上流の障害を、あなたの障害にしてはいけません。AIHubMix は Key単位 の2つの機能を提供しており、コンソールで一度設定するだけで有効になり、クライアントコードの変更は不要です。
- モデル名マッピング(Model Mapping)とは、ゲートウェイ層でクライアントのリクエストに含まれるモデルエイリアスを実際の上流モデルに書き換える機能です。
- エラー時のフォールバック(Fallback)とは、メインモデルの呼び出しが失敗したときに、ゲートウェイがあらかじめ設定された優先順位に従って自動的に代替モデルを試す、クライアントには意識させない機能です。
AIHubMix はKey単位でモデル名マッピングとエラー時のフォールバックを設定でき、最終的に応答したモデルで課金します。いずれも AIHubMix Key管理ページ で個々の API Key に対して設定します。
Model name mapping と Fallback models on error の 2 つのセクションでそれぞれ設定します。
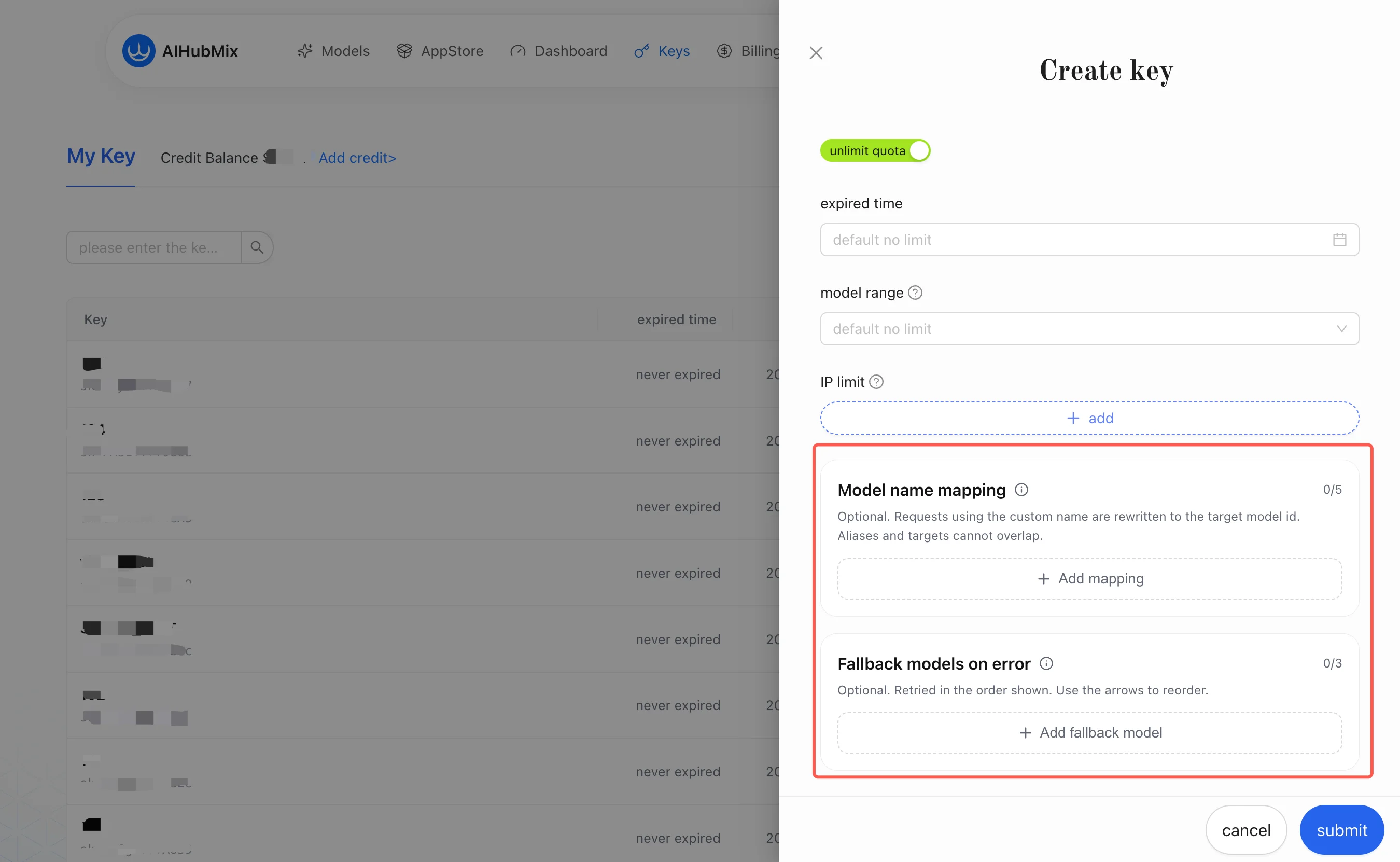
1. モデル名マッピング(Model Mapping)
モデル名マッピングは、「クライアントが見ているモデル名」と「AIHubMix が実際に呼び出すモデル」が一致しない問題に対処するためのものです。これは Key単位(per-key)のエイリアス書き換えで、リクエストに含まれるエイリアスを、Keyに設定した対象モデルへ書き換えます。対象モデルは、チャネルが選択された後、プラットフォーム内部でさらにもう一段のチャネル単位のマッピングが行われて実際の上流モデルへ変換されます。この層はユーザーには透過的で、設定は不要です。あなたが気にする必要があるのは「エイリアス → 対象モデル」のこの層だけです。例:
上表のモデル名はいずれも AIHubMix モデルページ で確認できます。主な用途:
- クライアントがモデル名のフォーマットを制限している場合。例えば Claude Desktop はモデル名が Claude 風であることを要求します(第5節 を参照)。
- 複雑なモデル ID に、より短く安定したエイリアスを設定する。
