Lassen Sie einen Upstream-Ausfall nicht zu Ihrem eigenen Ausfall werden.AIHubMix bietet zwei Funktionen auf Key-Ebene. Konfigurieren Sie sie einmal in der Konsole, und sie werden ohne Änderungen am Client-Code wirksam:
- Model Mapping ist die Funktion auf Gateway-Ebene, die den Modell-Alias in einer Client-Anfrage in das tatsächliche Upstream-Modell umschreibt.
- Error Fallback ist die Funktion, bei der das Gateway beim Fehlschlagen des Primärmodells automatisch Ersatzmodelle in einer vorab konfigurierten Prioritätsreihenfolge ausprobiert, transparent für den Client.
AIHubMix unterstützt das Konfigurieren von Modellnamen-Mapping und Fehler-Fallback auf Key-Ebene und rechnet nach dem letztlich antwortenden Modell ab. Beides wird pro API Key auf der AIHubMix-Key-Verwaltungsseite konfiguriert.
Model name mapping und Fallback models on error des Panels:
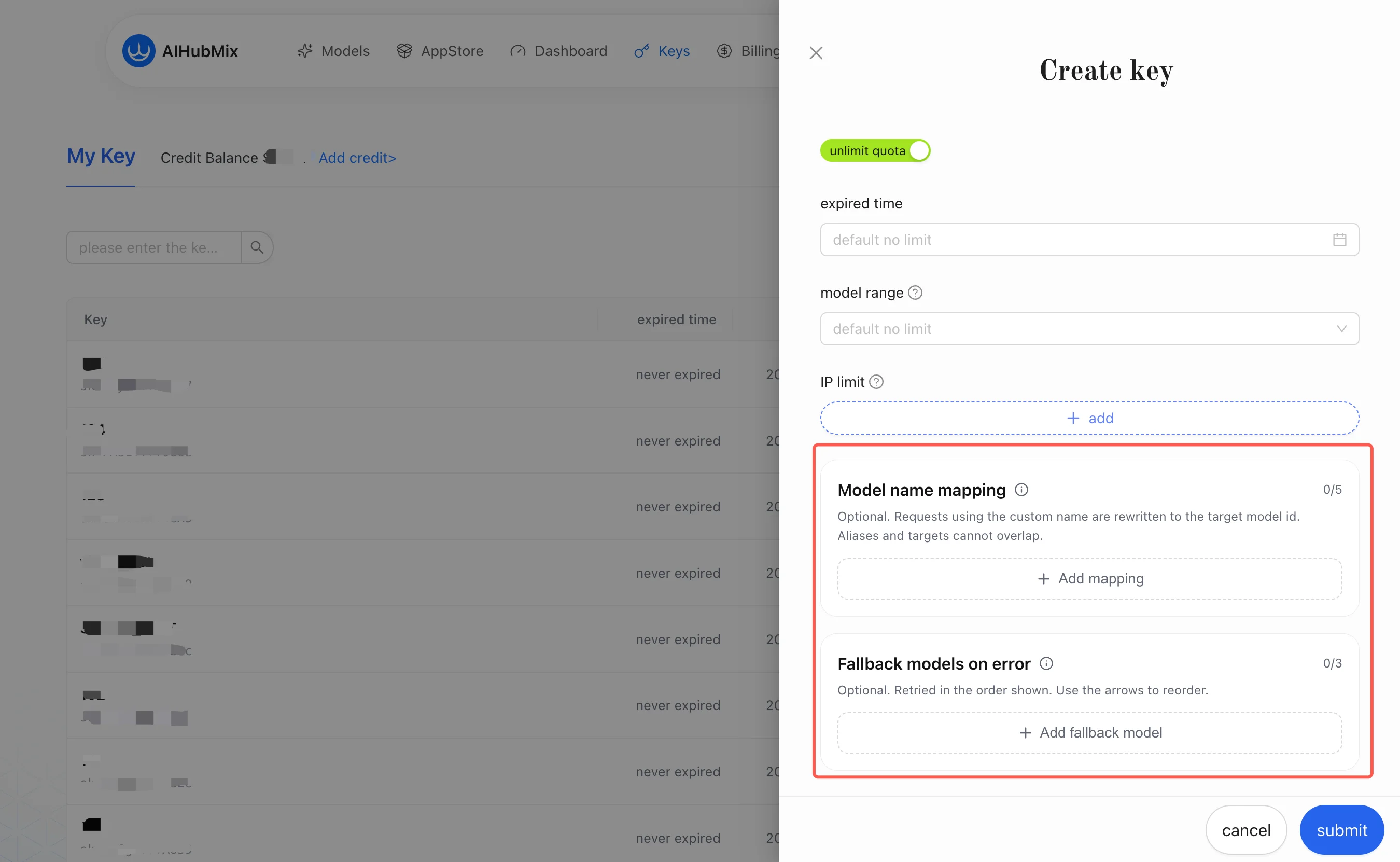
1. Mapping von Modellnamen
Das Mapping von Modellnamen behandelt die Diskrepanz zwischen “dem Modellnamen, den der Client sieht” und “dem Modell, das AIHubMix tatsächlich aufruft”. Es ist ein Alias-Umschreiben pro Key: Es schreibt den Alias in der Anfrage in das Zielmodell um, das Sie auf dem Key konfiguriert haben.Nachdem für das Zielmodell ein Kanal ausgewählt wurde, führt die Plattform intern ein weiteres Mapping auf Kanalebene zum tatsächlichen Upstream-Modell durch. Diese Ebene ist für Sie transparent und erfordert keine Konfiguration. Sie müssen sich nur um die Ebene “Alias → Zielmodell” kümmern.Beispiel:
Alle Modellnamen in der obigen Tabelle können auf der AIHubMix-Modellseite nachgeschlagen werden.Häufige Anwendungsfälle:
- Der Client schränkt das Format des Modellnamens ein. Zum Beispiel verlangt Claude Desktop Modellnamen im Claude-Stil (siehe Abschnitt 5).
- Einen kürzeren, stabileren Alias für eine komplexe Model ID festlegen.
- Die Client-Konfiguration unverändert lassen und das tatsächliche Modell im AIHubMix-Backend umstellen.
- Mehrere Plattformen teilen sich ein gemeinsames Benennungsschema für die Verbindung, leiten aber je nach Key zu unterschiedlichen Modellen weiter.
Zeichengenaue Übereinstimmung: Der vom Client gesendete Modellname muss zeichengenau mit der linken Seite des Mappings übereinstimmen. Zum Beispiel sindmy-gpt-5.5undmy-gpt-5-5zwei unterschiedliche Zeichenketten; stimmen sie nicht überein, wird das Mapping nicht getroffen.
2. Error Fallback
Der Error Fallback probiert Ersatzmodelle der Reihe nach aus, wenn das Primärmodell fehlschlägt. Es handelt sich nicht um ein Retry auf Client-Seite, sondern um einen Modellwechsel auf der AIHubMix-Gateway-Seite unter derselben Key-Konfiguration. Der Integrator muss bei jeder Anfrage keinen zusätzlichen Routing-Parameter übergeben. Sie können sich den Fallback als “Mapping auf eine geordnete Liste” vorstellen: Nachdem das Primärmodell fehlgeschlagen ist, geht das Gateway automatisch in der Liste weiter zum nächsten Ersatzmodell. Beispiel (auf demselben Key konfiguriert):2.1 Auslösebedingungen
Ein Fallback erfolgt nur, wenn alle folgenden Bedingungen erfüllt sind:- Für den Key ist eine nicht leere Liste von Ersatzmodellen konfiguriert.
- Jeder Kanal des Primärmodells wurde ausprobiert und ist mit einem “wiederholbaren Fehler” fehlgeschlagen (Kanäle ausgeschöpft).
- Die Antwort hat noch nicht begonnen zurückzukommen (das erste Byte / der Header wurde noch nicht an den Client gesendet).
