Die Mindestschwelle an cachebaren Token unterscheidet sich je nach Claude-Modell (512 / 1.024 / 2.048 / 4.096) und verläuft nicht proportional zur Versionsnummer: Claude Opus 4.8 = 1.024, Claude Opus 4.7 = 2.048, Claude Opus 4.6 / 4.5 und Claude Haiku 4.5 = 4.096. Die vollständige Staffelung finden Sie unten unter „Cache-Einschränkungen”. Inhalt unterhalb der Schwelle wird auch mit gesetztem
cache_control nicht in den Cache geschrieben und löst keinen Fehler aus.cache_control-Block:
cache_control gecached. Damit kann dieser umfangreiche Text über mehrere API-Aufrufe hinweg wiederverwendet werden, ohne ihn jedes Mal neu zu verarbeiten. Durch Änderung lediglich der User-Nachricht können verschiedene Fragen zum Buch gestellt werden, während der gecachte Inhalt weiterverwendet wird – das beschleunigt die Antworten und steigert die Effizienz.
So funktioniert Prompt-Caching
Wenn Sie eine Anfrage mit aktiviertem Prompt-Caching senden:- Das System prüft, ob ein Prompt-Präfix bis zu einem bestimmten Cache-Breakpoint bereits aus einer kürzlichen Abfrage gecached ist.
- Falls gefunden, wird die gecachte Version verwendet, wodurch Verarbeitungszeit und Kosten sinken.
- Andernfalls wird der gesamte Prompt verarbeitet und das Präfix gecached, sobald die Antwort beginnt. Besonders nützlich für:
- Prompts mit vielen Beispielen
- Große Kontext- oder Hintergrundinformationen
- Wiederkehrende Aufgaben mit gleichbleibenden Anweisungen
- Lange Multi-Turn-Konversationen
Häufiger Fehler: Cache wird geschrieben, aber „nur geschrieben, nie gelesen”
Das häufigste Fehlerszenario: In jeder Runde istcache_creation_input_tokens groß (es wird ständig in den Cache geschrieben), aber cache_read_input_tokens bleibt stets 0 (es wird nie gelesen) – das bedeutet, dass überhaupt nichts gespart wird.
Es gibt nur eine Ursache: Der Inhalt vor dem Cache-Breakpoint (cache_control) hat sich zwischen zwei Requests verändert. Ein Cache-Hit setzt voraus, dass der Breakpoint und der gesamte Inhalt davor (in der Reihenfolge tools → system → messages) Byte für Byte exakt identisch sind; sobald sich auch nur ein einziges Zeichen vor dem Breakpoint ändert, wird das gesamte Präfix-Caching verworfen und neu geschrieben.
❌ Falsch: Die in jeder Runde wechselnde Frage vor dem Breakpoint platzieren
✅ Richtig: Großes Dokument ganz nach vorn + Breakpoint + Frage ganz nach hinten
Messvergleich (claude-opus-4-6, wenige Sekunden zwischen den beiden Aufrufen)
Kernpunkte:
- Den unveränderlichen großen Block (Referenzdokument, langer Kontext) ganz an den Anfang der
user-Nachricht inmessagessetzen,cache_controlan dessen Ende markieren – an diesem Inhalt darf kein einziges Zeichen geändert werden; - Die in jeder Runde wechselnde Frage/Anweisung nach den Breakpoint setzen (in derselben
user-Nachricht nach dem großen Dokument oder in nachfolgenden Nachrichten); in Multi-Turn-Konversationen nur nach hinten anfügen und nicht zurückgehen, um den Verlauf zu ändern; - Bei aktiviertem
thinkingmüssen die Thinking-Blöcke aus früheren Assistant-Turns unverändert zurückgesendet werden, sonst bricht das Präfix ebenfalls (siehe unten „Was nicht gecached werden kann”); - Liegt ein Block unter der Mindest-Cache-Schwelle (je nach Modell zwischen 512 und 4.096 Token, siehe unten „Cache-Einschränkungen”), wird er auch mit gesetztem
cache_controlnicht in den Cache geschrieben – das ist erwartetes Verhalten.