- クライアント設定はそのままに、AIHubMix のバックエンドで実際のモデルを切り替える。
- 複数のプラットフォームで共通の接続用命名を使いつつ、Keyに応じて異なるモデルにルーティングする。
1文字単位で一致:クライアントが送信するモデル名は、マッピング左側と 1文字単位で完全に一致 していなければなりません。例えばmy-gpt-5.5とmy-gpt-5-5は別の文字列であり、一致しなければマッピングはヒットしません。
2. エラー時のフォールバック(Fallback)
エラー時のフォールバックは、メインモデルが失敗したときに代替モデルを順番に試すためのものです。これはクライアント側のリトライではなく、同一Keyの設定のもとで AIHubMix ゲートウェイ側が行うモデル切り替えであり、接続側はリクエストごとに追加のルーティングパラメータを渡す必要はありません。 Fallback は「順序付きリスト へのマッピング」と理解できます。メインモデルが失敗すると、ゲートウェイは自動的にリストの次の代替モデルへ進みます。 例(同一Key内で設定):2.1 トリガー条件(すべて満たした場合のみフォールバック)
以下の条件がすべて成立 した場合にのみフォールバックが発生します。- Keyに空でない代替モデルリストが設定されている。
- メインモデルの すべてのチャネルが試行され、いずれも「リトライ可能なエラー」で失敗した(チャネルの枯渇)。
- 応答がまだ返り始めていない(最初のバイト/ヘッダーがまだクライアントに送られていない)。
- エラーがKey/ユーザー単位のエラーではない(下記 2.2 の対照表 を参照)。
2.2 フォールバックされる場合・されない場合
補足:ここでの「Keyの無効」とは あなた自身の AIHubMix Key の無効を指し、この場合はフォールバックしません。ある 上流チャネル の key が壊れた場合は、ゲートウェイがチャネルを切り替え、チャネルが枯渇した後も フォールバックは可能 です。両者を混同しないでください。
2.3 課金基準
最終的に応答したモデルで課金します。 最終的にフォールバックモデルが応答した場合、課金・能力・コンテキスト制限はいずれも最終的に応答したそのモデルを基準とします。このモデルはレスポンスヘッダーにも反映されます(第4節 を参照)。2.4 無料モデルのルール(重要)
