Ein-Klick-Installation für das Aihubmix-Plugin
Klicken Sie einfach auf den untenstehenden Link und drücken Sie auf der Dify-Marketplace-Seite die Schaltfläche Install: 👉 Zur Dify-Plugin-Seite Beispielbild: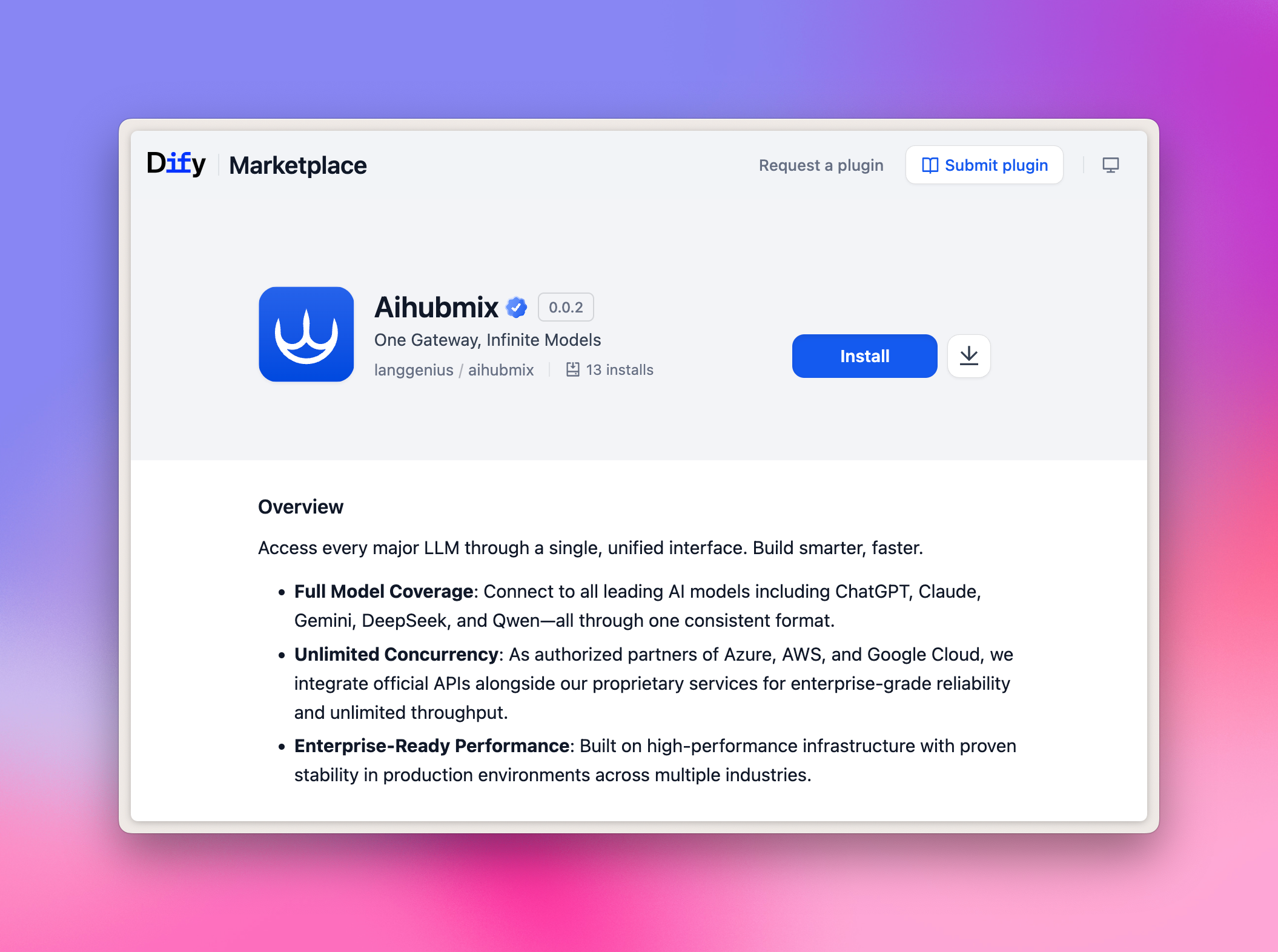
Konfiguration
- Klicken Sie oben rechts auf den Avatar → wählen Sie „Settings”