- Der Fehler ist kein Fehler auf Key- / Benutzerebene (siehe die Vergleichstabelle in 2.2 unten).
2.2 Was einen Fallback auslöst und was nicht
Hinweis: “Key ungültig” bedeutet hier, dass Ihr eigener AIHubMix-Key ungültig ist, was keinen Fallback auslöst. Wenn der Key eines Upstream-Kanals defekt ist, wechselt das Gateway die Kanäle, und nachdem die Kanäle ausgeschöpft sind, kann dennoch ein Fallback erfolgen. Verwechseln Sie die beiden nicht.
2.3 Abrechnungsgrundlage
Abgerechnet nach dem letztlich antwortenden Modell. Wenn letztlich das Fallback-Modell antwortet, basieren Abrechnung, Fähigkeiten und Kontextlimits alle auf dem letztlich antwortenden Modell. Dieses Modell wird auch im Antwort-Header widergespiegelt (siehe Abschnitt 4).2.4 Regel für kostenlose Modelle
Ein kostenloses Modell kann nicht als Fallback-Option verwendet werden — ein kostenloses Modell kann nur das Primärmodell sein. Wenn Sie es in die Ersatzliste aufnehmen, wird es stillschweigend übersprungen und das Gateway fährt mit dem nächsten Eintrag fort. Nehmen Sie kostenlose Modelle also nicht in die Fallback-Liste auf.Typische Verwendung: Legen Sie ein kostenloses Modell als Primärmodell fest und setzen Sie kostenpflichtige Modelle in die Ersatzliste. Wenn das kostenlose Primärmodell auf ein Kontingent- / Ratenlimit trifft, erfolgt automatisch ein Fallback auf ein kostenpflichtiges Ersatzmodell. Im Normalfall sparen Sie Kosten, indem Sie das kostenlose Kontingent nutzen, und nach einer Ratenbegrenzung wechseln Sie nahtlos zu einem kostenpflichtigen Modell, um die Verfügbarkeit zu garantieren. Dies ist einer der häufigsten Anwendungsfälle des Fallbacks.
3. AIHubMix im Vergleich zu OpenRouter / LiteLLM
Model Mapping und Fallback sind keine neuen Konzepte; OpenRouter, LiteLLM und andere bieten ähnliche Funktionen. Was AIHubMix auszeichnet, ist der niedrigste Konfigurationsaufwand:
In einem Satz: Kein selbst gebautes Gateway, keine einzige Zeile Client-Code geändert — einmal auf dem Key konfigurieren und es wird wirksam.
4. Konfiguration und Verifizierung
4.1 Konfiguration
- Konfigurieren Sie das Alias-Mapping auf dem Key: Der Alias auf der linken Seite muss zeichengenau mit dem Modellnamen übereinstimmen, den der Client tatsächlich sendet.
- Konfigurieren Sie die Liste der Ersatzmodelle (eine geordnete Prioritätsliste) auf demselben Key.
- Die Ersatzliste sollte nur kostenpflichtige / verfügbare Modelle enthalten, keine kostenlosen Modelle (diese werden übersprungen).
- Modelle in der Ersatzliste müssen innerhalb des für den Key verfügbaren Modellbereichs liegen (Modelle außerhalb dieses Bereichs werden übersprungen).
4.2 Verifizierung – prüfen Sie zuerst die Antwort-Header, nicht die Logs
Bei der Fehlersuche schauen Sie nicht nur darauf, welches Modell der Client ausgewählt hat. Der verlässlichste, automatisierbare Weg ist das Auslesen der Antwort-Header:X-Aihubmix-Fallback: true: Bei dieser Anfrage ist ein Fallback aufgetreten (wird hinzugefügt, wenn das letztliche Modell ≠ dem Primärmodell ist).X-Aihubmix-Model: Das Modell, das bei dieser Anfrage tatsächlich geantwortet hat und entsprechend abgerechnet wurde.
5. Szenario eins Claude Desktop
Claude Desktop verbindet sich überGateway mit AIHubMix, ein typisches Szenario für das Mapping von Modellnamen.