無料モデルは fallback の選択肢にできません。 無料モデルはメインモデルとしてのみ使用でき、代替リストに入れても 暗黙的にスキップ され、次へ進みます。したがって無料モデルを fallback リストに書かないでください。典型的な使い方:無料モデルをメインモデルに設定し、有料モデルを代替リストに入れます。無料のメインモデルがクォータ/レート制限に達すると、自動的に代替の有料モデルへフォールバックします。普段は無料枠でコストを抑え、制限がかかったらシームレスに有料モデルへ切り替えて可用性を確保します。これは fallback の最も一般的な使い方の一つです。
3. OpenRouter / LiteLLM との違い
モデルマッピングとフォールバックは新しい概念ではなく、OpenRouter や LiteLLM などでも類似の機能を提供しています。AIHubMix の違いは 設定コストが最小 であることです。
一言でいえば、ゲートウェイの自前構築もクライアントコードの1行の変更も不要で、Key に一度設定するだけで有効になります。
4. 設定と検証
4.1 設定
- Key にエイリアスマッピングを設定します。左側のエイリアスは、クライアントが実際に送信するモデル名と 1文字単位で一致 させてください。
- 同じKey に代替モデルリスト(順序付きの優先順位リスト)を設定します。
- 代替リストには 有料/利用可能なモデルのみを入れ、無料モデルは入れません(スキップされます)。
- 代替リスト内のモデルは、そのKeyの利用可能モデル範囲内でなければなりません(権限外のモデルはスキップされます)。
4.2 検証(ログを漁るのではなく、まずレスポンスヘッダーを見る)
トラブルシューティングの際は クライアントがどのモデルを選んだかだけを見ない でください。最も信頼でき、自動化しやすい方法はレスポンスヘッダーを読むことです。X-Aihubmix-Fallback: true:今回のリクエストでフォールバックが発生した(最終モデル ≠ メインモデルのときに付与)。X-Aihubmix-Model:今回実際に応答し、それに基づいて課金されるモデル。
5. シナリオ1:Claude Desktop