- Klicken Sie auf den Tab „Model Provider”
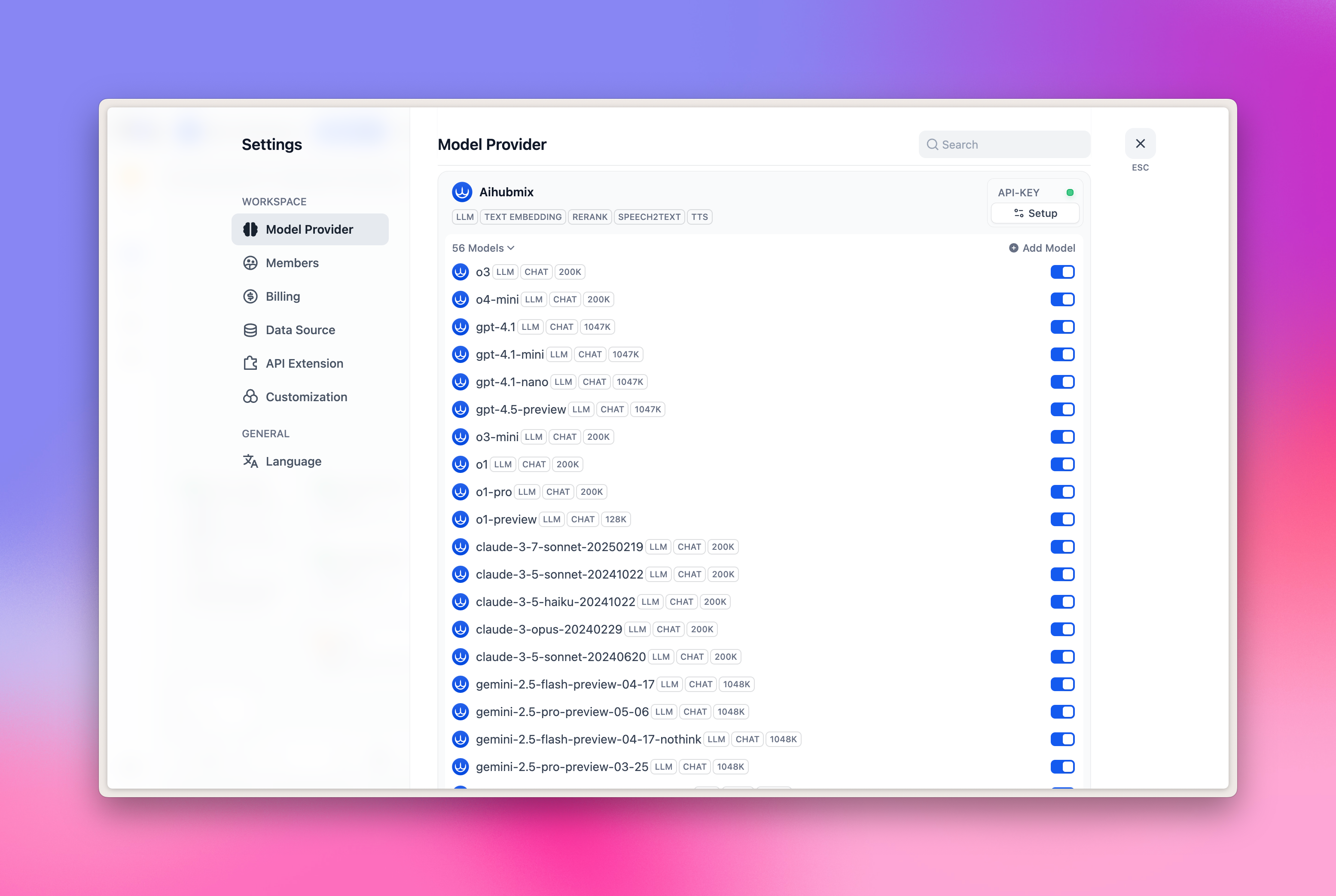
- Suchen Sie auf der rechten Seite Aihubmix → erweitern Sie „Setup” und tragen Sie Ihren API Key ein
 Derzeit sind folgende 5 Modellkategorien vorkonfiguriert:
Derzeit sind folgende 5 Modellkategorien vorkonfiguriert:
- LLM: Large Language Model
- TEXT EMBEDDING: Vektor-Embedding-Modell