Preisgestaltung
Prompt-Caching führt eine neue Preisstruktur ein. Die Tabelle zeigt den Preis pro Million Token für jedes unterstützte Modell:
Hinweis:
- 5-Minuten-Cache-Write-Token kosten das 1,25-Fache der Basis-Input-Token-Preise
- 1-Stunden-Cache-Write-Token kosten das 2-Fache der Basis-Input-Token-Preise
- Cache-Read-Token kosten das 0,1-Fache der Basis-Input-Token-Preise
- Reguläre Input- und Output-Token werden zu den Standardpreisen der Plattform abgerechnet
So implementieren Sie Prompt-Caching
Unterstützte Modelle
Alle Modelle der Anthropic-Claude-Reihe unterstützen Prompt-Caching, darunter die aktuellen Modelle Claude Opus 4.8 / 4.7 / 4.6 / 4.5, Claude Sonnet 5 / 4.6 / 4.5, Claude Haiku 4.5 und Claude Fable 5 sowie die früheren Modelle Claude Opus 4, Sonnet 4, Sonnet 3.7, Sonnet 3.5, Haiku 3.5, Haiku 3 und Opus 3. Die Mindestschwelle an cachebaren Token je Modell finden Sie unten unter „Cache-Einschränkungen”.Automatisches Caching (cache_control auf oberster Ebene)
Eincache_control-Feld auf der obersten Ebene des Request-Bodys aktiviert automatisches Caching: Das System wendet den Cache-Breakpoint automatisch auf den letzten cachebaren Block an und verschiebt ihn mit wachsender Konversation automatisch nach vorn – geeignet für rollierendes Caching in Multi-Turn-Konversationen. Der automatische Breakpoint belegt einen der 4 Breakpoint-Slots und kann mit expliziten Breakpoints auf Block-Ebene kombiniert werden. Amazon Bedrock unterstützt automatisches Caching nicht.
Aufbau Ihres Prompts
Platzieren Sie statischen Inhalt (Tool-Definitionen, System-Anweisungen, Kontext, Beispiele) am Anfang des Prompts. Markieren Sie das Ende des wiederverwendbaren Inhalts mit dem Parametercache_control.
Cache-Präfixe werden in folgender Reihenfolge erstellt: tools, system, dann messages.
Mit dem Parameter cache_control können Sie bis zu 4 Cache-Breakpoints definieren und so unterschiedliche wiederverwendbare Abschnitte separat cachen. Das System prüft an jedem Breakpoint automatisch auf Cache-Hits an vorherigen Positionen und verwendet das längste passende Präfix.
Cache-Einschränkungen
Die Mindestlänge eines cachebaren Prompts richtet sich nach dem Modell und verläuft nicht proportional zur Versionsnummer:
Kürzere Prompts können nicht gecached werden, auch wenn sie mit
cache_control markiert sind. Anfragen mit weniger Token werden ohne Caching verarbeitet. Ob ein Prompt gecached wurde, sehen Sie an den Usage-Feldern der Antwort.
Bei gleichzeitigen Requests beachten Sie: Ein Cache-Eintrag wird erst verfügbar, wenn die erste Antwort begonnen hat. Wenn Sie Cache-Hits für parallele Requests benötigen, warten Sie auf die erste Antwort, bevor Sie weitere Requests senden.
Derzeit unterstützte Cache-Lebensdauern:
- „ephemeral”: Standard-Lebensdauer 5 Minuten
- 1-Stunden-Cache: Setzen Sie
"ttl": "1h"incache_control, für Szenarien mit längerer Cache-Dauer
1-Stunden-Cache-Dauer
Für Szenarien, die längere Cache-Dauer erfordern, bieten wir eine 1-Stunden-Cache-Option an. Geben Sie dazu einfachttl in der cache_control-Definition an; ein zusätzlicher Request-Header ist nicht erforderlich:
Wann der 1-Stunden-Cache verwendet werden sollte
Der 1-Stunden-Cache eignet sich besonders für:- Batch-Verarbeitung: Bearbeitung großer Mengen an Requests mit gemeinsamen Präfixen
- Langläufige Sessions: Konversationen, die Kontext über längere Zeit benötigen
- Analyse großer Dokumente: Verschiedene Analysen am selben Dokument
- Code-Base-Q&A: Mehrere Abfragen über längere Zeiträume hinweg
Verschiedene TTLs mischen
Innerhalb derselben Anfrage können Sie verschiedene Cache-Dauern mischen:Was gecached werden kann
Jeder Block im Request kann mitcache_control zum Caching markiert werden. Das umfasst:
- Tools: Tool-Definitionen im
tools-Array - System-Nachrichten: Content-Blöcke im
system-Array - Nachrichten: Content-Blöcke im
messages.content-Array, sowohl für User- als auch für Assistant-Turns - Bilder und Dokumente: Content-Blöcke im
messages.content-Array, in User-Turns - Tool-Use und Tool-Results: Content-Blöcke im
messages.content-Array in User- und Assistant-Turns
cache_control markiert werden, um diesen Teil der Anfrage zu cachen.