Claude Desktop はGateway 経由で AIHubMix に接続しており、モデル名マッピングの典型的なシナリオです。
本節では Claude Desktop の基本的な接続をすでに完了していることを前提とします。完全な接続手順(ダウンロード・インストール、開発者モード、Gateway 設定、auth scheme など)は Claude Desktop で AIHubMix を利用する を参照してください。本節ではマッピングとフォールバックの追加設定のみを扱います。
5.1 なぜマッピングが必要か
Claude Desktop はGateway(Anthropic-compatible)方式で接続するため、クライアントは Claude 風にモデル名を制約し、モデル名は claude- 接頭辞を使用しなければなりません。
ここで矛盾が生じます。クライアント側では claude- 風の名前しか書けないのに、実際に呼び出したいのは gpt-5.5、gemini-3.1-pro-preview などです。モデル名マッピングはまさにこのためにあります。 クライアントでエイリアス claude-g-p-t-5.5 を書き、AIHubMix 側で実際の gpt-5.5 にマッピングします。
Claude Desktop は Claude ネイティブの /v1/messages インターフェースを利用するため、本記事の例では マッピングと Fallback の両方が有効 です。
5.2 AIHubMix のマッピングとフォールバックの設定
設定例: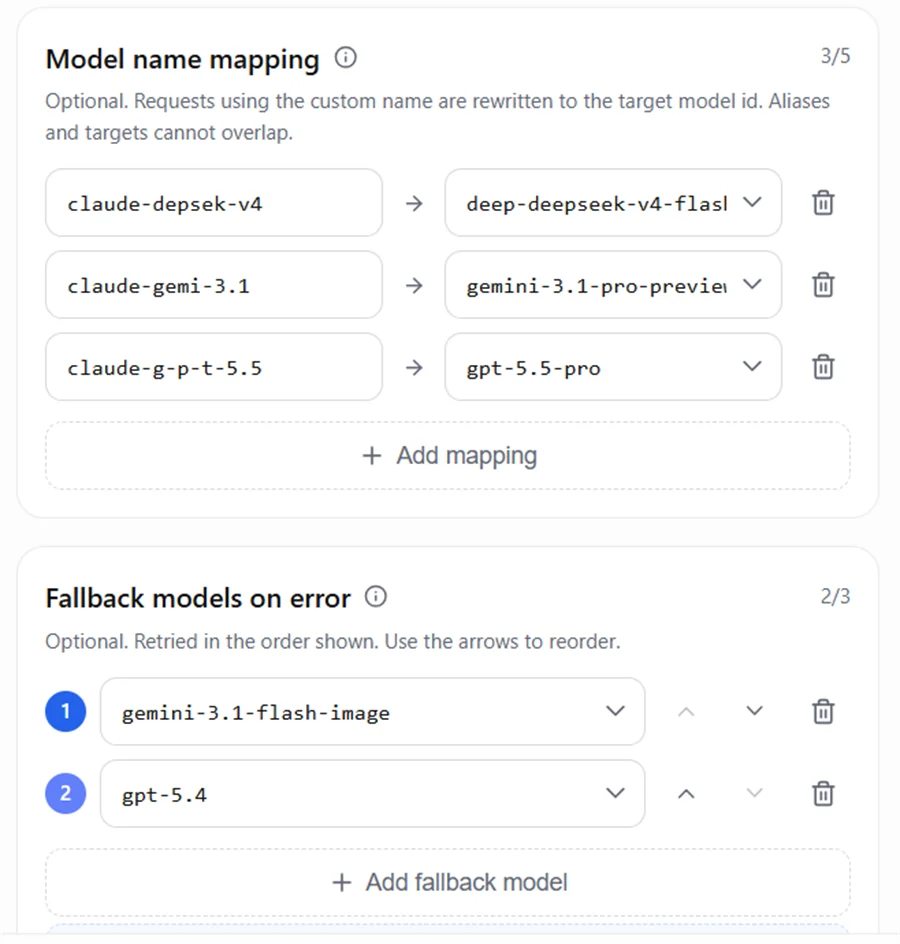
5.3 Claude Desktop のモデルリスト
Claude Desktop のModel list に設定するのは マッピング前のエイリアス です。つまり Claude Desktop が AIHubMix に送るモデル名であり、実際の上流モデル名ではありません。
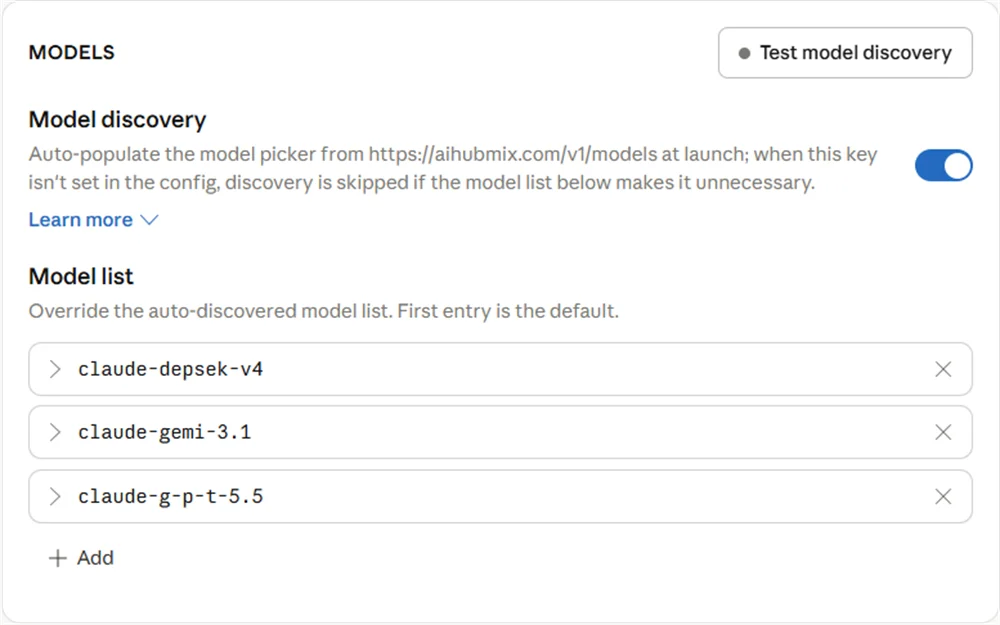
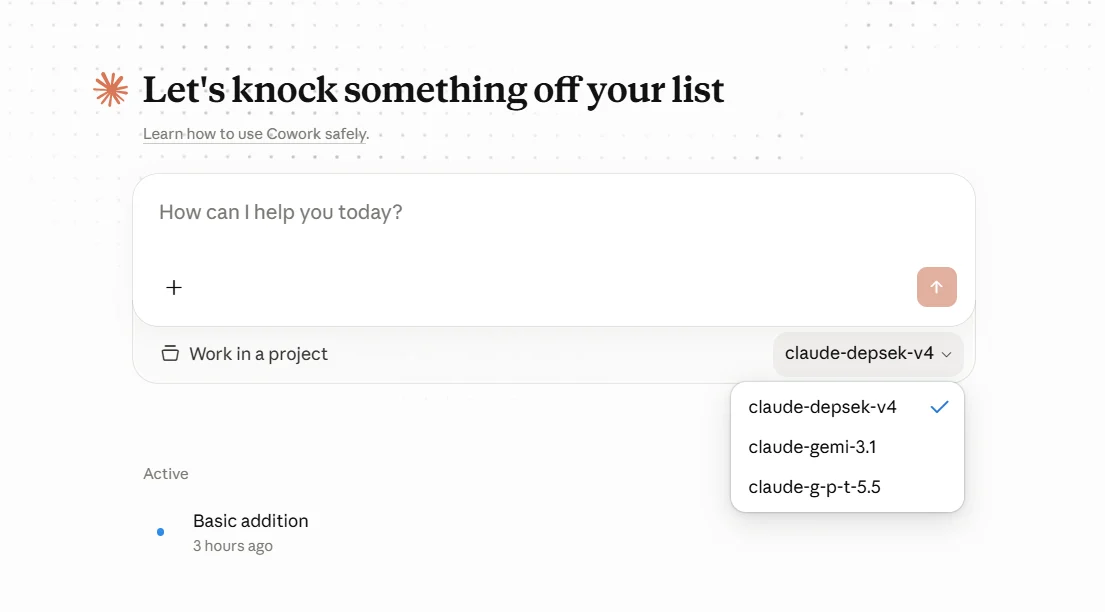