Dieser Abschnitt setzt voraus, dass Sie die grundlegende Claude-Desktop-Integration bereits abgeschlossen haben. Die vollständigen Integrationsschritte (Download und Installation, Entwicklermodus, Gateway-Konfiguration, Auth-Schema usw.) finden Sie unter AIHubMix in Claude Desktop verbinden. Dieser Abschnitt behandelt nur die zusätzliche Konfiguration für Mapping und Fallback.
5.1 Warum ein Mapping nötig ist
Claude Desktop verbindet sich überGateway (Anthropic-kompatibel), und der Client schränkt Modellnamen auf den Claude-Stil ein, sodass Modellnamen das Präfix claude- verwenden müssen.
Dies erzeugt einen Konflikt: Auf der Client-Seite können nur Namen im claude--Stil geschrieben werden, aber was Sie eigentlich aufrufen möchten, sind gpt-5.5, gemini-3.1-pro-preview und Ähnliches. Genau dafür ist das Mapping von Modellnamen gemacht — der Client schreibt den Alias claude-g-p-t-5.5, und AIHubMix mappt ihn auf das tatsächliche gpt-5.5.
Claude Desktop verwendet die native Claude-Schnittstelle /v1/messages, sodass in den Beispielen in diesem Artikel sowohl das Mapping als auch der Fallback wirksam werden.
5.2 AIHubMix-Konfiguration für Mapping und Fallback
Beispielkonfiguration: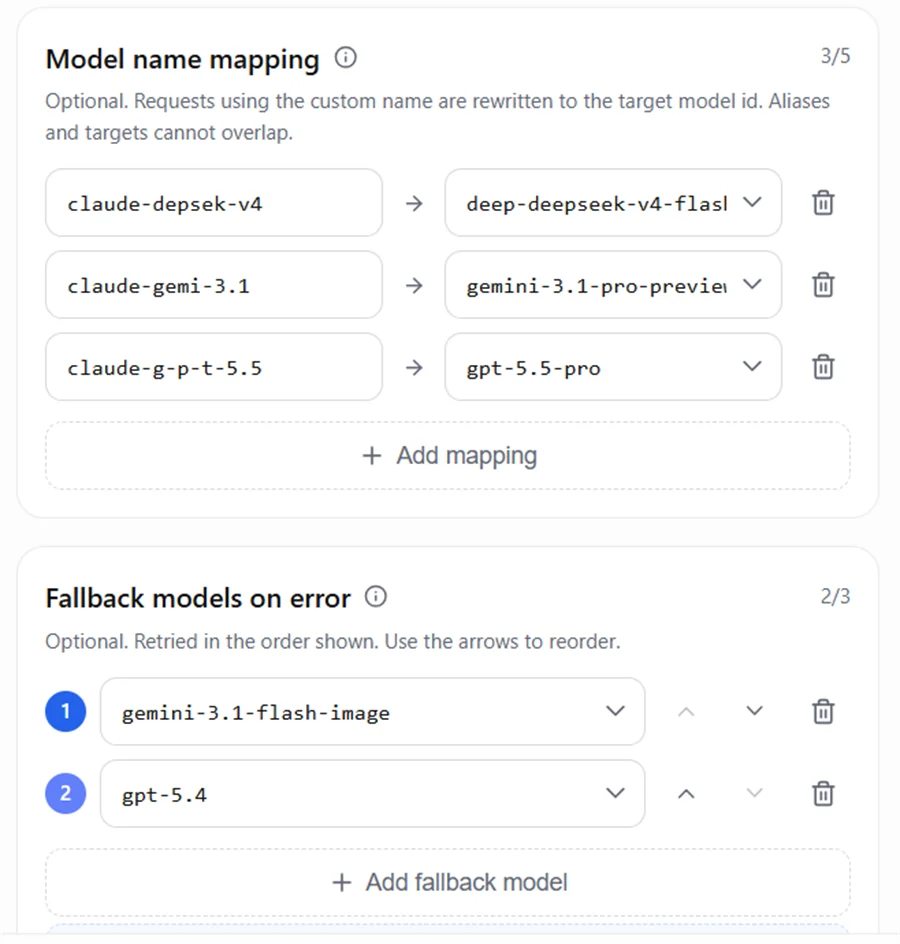
5.3 Claude-Desktop-Modellliste
Was Sie in derModel list von Claude Desktop konfigurieren, ist der Alias vor dem Mapping — also der Modellname, den Claude Desktop an AIHubMix sendet, nicht der tatsächliche Upstream-Modellname.