Was nicht gecached werden kann
Die meisten Blöcke können gecached werden, mit folgenden Ausnahmen:- Thinking-Blöcke können nicht direkt mit
cache_controlgecached werden. Sie KÖNNEN jedoch zusammen mit anderem Inhalt gecached werden, wenn sie in vorangegangenen Assistant-Turns auftauchen. So gecached zählen sie beim Lesen aus dem Cache als Input-Token. - Sub-Content-Blöcke (wie Citations) können nicht direkt gecached werden. Cachen Sie stattdessen den übergeordneten Block.
- Leere Text-Blöcke können nicht gecached werden.
Cache-Performance überwachen
Überwachen Sie die Cache-Performance über folgende API-Antwortfelder imusage-Objekt (oder im message_start-Event beim Streaming):
cache_creation_input_tokens: Anzahl der Token, die beim Erstellen eines neuen Eintrags in den Cache geschrieben wurden.cache_read_input_tokens: Anzahl der Token, die aus dem Cache für diesen Request gelesen wurden.input_tokens: Anzahl der Input-Token, die nicht aus dem Cache gelesen oder zum Erstellen eines Caches verwendet wurden.
Best Practices für effektives Caching
Optimieren Sie die Prompt-Caching-Performance:- Cachen Sie stabilen, wiederverwendbaren Inhalt wie System-Anweisungen, Hintergrundinformationen, große Kontexte oder häufig genutzte Tool-Definitionen.
- Platzieren Sie gecachte Inhalte am Anfang des Prompts.
- Setzen Sie Cache-Breakpoints gezielt, um verschiedene cachefähige Präfixabschnitte zu trennen.
- Analysieren Sie regelmäßig Cache-Hit-Raten und passen Sie Ihre Strategie an.
- Für langfristige Inhalte sollten Sie den 1-Stunden-Cache für bessere Kosteneffizienz erwägen.
Optimierung für verschiedene Anwendungsfälle
Passen Sie die Prompt-Caching-Strategie an Ihr Szenario an:- Konversationsagenten: Kosten und Latenz für längere Konversationen senken, besonders bei langen Anweisungen oder hochgeladenen Dokumenten.
- Coding-Assistenten: Autovervollständigung und Code-Base-Q&A verbessern, indem relevante Abschnitte oder eine zusammengefasste Version der Codebasis im Prompt verbleiben.
- Verarbeitung langer Dokumente: Komplette Langtexte inklusive Bilder im Prompt einbinden, ohne dass die Antwortlatenz steigt.
- Ausführliche Anweisungssets: Lange Listen von Anweisungen, Prozeduren und Beispielen teilen, um Claudes Antworten feinzutunen. Entwickler fügen üblicherweise ein bis zwei Beispiele in den Prompt ein, aber mit Prompt-Caching erzielen Sie mit 20+ vielfältigen Beispielen hoher Qualität noch bessere Ergebnisse.
- Agentische Tool-Nutzung: Verbessert Szenarien mit mehrfachen Tool-Aufrufen und iterativen Code-Änderungen, bei denen jeder Schritt einen neuen API-Aufruf erfordert.
- „Talk to” Bücher, Papers, Dokumentationen, Podcast-Transkripte und andere Langtextinhalte: Bringen Sie eine Wissensbasis zum Leben, indem Sie ganze Dokumente in den Prompt einbetten und Nutzer Fragen stellen lassen.
Häufige Probleme beheben
Bei unerwartetem Verhalten:- Stellen Sie sicher, dass die gecachten Abschnitte identisch und an denselben Stellen mit
cache_controlmarkiert sind. - Prüfen Sie, ob die Aufrufe innerhalb der Cache-Lebensdauer (5 Minuten oder 1 Stunde) erfolgen.
- Verifizieren Sie, dass
tool_choiceund die Bildverwendung zwischen Aufrufen konsistent bleiben. - Stellen Sie sicher, dass Sie mindestens die Mindestanzahl an Token cachen.