Model IDにはclaude-接頭辞を使用します。gpt、gemini、deepseekなどの実際のモデルシリーズ名を直接書かず、g-p-t、gemi、depsekなどのエイリアスを使用します。Model IDは AIHubMix マッピングの左側と 1文字単位で一致 させてください。一致しないとリクエストが想定のマッピングにヒットせず、エラー時のフォールバックモデルへ進んでしまう可能性があります。
6. シナリオ2:マルチモーダル能力のバックアップ
マルチモーダル能力のバックアップは、「メインモデルはテキストには回答できるが、現在の入力タイプをサポートしていない」というシナリオに対処するためのものです。例えばクライアントが画像や動画を送信したのに、メインモデルがテキスト入力能力しか持たない場合、AIHubMix はフォールバックリスト内の対応するモダリティをサポートするモデルを引き続き試すことができます。 以下は実際のテスト経路です。このKeyのマッピングと fallback の設定は次の通りで(下のスクリーンショットを参照)、ポイントは fallback リストにテキストモデルと画像理解をサポートするモデルの両方が含まれていることです。claude-g-l-m-4.6(テキスト入力のみをサポートするモデル)と表示されています。ユーザーは AIHubMix モデルリストページのスクリーンショットをアップロードし、「このサイトは何をするものか」と質問しました。リクエストに画像が含まれているため、テキストモデルはこの入力を直接処理できず、fallback がトリガーされました。
Google AI Studio/gemini-3.1-flash-image、つまり fallback リストの2番目です。1番目の gpt-5.4 も同様にこの画像入力をサポートせず、今回のリクエストに対してリトライ可能なエラーを返し続けたため、ゲートウェイは次へ進み、画像理解をサポートする gemini-3.1-flash-image に落ち着きました。
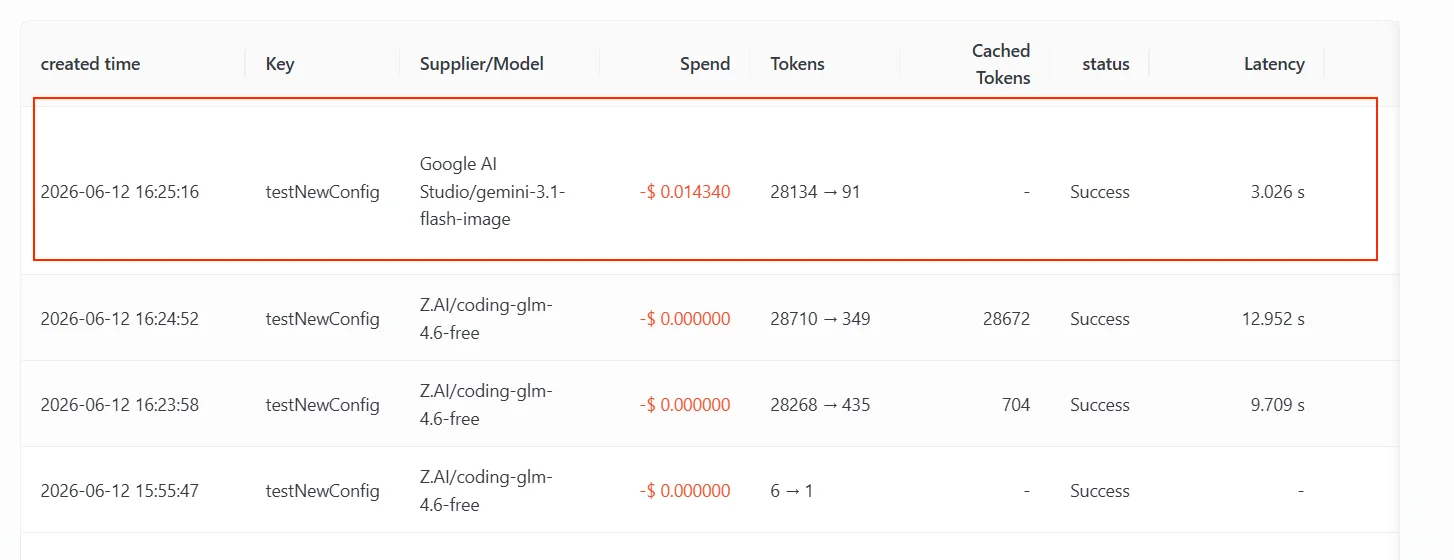
トリガーの理由を明確に:ここでのバックアップは 上流がこの画像入力に対してリトライ可能なエラーを返し、かつメインモデルのチャネルが枯渇した ために発生しました。「メインモデルが制限された後のフォールバック」と同じフォールバックの仕組みであり、トリガーとなるエラーの種類が異なるだけです(前者は入力がサポートされていない、後者はクォータ/レート制限)。
