Imagen 绘图
Imagen 是 Google 推出的先进图像生成 AI 模型系列,能够根据文本提示创建高质量、逼真的图像。本指南将帮助您了解如何使用 Imagen 系列 API 生成图像,包括参数设置、模型选择和代码示例。 可用模型列表:imagen-4.0-generate-001:最新的正式版imagen-4.0-ultra-generate-001:更高级的 ultra 正式版imagen-4.0-fast-generate-001:快速版本imagen-4.0-fast-generate-preview-06-06:快速版本预览版imagen-3.0-generate-002:3.0 正式版
模型参数
Imagen 目前仅支持英文提示词,并提供以下参数:- numberOfImages: 要生成的图像数量,范围从 1 到 4(含)。默认值为 4。另外注意
imagen-4.0-ultra-generate-001单次只能生成 1 张。 - aspectRatio: 更改生成图像的宽高比。支持的值有 “1:1”、“3:4”、“4:3”、“9:16” 和 “16:9”。默认值为 “1:1”。
- personGeneration: 允许模型生成人物图像。支持以下值:
- “DONT_ALLOW”: 阻止生成人物图像。
- “ALLOW_ADULT”: 生成成人图像,但不生成儿童图像。这是默认值。
费率
使用 Imagen API 生成图像的费用如下:- imagen-4-ultra:$0.06/张
- imagen-4:$0.04/张
- imagen-4-fast:$0.02/张
- imagen-3:$0.03/张
调用示例
以下是使用 Imagen 生成图像的 Python 调用示例:提示词技巧
创建有效的提示词对于获得理想的图像至关重要:- 使用详细的描述,包括主题、风格、光照、角度等。
- 指定艺术风格(如电影感、写实主义、动漫风格等)。
- 包含技术细节(如 DSLR、高清、细节丰富等)。
- 避免负面或违禁内容。
- 避免在提示词中包含大量文本,仅使用重点关键词以获得更稳定的结果。
- 关键词包含
girl时容易触发 TypeError: ‘NoneType’ object is not iterable 报错,不推荐用于人物绘制
Gemini 2.5 Flash 图像生成
Gemini 也提供了图像生成能力,作为一种替代方案。与 Imagen 系列相比,Gemini 的图像生成更适合于需要上下文理解和推理的场景,而非追求极致的艺术表现和视觉质量。- 更高的视觉质量 → 相比早前的 exp 版,图像更锐利、更丰富、更清晰。
- 更准确的文本呈现 → 生成的视觉中,文本更加精准、干净、易读。
- 显著减少过滤拦截 → 得益于更智能、宽松的过滤机制,创作时几乎不再被打断。
- 模型 id:
gemini-2.5-flash-image-preview,社交媒体上的别名是nano-banana - 费率(输入→输出):Text: $0.3→$2.5/M tokens; Image: $0.3→$30/M tokens
- 需要新增参数来体验新特性
"modalities":["text","image"] - 图片以 Base64 编码形式传递与输出
- 输出图片的默认尺寸为 1024*1024px,折合 1290 Tokens
- python 调用需要最新的 openai sdk 支持,请先运行
pip install -U openai - Aihubmix 平台支持 gemini 原生与 OpenAI 兼容则 2 种请求格式
- 了解更多请访问 Gemini 官方文档
图文生成
Iuput:text Output:text + image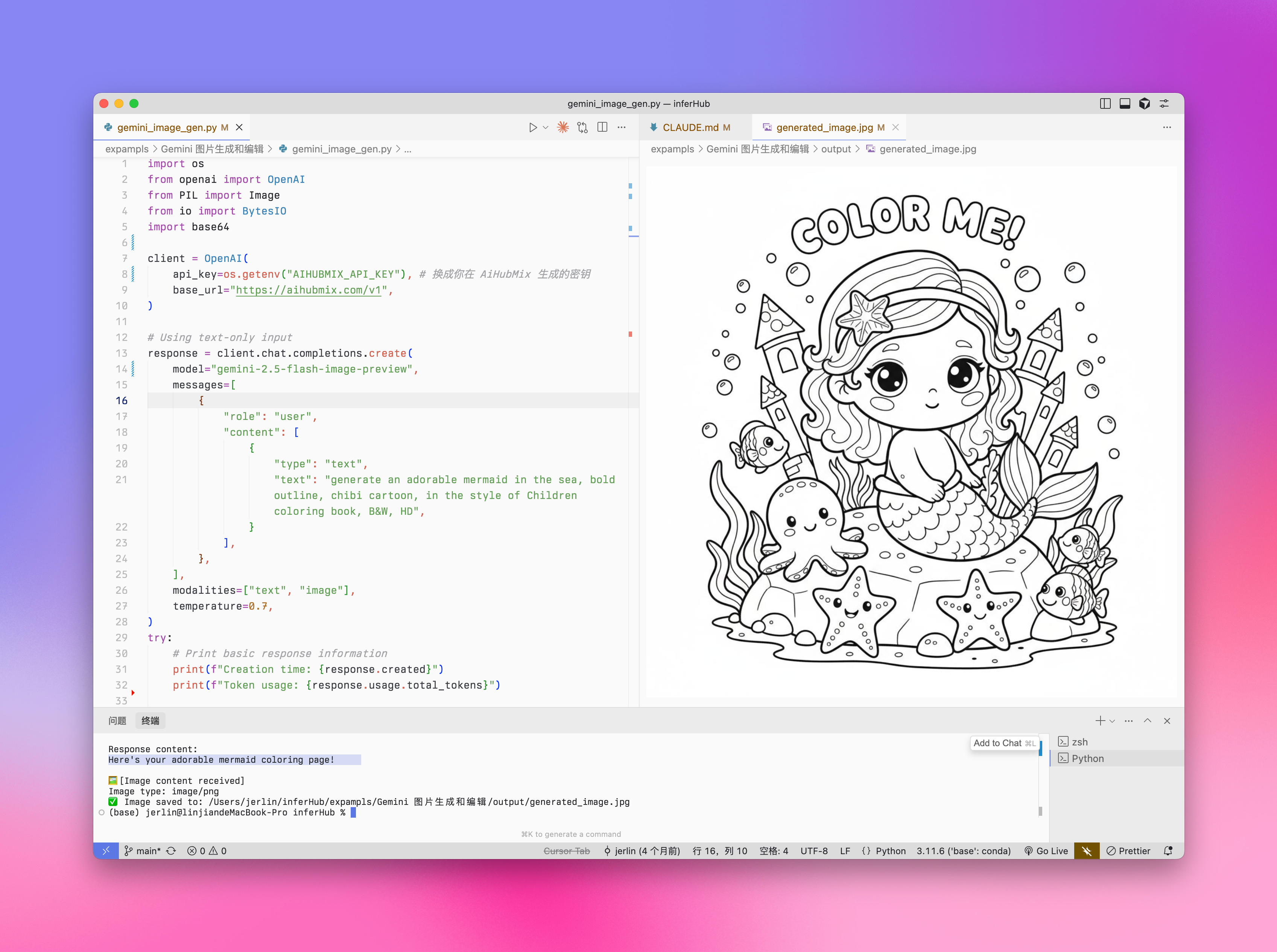
图片编辑