- Das System versucht, vorherig gecachten Inhalt an Positionen vor einem Cache-Breakpoint zu nutzen; bei Anfragen mit sehr langen Listen von Content-Blöcken können Sie einen zusätzlichen
cache_control-Parameter setzen, um den Cache-Lookup explizit zu erzwingen.
Cache-Speicherung und -Sharing
- Organisationsisolierung: Caches sind zwischen Organisationen isoliert. Verschiedene Organisationen teilen sich nie einen Cache, selbst bei identischen Prompts.
- Exakter Match: Cache-Hits erfordern zu 100 % identische Prompt-Segmente, einschließlich aller Texte und Bilder bis einschließlich des mit
cache_controlmarkierten Blocks. Derselbe Block muss bei Cache-Lese- und Schreibvorgängen mitcache_controlmarkiert sein. - Output-Token-Generierung: Prompt-Caching beeinflusst die Output-Token-Generierung nicht. Die Antwort ist identisch mit der ohne Prompt-Caching.
Claude-Caching in Clients / Plattformen aktivieren
Viele Clients bieten in ihrer Oberfläche keine Möglichkeit,cache_control direkt einzutragen, sondern injizieren es über eigenen „Syntactic Sugar” oder Schalter für Sie. Die zugrunde liegenden Regeln sind exakt dieselben wie oben – das gecachte Präfix muss in jeder Runde Zeichen für Zeichen unverändert bleiben, und der wechselnde Inhalt gehört hinter den Cache-Breakpoint, sonst kommt es zu „nur schreiben, nie lesen” (siehe oben „Häufiger Fehler”).
Dify (über das Aihubmix-Plugin)
Das Dify-Plugin von Aihubmix übernimmt den Syntactic Sugar des offiziellen Anthropic-Plugins. In zwei Schritten aktivieren:- Umschließen Sie den zu cachenden Prompt (unveränderlicher System-Prompt / langer Kontext) mit
<cache>…</cache>; das Plugin wandelt diese Stelle automatisch in einencache_control-Breakpoint um; - Setzen Sie in den Modellparametern den Wert „Automatische Cache-Schwelle für große Nachrichten” auf eine positive Ganzzahl: Erst wenn der Inhalt diese Token-Schwelle erreicht, wird tatsächlich in den Cache geschrieben (weiterhin gebunden an die unten unter „Cache-Einschränkungen” genannte Mindest-Cache-Größe, 4096 Token für Opus 4.5/4.6 und Haiku 4.5); 0 oder leer schaltet die Funktion ab.
Cherry Studio
Wenn Cherry Studio Claude über Aihubmix aufruft, ist Caching standardmäßig deaktiviert („Cache Token Threshold” ist standardmäßig0); es muss in den „API Settings” des Anbieters aktiviert werden.
- Klicken Sie auf das Zahnrad rechts neben dem Anbieternamen Aihubmix, um die „API Settings” zu öffnen:
- Konfigurieren Sie die folgenden drei Optionen; der Client injiziert daraufhin automatisch
cache_controlfür Claude:
- Cache Token Threshold: Erst wenn der Inhalt diese Token-Anzahl überschreitet, wird ein Cache-Breakpoint injiziert (eine positive Zahl aktiviert, 0 oder leer deaktiviert);
- Cache System Message: Aktiviert setzt einen Cache-Breakpoint auf die
system-Nachricht (geeignet zum Cachen eines festen, langen System-Prompts); - Cache Last N Messages: Setzt einen Cache-Breakpoint auf die letzten N Nachrichten (geeignet für rollierendes Caching in Multi-Turn-Konversationen).