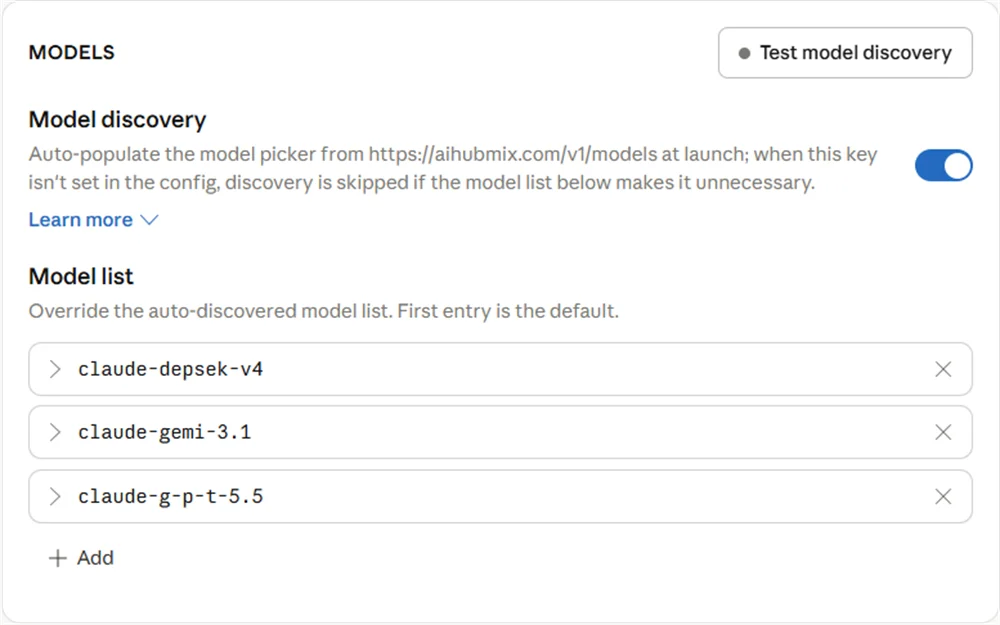
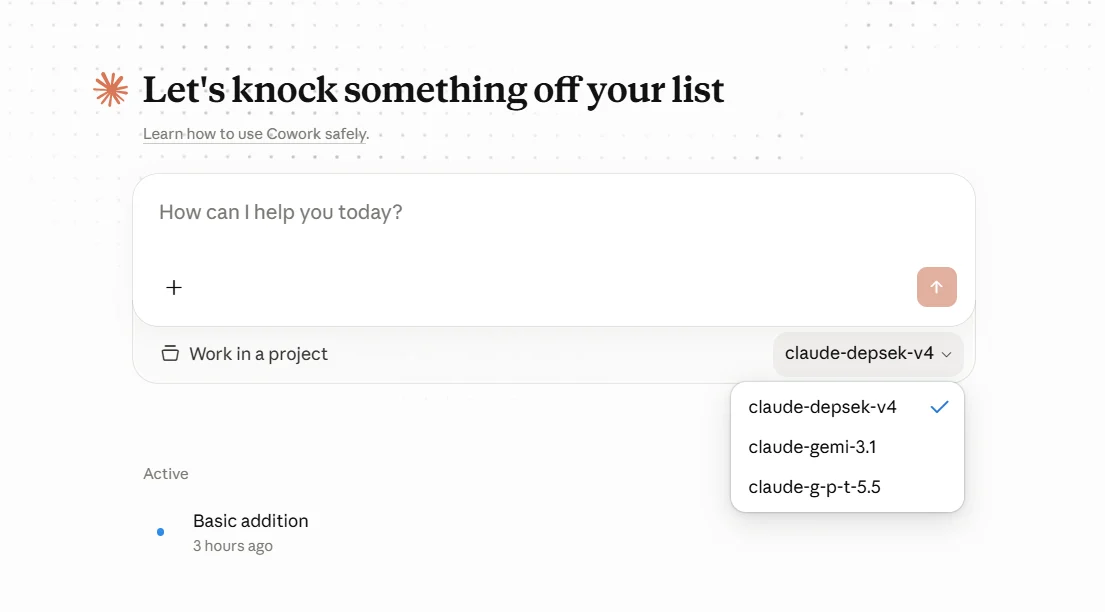
- Verwenden Sie das Präfix
claude-für dieModel ID. - Schreiben Sie nicht direkt echte Modellfamiliennamen wie
gpt,geminioderdeepseek; verwenden Sie Aliase wieg-p-t,gemi,depsek. - Die
Model IDmuss zeichengenau mit der linken Seite des AIHubMix-Mappings übereinstimmen, andernfalls trifft die Anfrage nicht das erwartete Mapping und fällt möglicherweise weiter auf das Error-Fallback-Modell durch.
6. Szenario zwei Multimodaler Fähigkeits-Fallback
Der multimodale Fähigkeits-Fallback behandelt das Szenario, in dem “das Primärmodell Text beantworten kann, aber den aktuellen Eingabetyp nicht unterstützt”. Zum Beispiel sendet der Client ein Bild oder Video, während das Primärmodell nur über Texteingabefähigkeit verfügt; AIHubMix kann weiter Modelle aus der Fallback-Liste ausprobieren, die die entsprechende Modalität unterstützen. Unten finden Sie einen realen Testpfad. Die Mapping- und Fallback-Konfiguration dieses Keys lautet wie folgt (siehe Screenshot unten). Der entscheidende Punkt ist, dass die Fallback-Liste sowohl ein Textmodell als auch ein Modell enthält, das Bildverständnis unterstützt:claude-g-l-m-4.6 angezeigt — ein Modell, das nur Texteingabe unterstützt. Der Benutzer lud einen Screenshot der AIHubMix-Modelllistenseite hoch und fragte “wofür ist diese Website”. Da die Anfrage ein Bild enthielt, konnte das Textmodell die Eingabe nicht direkt verarbeiten, was den Fallback auslöste.
Google AI Studio/gemini-3.1-flash-image war, der 2. Eintrag in der Fallback-Liste. Der 1. Eintrag, gpt-5.4, unterstützt diese Bildeingabe ebenfalls nicht und gab für diese Anfrage weiterhin einen wiederholbaren Fehler zurück, sodass das Gateway weiterging und bei gemini-3.1-flash-image landete, das Bildverständnis unterstützt.
