Imagen-Leitfaden
Imagen ist eine fortschrittliche Reihe von KI-Modellen zur Bildgenerierung, die von Google entwickelt wurden und in der Lage sind, hochwertige, realistische Bilder auf Basis von Textaufforderungen zu erstellen. Dieser Leitfaden hilft Ihnen zu verstehen, wie Sie die Imagen-API zur Bildgenerierung nutzen können, einschließlich Parametereinstellungen, Modellauswahl und Codebeispielen. Verfügbare Modelle:- imagen-4.0-ultra-generate-001
- imagen-4.0-generate-001
- imagen-4.0-fast-generate-001
- imagen-4.0-fast-generate-preview-06-06
- imagen-3.0-generate-002
Modellparameter
Imagen unterstützt derzeit nur englische Prompts und bietet die folgenden Parameter:- numberOfImages: Die Anzahl der zu generierenden Bilder, im Bereich von 1 bis 4 (inklusive). Der Standardwert ist 4.
imagen-4.0-ultra-generate-001kann nur 1 Bild auf einmal generieren.- aspectRatio: Ändert das Seitenverhältnis der generierten Bilder. Unterstützte Werte sind “1:1”, “3:4”, “4:3”, “9:16” und “16:9”. Der Standardwert ist “1:1”.
- personGeneration: Erlaubt dem Modell, Bilder von Personen zu generieren. Unterstützt die folgenden Werte:
- “DONT_ALLOW”: Verhindert die Generierung von Bildern, die Personen enthalten.
- “ALLOW_ADULT”: Generiert Bilder von Erwachsenen, jedoch nicht von Kindern. Dies ist der Standardwert.
Nutzungspreise
Die Kosten für die Nutzung der Imagen-API zur Bildgenerierung:- imagen-4-ultra: $0,06/Bild
- imagen-4: $0,04/Bild
- imagen-4-fast: $0,02/Bild
- imagen-3: $0,03/Bild
Beispiel für einen API-Aufruf
Hier ist ein Python-Beispiel zur Bildgenerierung mit Imagen 3.0:Tipps für Prompts
Das Erstellen effektiver Prompts ist entscheidend, um die gewünschten Bilder zu erhalten:- Verwenden Sie detaillierte Beschreibungen einschließlich Motiv, Stil, Beleuchtung, Blickwinkel usw.
- Geben Sie künstlerische Stile an (wie cinematic, photorealistic, Anime-Stil usw.).
- Fügen Sie technische Details hinzu (wie DSLR, hochauflösend, detailreich usw.).
- Vermeiden Sie negative oder verbotene Inhalte.
- Vermeiden Sie es, große Textmengen in Prompts einzufügen, verwenden Sie nur Schlüsselwörter für stabilere Ergebnisse.
Gemini-Bildgenerierung