- RERANK: Reranking-Modell
- SPEECH2TEXT: Speech-to-Text-Modell
- TTS: Text-to-Speech-Modell
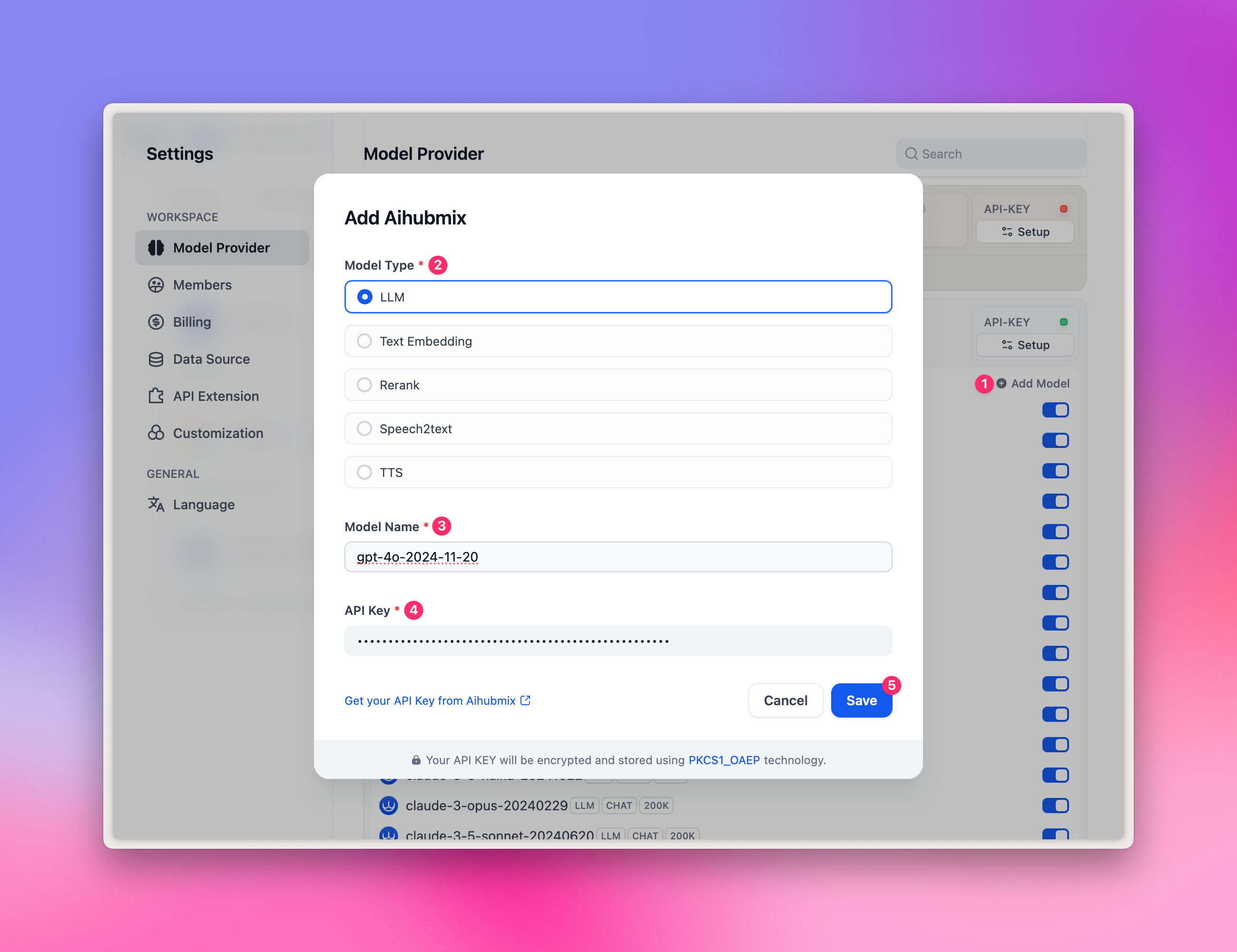
- Tragen Sie eine beliebige Model-ID aus der Modellgalerie ein, z. B.
gpt-4o-2024-11-20. - Geben Sie Ihren API Key ein und klicken Sie auf „Save”.
gpt-image-1 können daher nicht hinzugefügt werden.