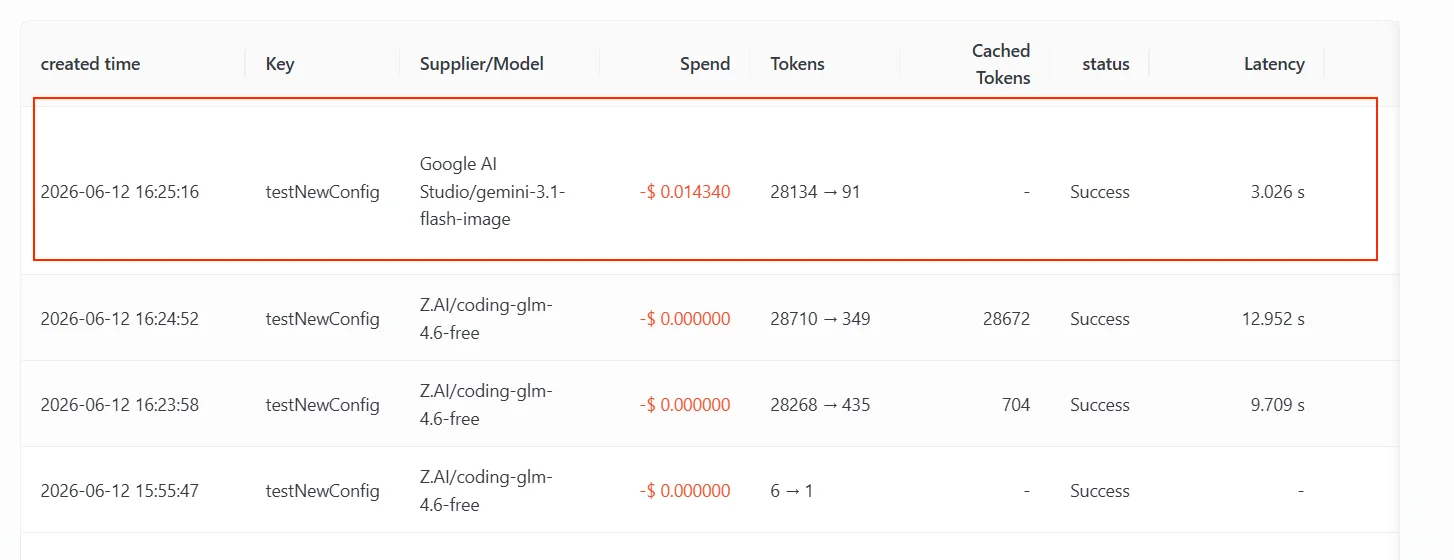
Seien Sie sich über den Auslösegrund im Klaren: Der Fallback erfolgt hier, weil der Upstream für diese Bildeingabe einen wiederholbaren Fehler zurückgab und die Kanäle des Primärmodells ausgeschöpft waren — es ist derselbe Fallback-Mechanismus wie “Fallback, nachdem das Primärmodell ratenbegrenzt wurde”, nur durch einen anderen Fehlertyp ausgelöst (Ersteres ist eine nicht unterstützte Eingabe, Letzteres ist ein Kontingent- / Ratenlimit).
Unterscheiden Sie Verständnis von Generierung: Dies bezieht sich auf den Fallback beim Bild- / Videoverständnis, nicht auf die Bilderzeugung oder Videoerzeugung. Eine Chat-Anfrage verwandelt sich nicht automatisch in einen Generierungs-Endpunkt; um das Zeichnen oder die Videoerzeugung zu testen, sollten Sie den entsprechenden Generierungs-Endpunkt und das entsprechende Modell verwenden. Die Fähigkeiten eines Modells werden durch die Input Modalities bestimmt, die aktuell auf der AIHubMix-Modellseite markiert sind.
7. Szenario drei Fallback bei kostenlosem Modell
Dies ist einer der häufigsten Anwendungsfälle des Fallbacks: Legen Sie ein kostenloses Modell als Primärmodell fest und setzen Sie kostenpflichtige Modelle in die Ersatzliste. Im Normalfall laufen alle Anfragen über das kostenlose Modell und sparen Kosten; sobald das kostenlose Primärmodell auf ein Kontingent- / Ratenlimit trifft, fällt das Gateway automatisch auf ein kostenpflichtiges Ersatzmodell zurück und stellt sicher, dass der Dienst nicht unterbrochen wird. Beispiel-Key-Konfiguration:- Solange das kostenlose Kontingent noch ausreicht, wird die Anfrage vom Primärmodell
coding-glm-5.2-freebeantwortet und als kostenlos abgerechnet. - Nachdem das kostenlose Primärmodell ratenbegrenzt wurde, erfolgt automatisch ein Fallback auf
gpt-5.4; wenngpt-5.4ebenfalls nicht verfügbar ist, wird anschließendgemini-3.1-pro-previewausprobiert. - Welches Modell auch immer letztlich antwortet, ist dasjenige, das Ihnen in Rechnung gestellt wird (siehe 2.3).
