包含 ttl 即可,无需额外请求头:
何时使用 1 小时缓存
1 小时缓存特别适用于:- 批处理作业:处理大量具有共同前缀的请求
- 长时间会话:需要在较长时间内保持上下文的对话
- 大型文档分析:对同一文档进行多次不同类型的分析
- 代码库问答:在较长时间内对同一代码库进行多次查询
混合不同的 TTL
你可以在同一个请求中混合使用不同的缓存持续时间:可以缓存的内容
请求中的每个块都可以用 cache_control 指定缓存。这包括:- 工具:tools 数组中的工具定义
- 系统消息:system 数组中的内容块
- 消息:messages.content 数组中的内容块,包括用户和助手的对话轮次
- 图片和文档:用户对话轮次中 messages.content 数组的内容块
- 工具使用和工具结果:用户和助手对话轮次中 messages.content 数组的内容块
cache_control 标记来启用该部分请求的缓存。
无法缓存的内容
虽然大多数请求块都可以缓存,但有一些例外:- 思考块无法直接使用
cache_control缓存。但是,当思考块出现在之前的助手回合中时,可以与其他内容一起缓存。以这种方式缓存时,从缓存读取时它们确实计为输入 Token。 - 子内容块(如引用)本身无法直接缓存。相反,缓存顶级块。
- 空文本块无法缓存。
跟踪缓存性能
通过响应中的这些 API 响应字段 (或流式传输时的 message_start 事件) 监控缓存性能:cache_creation_input_tokens: 创建新缓存条目时写入缓存的 Token 数cache_read_input_tokens: 从缓存中检索的 Token 数input_tokens: 未从缓存读取或用于创建缓存的输入 Token 数
有效缓存的最佳实践
要优化提示词缓存性能:- 缓存稳定的、可重用的内容,如系统指令、背景信息、大型上下文或常用工具定义
- 将缓存内容放在提示词开头以获得最佳性能
- 策略性地使用缓存断点来分隔不同的可缓存前缀部分
- 定期分析缓存命中率并根据需要调整策略
- 对于长期使用的内容,考虑使用 1 小时缓存以获得更好的成本效益
针对不同用例的优化
根据你的场景调整提示词缓存策略:- 对话代理:减少长时间对话的成本和延迟,特别是那些有长指令或上传文档的对话
- 编程助手:通过在提示词中保留相关部分或代码库的摘要版本,改善自动完成和代码库问答
- 大文档处理:在提示词中包含完整的长篇材料 (包括图片),而不增加响应延迟
- 详细指令集:共享广泛的指令、程序和示例列表来微调 Claude 的响应。开发者通常在提示词中包含一两个示例,但使用提示词缓存,你可以通过包含 20+ 个高质量答案的多样化示例获得更好的性能
- 代理工具使用:提升涉及多个工具调用和迭代代码更改的场景性能,每个步骤通常需要新的 API 调用
- 与书籍、论文、文档、播客记录和其他长篇内容对话:通过在提示词中嵌入整个文档,让用户能够提问
常见问题解决
- 确保缓存部分在不同调用之间完全相同,并在相同位置标记了
cache_control - 检查调用是否在缓存生存期内(5 分钟或 1 小时)
- 验证