Gemini bietet ebenfalls Fähigkeiten zur Bildgenerierung als Alternative an. Im Vergleich zu Imagen ist die Bildgenerierung von Gemini besser für Szenarien geeignet, die Kontextverständnis und logisches Schlussfolgern erfordern, anstatt das ultimative künstlerische Ausdrucksvermögen und die visuelle Qualität anzustreben. Hinweise:- Modell-ID:
gemini-2.5-flash-image-preview - Eingabe-/Ausgabepreise: Text: $0,3→$2,5/M Tokens; Bild: $0,3→$30/M Tokens
- Es müssen Parameter hinzugefügt werden, um neue Funktionen zu nutzen:
"modalities":["text","image"] - Bilder werden in Base64-Codierung übergeben und ausgegeben
- Standardhöhe für ausgegebene Bilder ist 1024 px
- Python-Aufrufe erfordern das neueste OpenAI SDK; führen Sie zuerst
pip install -U openaiaus - Weitere Informationen finden Sie in der offiziellen Gemini-Dokumentation
Text-zu-Bild-Generierung
Eingabe: Text Ausgabe: Text + Bild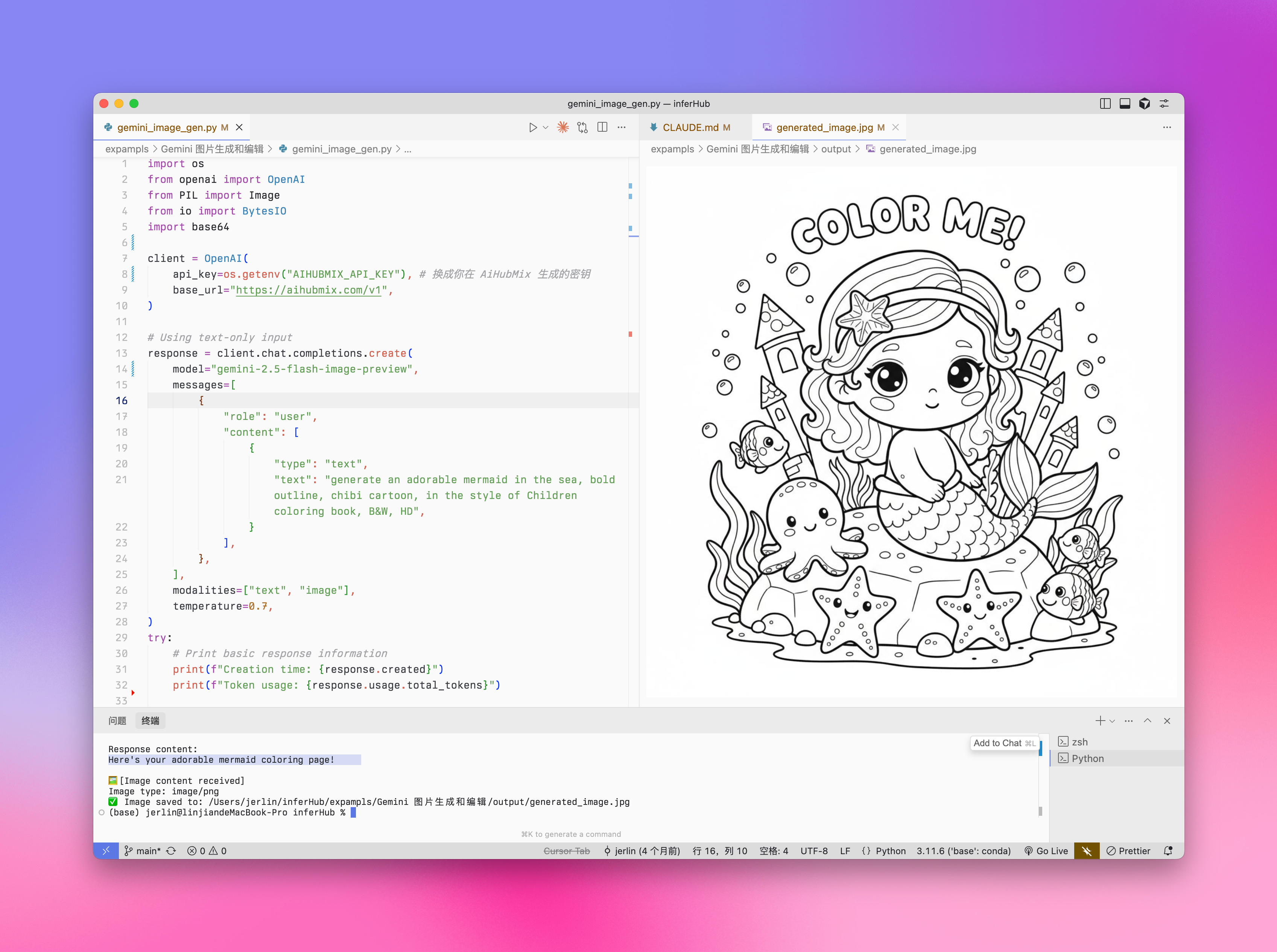
Bild bearbeiten
Eingabe: Text + BildAusgabe: Text + Bild
Das richtige Modell wählen
Wann Sie Gemini wählen sollten:
- Wenn Sie Weltwissen und Schlussfolgerungsfähigkeiten nutzen müssen, um kontextuell relevante Bilder zu generieren.
- Wenn Sie eine nahtlose Integration von Text und Bildern benötigen.
- Wenn Sie präzise visuelle Inhalte in lange Textsequenzen einbetten möchten.
- Wenn Sie Bilder im Dialog bearbeiten möchten, während der Kontext erhalten bleibt.
Wann Sie Imagen wählen sollten:
- Wenn Bildqualität, Fotorealismus, künstlerische Details oder spezifische Stile (wie Impressionismus, Anime) im Vordergrund stehen.
- Wenn Sie professionelle Bearbeitungsaufgaben ausführen, wie Hintergrundaktualisierungen von Produkten oder Bildvergrößerung.
- Wenn Sie Branding, Stil einbringen oder Logos und Produktdesigns generieren möchten.
Best Practices
- Prompts optimieren: Sorgfältig gestaltete Prompts sind der Schlüssel zu hochwertigen Ergebnissen.
- Mit Parametern experimentieren: Probieren Sie verschiedene Seitenverhältnisse und Einstellungen aus, um die für Ihre Bedürfnisse am besten geeignete Konfiguration zu finden.
- Batch-Generierung: Generieren Sie mehrere Bilder, um die Chance zu erhöhen, ideale Ergebnisse zu erhalten.
- Metadaten speichern: Speichern Sie Prompts und Zeitstempel zusammen mit den Bildern, um erfolgreiche Ergebnisse zu verfolgen und zu reproduzieren.
- Nutzungsrichtlinien einhalten: Stellen Sie sicher, dass Ihre Nutzung den Inhaltsrichtlinien und Nutzungsbedingungen von Google entspricht.