LLM-Auswahl
Wählen Sie im Workflow-Knoten „LLM” – dann können Sie die von Aihubmix bereitgestellten Modelle auswählen. Beispielbild: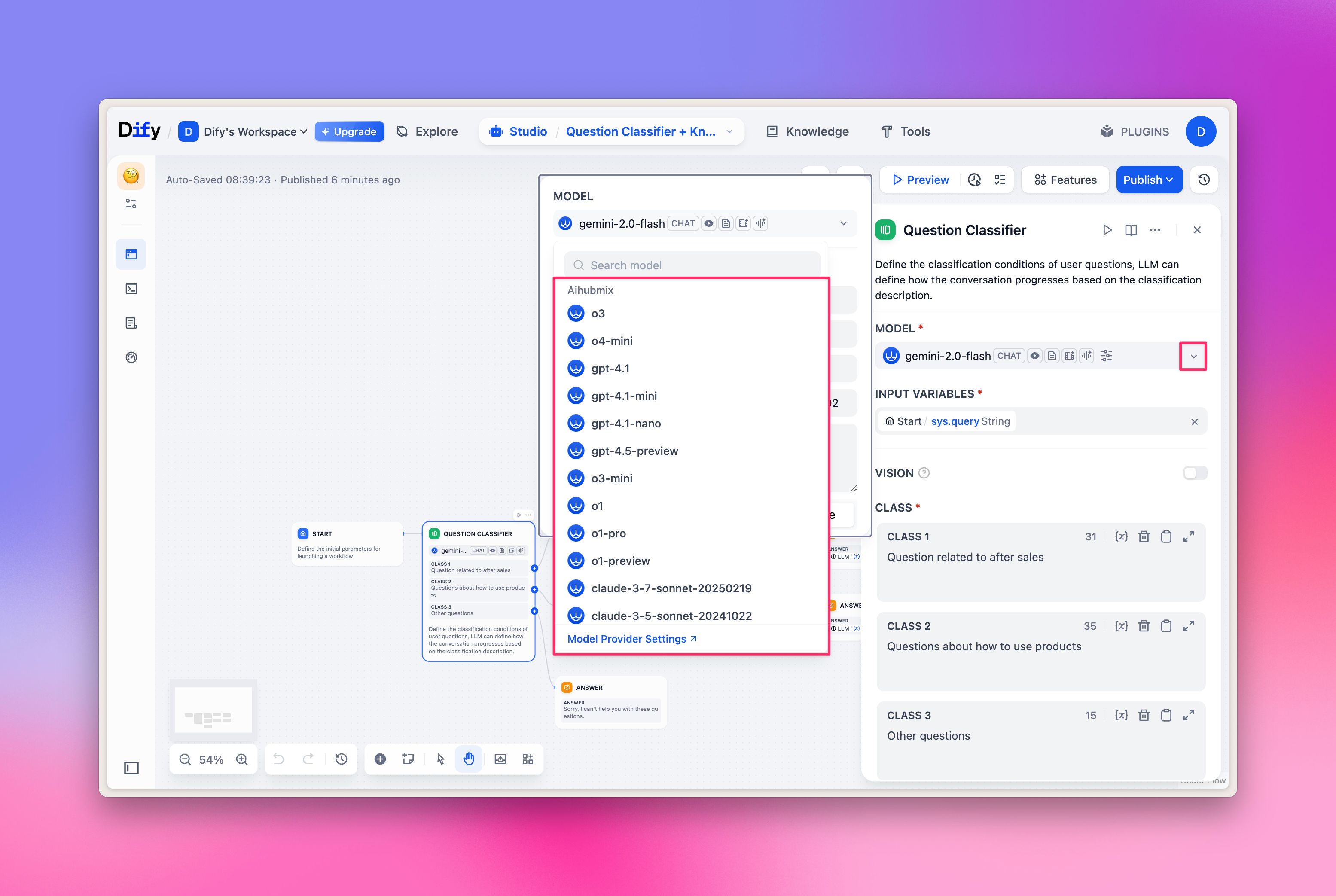
Auswahl von Embeddings-/Reranker-Modellen
Embeddings-/Reranker-Modelle werden hauptsächlich für die Wissensdatenbank-Q&A verwendet. Sie können sie im oberen Tab „Knowledge” schnell ausprobieren und auch im Workflow-Knoten das entsprechende