tool_choice和图片使用在调用之间保持一致 - 确认你缓存的 Token 数至少达到最小要求
- 虽然系统会尝试使用缓存断点之前位置的已缓存内容,但你可以使用额外的
cache_control参数来保证查找提示词前面部分的缓存,这对于包含很长内容块列表的查询可能很有用
缓存存储和共享
- 组织隔离: 缓存在组织之间是隔离的。不同组织永远不会共享缓存,即使它们使用相同的提示词。
- 精确匹配: 缓存命中需要 100% 相同的提示词段,包括标记有 cache control 的块之前及其本身的所有文本和图片。在缓存读取和创建期间必须用 cache_control 标记相同的块。
- 输出 Token 生成: 提示词缓存不会影响输出 Token 生成。你收到的响应将与不使用提示词缓存时完全相同。
在客户端 / 平台中启用 Claude 缓存
很多客户端的界面没有地方直接填cache_control,而是用各自的”语法糖”或开关替你注入。底层规则与上文完全一致——被缓存的前缀必须每轮逐字不变,会变化的内容放在缓存断点之后,否则会”只写不读”(见上文「常见错误」)。
Dify(通过 Aihubmix 插件)
Aihubmix 的 Dify 插件继承了 Anthropic 官方插件的语法糖,两步开启:- 用
<cache>…</cache>包裹要缓存的提示词(固定不变的系统提示词 / 长上下文),插件会在该处自动转换成cache_control断点; - 在模型参数里把「大消息自动缓存阈值」设为一个正整数:内容达到该 Token 阈值才会真正写缓存(仍受下文「缓存限制」的最小缓存约束,Opus 4.5/4.6、Haiku 4.5 为 4096 Token),设 0 或留空则关闭。
Cherry Studio
Cherry Studio 经 Aihubmix 调用 Claude 默认不开缓存(「缓存 Token 阈值」默认为0),需要在供应商的「API 设置」里打开。
- 点击 Aihubmix 供应商名称右侧的齿轮,打开「API 设置」(API Settings):
- 配置以下三项,客户端会据此为 Claude 自动注入
cache_control:
- 缓存 Token 阈值(Cache Token Threshold):内容超过该 Token 数才注入缓存断点(设正数开启,0 或留空关闭);
- 缓存系统消息(Cache System Message):开启后给
system消息打缓存断点(适合缓存固定的长系统提示词); - 缓存最后 N 条消息(Cache Last N Messages):给最近 N 条消息打缓存断点(适合多轮对话滚动缓存)。
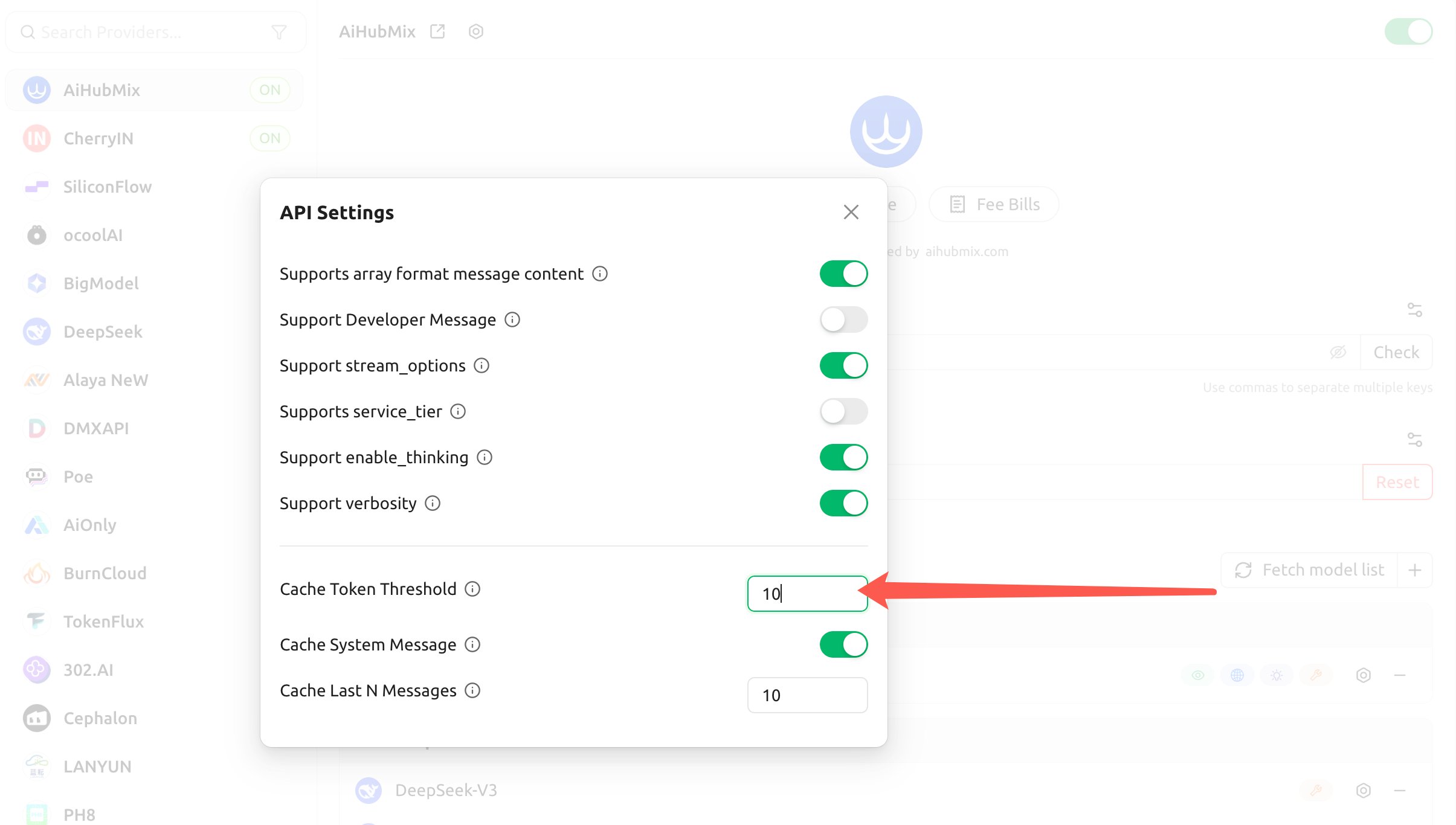
上述阈值只决定客户端”何时注入断点”,并不改变 Anthropic 的最小缓存要求:实际写入仍需被缓存内容达到最小缓存 Token(Opus 4.5/4.6、Haiku 4.5 为 4096)。若把每轮会变的内容(如轮换的指令)放进被缓存的系统提示词里,同样会”只写不读”。
常见问题(FAQ)
为什么写了缓存(cache_creation_input_tokens 很大)却一直读不到(cache_read_input_tokens 为 0)?