Iuput:text + imageOutput:text + image
选择正确的绘图模型
选择 Gemini 的情况:
- 需要利用世界知识和推理能力生成上下文相关的图像。
- 需要无缝混合文本和图像。
- 希望在长文本序列中嵌入准确的视觉内容。
- 希望在保持上下文的同时以对话方式编辑图像。
选择 Imagen 的情况:
- 图像质量、照片真实感、艺术细节或特定风格(如印象派、动漫)是首要考虑因素。
- 执行专业编辑任务,如产品背景更新或图像放大。
- 注入品牌、风格或生成标志和产品设计。
最佳实践
- 优化提示词:精心设计提示词,这是获得高质量输出的关键。
- 实验参数:尝试不同的宽高比和设置,找到最适合您需求的配置。
- 批量生成:生成多张图像以增加获得理想结果的机会。
- 保存元数据:将提示词和时间戳与图像一起保存,以便追踪和复制成功的结果。
- 遵守使用政策:确保您的使用符合 Google 的内容政策和使用条款。
Veo 3.0 视频生成
VEO 3.0 是由 Google DeepMind 开发的最新先进视频生成模型。使用 VEO 3.0,您可以生成具有以下特点的视频:- 从文本和图像提示中生成的质量提升
- 语音,例如对话和配音
- 音频,例如音乐和声音效果
已知限制
目前 VEO 3.0 的参数固定,无法更改:- 分辨率: 720p(横屏)
- 帧率: 24fps
- 视频长度: 8秒
费率
使用 VEO 3.0 API 的费用是 $0.675/秒(Aihubmix 提供 10% 限时优惠)调用示例
VEO 3.0 目前仅支持 curl 命令调用,采用两步处理方式: 其中:sk-*** 换成你在 AiHubMix 生成的密钥。
返回示例
步骤 1 返回:最佳实践
- 耐心等待:视频生成通常需要几分钟,高峰期可能更长
- 检查状态:如果返回中没有
done: true,说明仍在处理中 - 保存操作 ID:确保保存步骤 1 返回的操作 ID 用于后续查询
- 遵守使用政策:确保您的使用符合 Google 的内容政策和使用条款
Veo 2.0 视频生成
VEO 2.0 是 Google 推出的先进视频生成 AI 模型,能够根据文本提示创建高质量、逼真的短视频。下面的指南将帮助您了解如何使用 VEO 2.0 API 生成视频,包括参数设置、模型选择和代码示例。模型参数
VEO 2.0 提供以下参数:- numberOfVideos: 要生成的视频数量,可选 1 或 2。默认值为 2。
- aspectRatio: 生成视频的宽高比。支持的值有 “16:9” 和 “9:16”。
- durationSeconds: 视频时长,可选 5 秒或 8 秒。默认值为 8 秒。
- personGeneration: 控制是否允许生成含人物的视频。支持以下值:
- “dont_allow”: 阻止生成含人物的视频。
- “allow_adult”: 允许生成含成人的视频,但不生成儿童视频。
费率
使用 VEO 2.0 API 的费用是 $0.35/秒调用示例
以下是使用 VEO 2.0 生成视频的 Python 调用示例:提示词技巧
创建有效的提示词对于获得理想的视频至关重要:- 描述清晰的场景、动作和氛围
- 指定拍摄风格(如全景、特写、跟踪镜头等)
- 描述光照条件(如阳光明媚、黄昏、室内灯光等)
- 指明主体对象及其动作(如”猫咪在阳光下睡觉”)
- 避免过于复杂的叙事或快速变化的场景
- 避免负面或违禁内容
最佳实践
- 简洁明了的提示词:使用清晰、具体的描述来指导视频生成。
- 耐心等待:视频生成需要 2-3 分钟,请耐心等待完成。
- 测试不同参数:尝试不同的宽高比和时长,找到最适合您需求的设置。
- 保存生成记录:将提示词与生成的视频一起记录,以便追踪成功的结果。
- 遵守使用政策:确保您的使用符合 Google 的内容政策和使用条款。
更新时间:2026-06-01