Veo 3.0 Videogenerierung
VEO 3.0 ist das neueste fortschrittliche Videogenerierungsmodell, das von Google DeepMind entwickelt wurde. Mit VEO 3.0 können Sie Videos mit den folgenden Funktionen generieren:- Verbesserte Qualität aus Text- und Bild-Prompts
- Sprache, wie Dialoge und Voiceovers
- Audio, wie Musik und Soundeffekte
Bekannte Einschränkungen
Derzeit sind die Parameter von VEO 3.0 fest und können nicht geändert werden:- Auflösung: 720p (Querformat)
- Bildrate: 24 fps
- Videolänge: 8 Sekunden
Preise
Die Kosten der VEO 3.0 API betragen $0,675/Sekunde (Aihubmix bietet einen zeitlich begrenzten Rabatt von 10 %)Anwendungsbeispiel
VEO 3.0 unterstützt derzeit nur curl-Befehlsaufrufe in einem zweistufigen Prozess: Hinweis:sk-*** ist Ihr auf AiHubMix generierter Key.
Antwortbeispiele
Antwort auf Schritt 1:Best Practices
- Geduld haben: Die Videogenerierung dauert in der Regel einige Minuten, in Spitzenzeiten länger
- Status prüfen: Wenn die Antwort kein
done: trueenthält, läuft die Verarbeitung noch - Operation-ID speichern: Stellen Sie sicher, dass Sie die in Schritt 1 zurückgegebene Operation-ID für nachfolgende Abfragen speichern
- Nutzungsrichtlinien einhalten: Stellen Sie sicher, dass Ihre Nutzung den Inhaltsrichtlinien und Nutzungsbedingungen von Google entspricht
Veo 2.0 Videogenerierung
VEO 2.0 ist ein fortschrittliches KI-Modell zur Videogenerierung, das von Google eingeführt wurde und in der Lage ist, hochwertige, realistische Kurzvideos auf Basis von Textaufforderungen zu erstellen. Dieser Abschnitt hilft Ihnen zu verstehen, wie Sie die VEO 2.0 API zur Videogenerierung verwenden können, einschließlich Parametereinstellungen, Modellauswahl und Codebeispielen.Modellparameter
VEO 2.0 bietet die folgenden Parameter:- numberOfVideos: Die Anzahl der zu generierenden Videos, Optionen sind 1 oder 2. Standard ist 2.
- aspectRatio: Das Seitenverhältnis der generierten Videos. Unterstützte Werte sind “16:9” und “9:16”.
- durationSeconds: Videodauer, Optionen sind 5 Sekunden oder 8 Sekunden. Standard sind 8 Sekunden.
- personGeneration: Steuert, ob Videos mit Personen zugelassen werden. Unterstützt die folgenden Werte:
- “dont_allow”: Verhindert die Generierung von Videos, die Personen enthalten.
- “allow_adult”: Erlaubt die Generierung von Videos mit Erwachsenen, jedoch nicht mit Kindern.
Preise
Die Kosten der VEO 2.0 API betragen $0,35/sAnwendungsbeispiel
Hier ist ein Python-Beispiel für die Verwendung von VEO 2.0 zur Videogenerierung:Tipps für Prompts
Das Erstellen effektiver Prompts ist entscheidend, um die gewünschten Videos zu erhalten:- Beschreiben Sie klare Szenen, Aktionen und Atmosphäre
- Geben Sie Aufnahmestile an (wie Panorama-, Nah-, Verfolgungsaufnahmen usw.)
- Beschreiben Sie Lichtverhältnisse (wie sonnig, Dämmerung, Innenbeleuchtung usw.)
- Geben Sie das Hauptmotiv und seine Aktionen an (z. B. “ein Kätzchen schläft in der Sonne”)
- Vermeiden Sie übermäßig komplexe Erzählungen oder schnell wechselnde Szenen
- Vermeiden Sie negative oder verbotene Inhalte
Best Practices
- Klare und präzise Prompts: Verwenden Sie klare, spezifische Beschreibungen, um die Videogenerierung zu steuern.
- Geduld ist entscheidend: Die Videogenerierung dauert 2–3 Minuten, bitte warten Sie auf den Abschluss.
- Verschiedene Parameter testen: Probieren Sie verschiedene Seitenverhältnisse und Dauern aus, um die für Ihre Bedürfnisse am besten geeigneten Einstellungen zu finden.
- Generierungsaufzeichnungen speichern: Notieren Sie die Prompts zusammen mit den generierten Videos, um erfolgreiche Ergebnisse nachvollziehen zu können.
- Nutzungsrichtlinien einhalten: Stellen Sie sicher, dass Ihre Nutzung den Inhaltsrichtlinien und Nutzungsbedingungen von Google entspricht.
Zuletzt aktualisiert: 2026-06-01