因为缓存断点(cache_control)之前的内容在两次请求之间变了。命中要求断点及其之前的所有内容逐字节一致;一旦把每轮会变的内容放在断点前面,整段前缀缓存就作废、每轮重写。把固定内容放最前、变化内容放断点之后即可,详见上文「常见错误」。
缓存最少需要多少 Token?
低于最小缓存长度的前缀即使显式设置cache_control 也不会被缓存;各模型的最小门槛见上文「缓存限制」。
缓存有效期多久?能改成 1 小时吗?
默认 5 分钟,每次命中都会免费刷新。需要更久可在cache_control 中设 "ttl": "1h",无需额外请求头。1 小时档缓存写入按基础输入价的 2 倍计费。详见上文「1 小时缓存持续时间」。
在 Dify / Cherry Studio 里怎么开缓存?
这些客户端不直接填cache_control:Dify 用 <cache>…</cache> 包裹要缓存的内容并设「大消息自动缓存阈值」;Cherry Studio 在「API 设置」里设「缓存 Token 阈值 / 缓存系统消息 / 缓存最后 N 条消息」。详见上文「在客户端 / 平台中启用 Claude 缓存」。
不同模型的支持情况
- 是否支持 Prompt Caching 取决于模型本身。
- 如果模型本身支持,并且不需要显式声明相关的参数,则通过 opanai 兼容格式转发可以支持。
- OpenAI 默认支持 Prompt Caching,自动生效(前缀 ≥1024 Token)。GPT-5.6 之前的模型缓存写入不另计费,不活跃 5-10 分钟后自动清除;GPT-5.6 及之后缓存写入按 1.25 倍输入价计费、读取按 0.1 倍计费,缓存至少保留 30 分钟,并支持显式缓存断点。详见 GPT 提示词缓存。
- Claude 需要原生的
cache_control: { type: "ephemeral" }声明,缓存费率为常规输入的 1.25 倍(5 分钟)或 2 倍(1 小时),缓存 Tokens 读取费用为 0.1 倍,生命周期 5 分钟或 1 小时。文档 - Deepseek V3 和 R1 原生支持,缓存费率为常规输入的 1 倍,缓存 Tokens 读取费用为 0.1 倍。文档
- Gemini 模型支持隐式缓存:
- 隐式缓存:默认情况下为所有 Gemini 2.5 模型启用。如果你的请求命中缓存,会自动传递成本节省。此功能自 2025 年 5 月 8 日起生效。上下文缓存的最低输入 Token 数:Gemini 2.5 Flash 为 1,024,Gemini 2.5 Pro 为 2,048。
- 提高隐式缓存命中率的技巧:
- 将大块的常见内容放在提示的开头。
- 尝试在短时间内发送前缀相似的请求。
- 你可以在响应对象的
usage_metadata字段中查看缓存命中的 Token 数量。 - 成本节省是根据预填充缓存命中次数衡量的。只有预填充缓存和 YouTube 视频预处理缓存支持隐式缓存。
- 提高隐式缓存命中率的技巧:
- 隐式缓存:默认情况下为所有 Gemini 2.5 模型启用。如果你的请求命中缓存,会自动传递成本节省。此功能自 2025 年 5 月 8 日起生效。上下文缓存的最低输入 Token 数:Gemini 2.5 Flash 为 1,024,Gemini 2.5 Pro 为 2,048。
更新时间:2026-07-10