Modell auswählen. Beispielbild: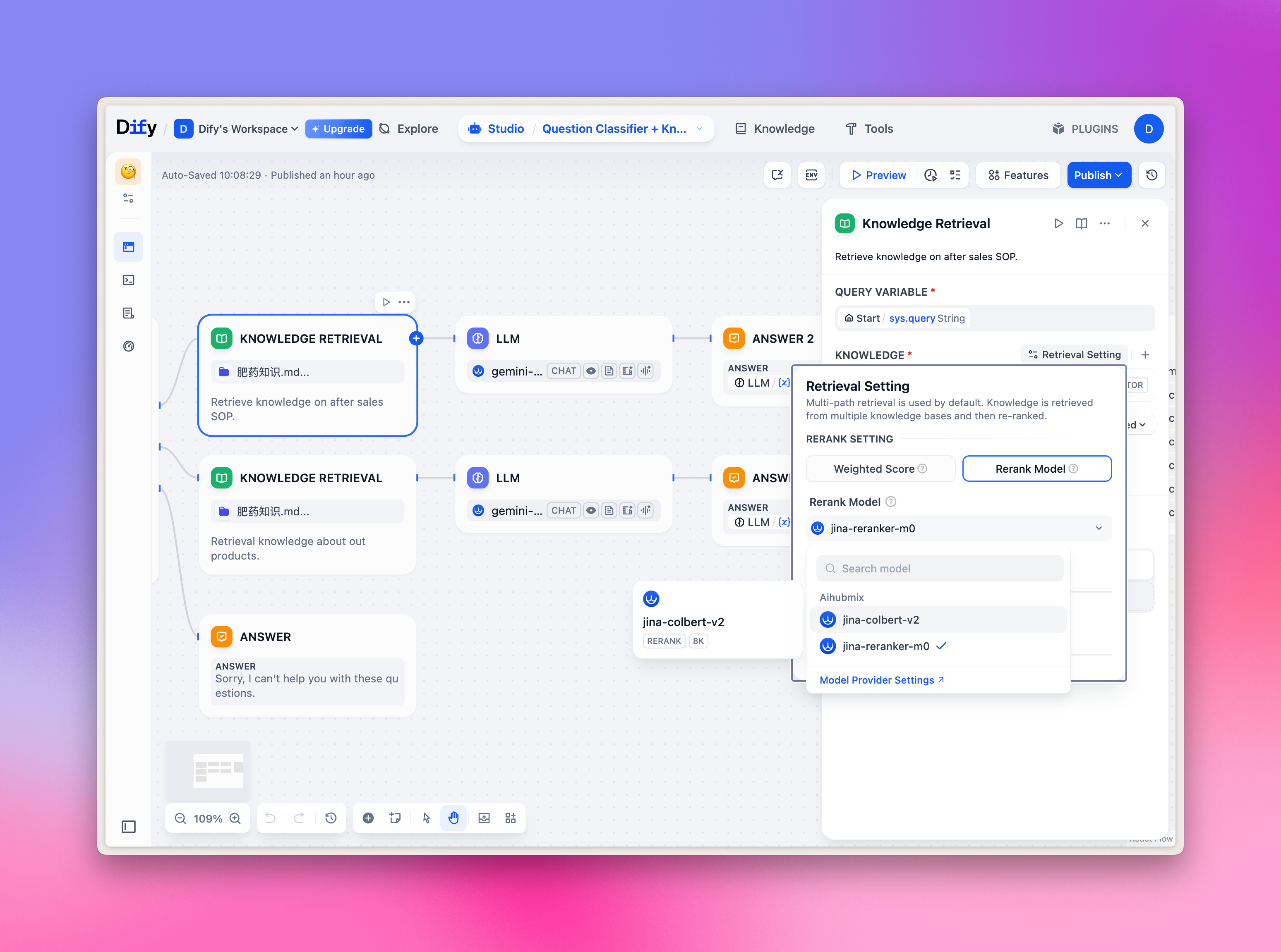
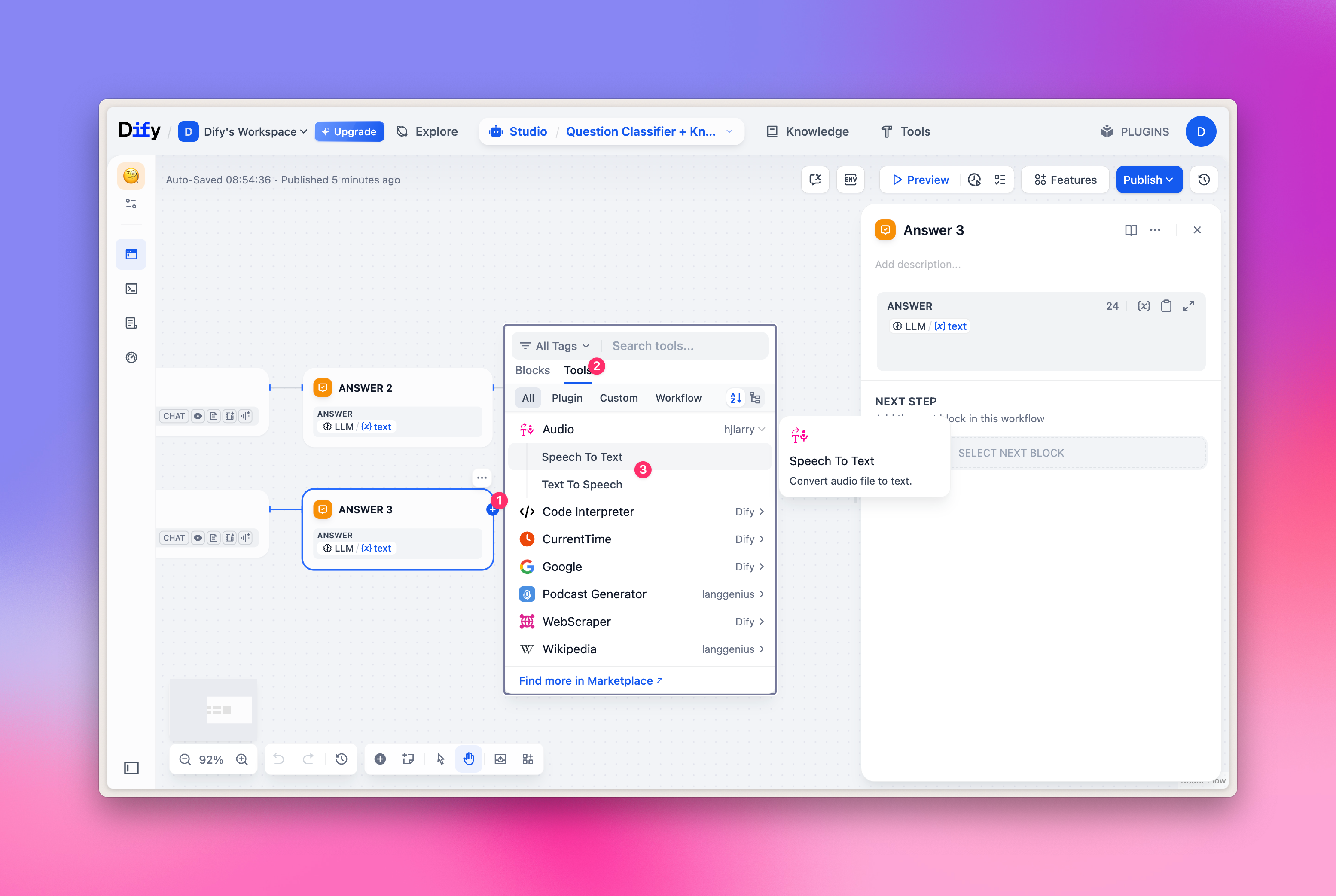
TTS/SST-Auswahl
TTS/SST-Modelle dienen hauptsächlich der Sprach-Verarbeitung und -Synthese. Bei der Werkzeugauswahl entspricht dem nicht das reguläre „LLM”, sondern der Typ „Audio” im Tab „Tools”. Zuordnung:- TTS Text-to-Speech: wählen Sie „Text to Speech”
- SST Speech-to-Text: wählen Sie „Speech to Text”
Claude Prompt Caching
Aktivieren Sie Prompt-Caching für Claude-Modelle in Dify über dieses Plugin: Umschließen Sie den zu cachenden Prompt mit<cache>…</cache> und setzen Sie in den Modellparametern die „Automatische Cache-Schwelle für große Nachrichten” auf eine positive Ganzzahl. Vollständige Verwendung und Hinweise zu Cache-Hits siehe Claude Prompt Caching.
Zuletzt aktualisiert: 2026-06-01