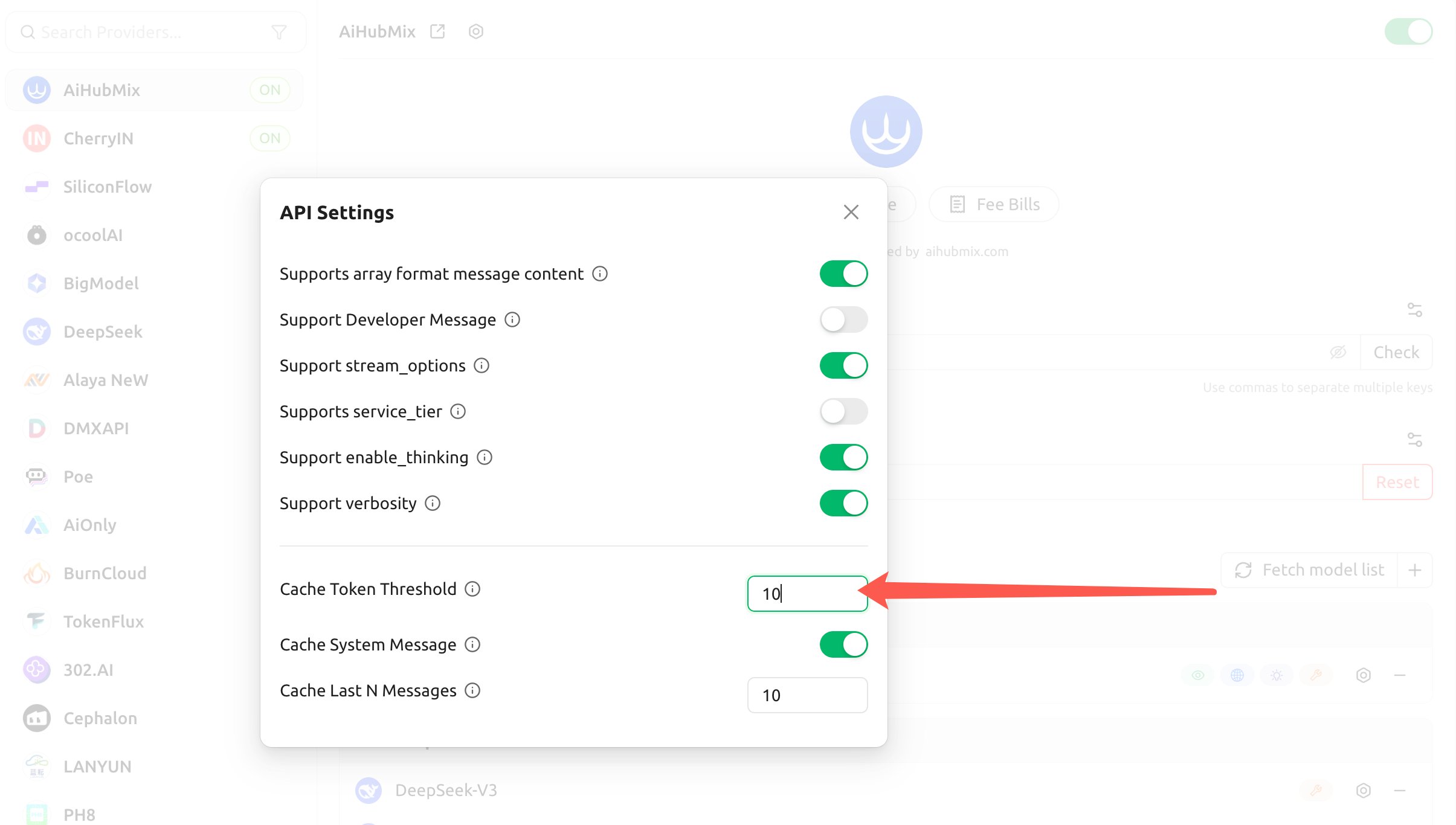
Die obigen Schwellenwerte bestimmen nur, „wann der Client einen Breakpoint injiziert”, und ändern nichts an Anthropics Mindest-Cache-Anforderung: Tatsächlich geschrieben wird erst, wenn der gecachte Inhalt die Mindest-Cache-Token erreicht (4096 für Opus 4.5/4.6 und Haiku 4.5). Wird in jeder Runde wechselnder Inhalt (wie rotierende Anweisungen) in den gecachten System-Prompt aufgenommen, kommt es ebenfalls zu „nur schreiben, nie lesen”.
Häufig gestellte Fragen (FAQ)
Warum wird der Cache geschrieben (cache_creation_input_tokens ist groß), aber nie gelesen (cache_read_input_tokens ist 0)?
Weil sich der Inhalt vor dem Cache-Breakpoint (cache_control) zwischen zwei Requests verändert hat. Ein Hit setzt voraus, dass der Breakpoint und der gesamte Inhalt davor Byte für Byte identisch sind; sobald in jeder Runde wechselnder Inhalt vor dem Breakpoint steht, wird das gesamte Präfix-Caching verworfen und in jeder Runde neu geschrieben. Setzen Sie den festen Inhalt ganz nach vorn und den wechselnden Inhalt hinter den Breakpoint – Details siehe oben „Häufiger Fehler”.