Hinweis: Ein kostenloses Modell kann nur das Primärmodell sein und kann nicht in die Fallback-Liste aufgenommen werden (falls doch, wird es übersprungen; siehe 2.4). Der korrekte Weg, einen “Fallback bei kostenlosem Modell” umzusetzen, ist also: kostenlos als Primärmodell, kostenpflichtig als Ersatz, nicht umgekehrt.Die Verifizierung erfolgt erneut durch das Auslesen der Antwort-Header: Wenn ein Fallback auftritt, wird
X-Aihubmix-Fallback: true zurückgegeben, und X-Aihubmix-Model zeigt das letztlich antwortende Modell an (siehe Abschnitt 4).
8. Unterstützte Endpunkte
Model Mapping und Error Fallback unterstützen derzeit die folgenden Schnittstellenkategorien:
Wichtige Punkte:
- Model Mapping und Error Fallback unterstützen drei Schnittstellenkategorien: OpenAI-kompatible Schnittstellen, natives Claude
/v1/messagesund OpenAI Responses/v1/responses. - Andere native Passthrough-Schnittstellen (natives Gemini, Ideogram, Video, TTS, Stability, OCR, Predictions usw.), Passthrough für einen bestimmten Kanal sowie Schnittstellen für den Abruf nach Ressourcen-ID / Dateityp werden noch nicht unterstützt.
- Claude Desktop verwendet das native Claude
/v1/messages, sodass in den Beispielen in diesem Artikel sowohl das Mapping als auch der Fallback wirksam werden.
9. FAQ
F: Was soll ich tun, wenn Claude Desktop “model not found” anzeigt? A: Prüfen Sie, ob dieModel ID in Claude Desktop zeichengenau mit der linken Seite des AIHubMix-Mappings übereinstimmt; stimmen sie nicht überein, wird das Mapping nicht getroffen.
F: Wirkt sich der Fallback auf die Abrechnung aus?
A: Abgerechnet wird nach dem letztlich antwortenden Modell. Welches Modell auch immer letztlich antwortet, Ihnen werden die Kosten auf Grundlage des Preises, der Fähigkeiten und der Kontextlimits dieses Modells berechnet.
F: Wie bestätige ich, ob diese Anfrage tatsächlich einen Fallback verwendet hat?
A: Schauen Sie sich die Antwort-Header X-Aihubmix-Fallback: true (ein Fallback ist aufgetreten) und X-Aihubmix-Model (das letztlich antwortende Modell) an; siehe Abschnitt 4.
F: Welche Fehler lösen einen Fallback aus und welche nicht?
A: Siehe die Vergleichstabelle in 2.2. Kurz gesagt: Ein Fallback erfolgt nur bei einem wiederholbaren Upstream-Fehler, ausgeschöpften Kanälen und einer noch nicht begonnenen Antwort; bei einem bestimmten Kanal, einer bereits begonnenen Antwort, einer Client-Trennung / einem Timeout sowie bei Fehlern auf Key- / Benutzerebene erfolgt kein Fallback.
F: Kann ein kostenloses Modell in die Fallback-Liste aufgenommen werden?
A: Nein, es wird übersprungen. Ein kostenloses Modell kann nur das Primärmodell sein.
F: Worin unterscheidet sich das vom Modell-Alias / Fallback von OpenRouter / LiteLLM?
A: AIHubMix ist auf Key-Ebene und plattformverwaltet — einmal in der Konsole konfigurieren und es wird wirksam, ohne Änderungen am Client-Code und ohne selbst gebautes Gateway. Siehe Abschnitt 3 für Details.
Verwandte Ressourcen
- AIHubMix in Claude Desktop verbinden: vollständige Schritte für Entwicklermodus, Gateway-Konfiguration, Auth-Schema und mehr.
- AIHubMix-Modellseite: Modellnamen, Preise und
Input Modalitiesnachschlagen. - AIHubMix in LiteLLM verbinden: eine Referenz für den Fall, dass Sie ein selbst gebautes Gateway + Modell-Mapping / Fallback benötigen.