Wie viele Token sind mindestens für Caching nötig?
Inhalt unterhalb der Mindest-Cache-Länge wird auch mit gesetztemcache_control nicht gecached. Für Claude Opus 4.5/4.6 und Haiku 4.5 sind es 4096 Token; die übrigen Claude-Modelle liegen meist bei 1024 Token, Haiku 3/3.5 bei 2048 Token. Details siehe oben „Cache-Einschränkungen”.
Wie lange ist der Cache gültig? Lässt sich das auf 1 Stunde ändern?
Standardmäßig 5 Minuten, bei jedem Hit ohne Zusatzkosten aufgefrischt. Wenn Sie länger brauchen, setzen Sie incache_control "ttl": "1h"; ein zusätzlicher Request-Header ist nicht erforderlich. Cache-Writes im 1-Stunden-Cache werden mit dem 2-Fachen des Basis-Inputpreises abgerechnet. Details siehe oben „1-Stunden-Cache-Dauer”.
Wie aktiviere ich Caching in Dify / Cherry Studio?
Diese Clients tragencache_control nicht direkt ein: In Dify umschließen Sie den zu cachenden Inhalt mit <cache>…</cache> und setzen die „Automatische Cache-Schwelle für große Nachrichten”; in Cherry Studio konfigurieren Sie in den „API Settings” „Cache Token Threshold / Cache System Message / Cache Last N Messages”. Details siehe oben „Claude-Caching in Clients / Plattformen aktivieren”.
Unterstützung in verschiedenen Modellen
- Ob Prompt-Caching unterstützt wird, hängt vom Modell selbst ab.
- Wenn das Modell Caching nativ unterstützt, ohne explizite Parameter zu benötigen, kann es über OpenAI-kompatibles Forwarding unterstützt werden.
- OpenAI unterstützt Prompt-Caching standardmäßig; es greift automatisch (Präfix ≥1024 Token). Bei Modellen vor GPT-5.6 werden Cache-Writes nicht separat abgerechnet, und der Cache wird nach 5–10 Minuten Inaktivität automatisch geleert; ab GPT-5.6 werden Cache-Writes mit dem 1,25-Fachen des Inputpreises abgerechnet, Cache-Reads mit dem 0,1-Fachen, der Cache bleibt mindestens 30 Minuten erhalten, und explizite Cache-Breakpoints werden unterstützt. Details siehe GPT Prompt Caching.
- Claude erfordert die native Deklaration
cache_control: { type: "ephemeral" }. Cache-Raten betragen das 1,25-Fache (5 Minuten) oder 2-Fache (1 Stunde) der Standard-Eingabekosten; das Lesen gecachter Token kostet das 0,1-Fache des Normalpreises, mit 5-Minuten- oder 1-Stunden-Lebenszyklus. Details - Deepseek V3 und R1 unterstützen Caching nativ. Cache-Rate entspricht den Standard-Eingabekosten, das Lesen gecachter Token kostet das 0,1-Fache des Normalpreises. Details
- Gemini Implicit-Caching-Unterstützung:
- Implicit Caching: Standardmäßig für alle Gemini-2.5-Modelle aktiviert. Trifft Ihr Request den Cache, wird die Kostenersparnis automatisch angewandt. Diese Funktion ist seit dem 8. Mai 2025 verfügbar. Mindest-Token-Anzahl für Kontext-Caching: 1.024 für Gemini 2.5 Flash und 2.048 für Gemini 2.5 Pro.
- Tipps, um die Implicit-Cache-Hit-Rate zu erhöhen:
- Platzieren Sie große, häufig wiederverwendete Inhalte am Anfang des Prompts.
- Senden Sie Anfragen mit ähnlichen Präfixen innerhalb eines kurzen Zeitfensters.
- Die Anzahl der Cache-Hit-Token sehen Sie im Feld
usage_metadatades Response-Objekts. - Die Kostenersparnis basiert auf Prefilled-Cache-Hits. Nur Prefill-Cache und YouTube-Video-Preprocessing-Cache sind für Implicit Caching geeignet.
Zuletzt aktualisiert: 2026-07-10