理解と生成の区別に注意:ここで言うのは 画像/動画の理解 のバックアップであり、画像生成や動画生成 ではありません。チャットリクエストが自動的に生成インターフェースに変わることはありません。画像生成や動画生成をテストするには、対応する生成インターフェースとモデルを使用してください。モデルの能力は AIHubMix モデルページに現在表示されている Input Modalities を基準とします。
7. シナリオ3:無料モデルのバックアップ(コスト削減+可用性確保)
これは fallback の最も一般的な使い方の一つです。無料モデルをメインモデルに設定 し、有料モデルを代替リストに入れます。普段のリクエストはすべて無料モデルを通してコストを抑え、無料のメインモデルがクォータ/レート制限に達すると、ゲートウェイが自動的に代替の有料モデルへフォールバックし、サービスの中断を防ぎます。 Key設定の例:- 無料枠がまだ足りている場合、リクエストはメインモデル
coding-glm-5.2-freeが応答し、無料として課金されます。 - 無料のメインモデルが制限に達すると、自動的に
gpt-5.4へフォールバックします。gpt-5.4も利用できない場合は、さらにgemini-3.1-pro-previewを試します。 - 最終的にどのモデルが応答したかに応じて、そのモデルで課金されます(2.3 を参照)。
注意:無料モデルはメインモデルとしてのみ使用でき、fallback リストに入れることはできません(入れてもスキップされます。2.4 を参照)。したがって「無料バックアップ」の正しいやり方は、無料をメインに、有料を代替にすることであり、その逆ではありません。検証方法も同じくレスポンスヘッダーを見ます。フォールバックが発生すると
X-Aihubmix-Fallback: true が返り、X-Aihubmix-Model が最終的に応答したモデルを示します(第4節 を参照)。
8. サポートされるエンドポイント
モデルマッピングとエラー時のフォールバックは、現在以下のインターフェースカテゴリをサポートしています。
ポイント:
- モデルマッピングとエラー時のフォールバックは、OpenAI 互換インターフェース、Claude ネイティブ
/v1/messages、OpenAI Responses/v1/responsesの3種類のインターフェースをサポートします。 - その他のネイティブパススルーインターフェース(Gemini ネイティブ、Ideogram、動画、TTS、Stability、OCR、predictions など)、指定チャネルのパススルー、およびリソース ID による取得/ファイル系インターフェースは 現在サポートしていません。
- Claude Desktop は Claude ネイティブの
/v1/messagesを利用するため、本記事の例では マッピングと Fallback の両方が有効 です。
9. よくある質問 FAQ
Q:Claude Desktop で model not found と表示されたらどうすればよいですか? A:Claude Desktop のModel ID が AIHubMix マッピングの左側と 1文字単位で一致 しているか確認してください。一致しないとマッピングはヒットしません。
Q:フォールバックは課金に影響しますか?
A:最終的に応答したモデル で課金します。最終的にどのモデルが応答したかに応じて、そのモデルの価格・能力・コンテキスト制限で計算されます。
Q:今回のリクエストがフォールバックを通ったかどうかを確認するには?
A:レスポンスヘッダー X-Aihubmix-Fallback: true(フォールバックが発生)と X-Aihubmix-Model(最終的に応答したモデル)を見てください。第4節 を参照。
Q:どのエラーがフォールバックをトリガーし、どのエラーがトリガーしませんか?
A:2.2 の対照表 を参照してください。簡単に言えば、上流のリトライ可能な失敗、チャネルの枯渇、応答が未開始の場合のみフォールバックします。チャネル指定、応答が開始済み、クライアント切断/タイムアウト、Key/ユーザー単位のエラーはいずれもフォールバックしません。
Q:無料モデルを fallback リストに入れられますか?
A:入れられません。スキップされます。無料モデルはメインモデルとしてのみ使用できます。
Q:OpenRouter / LiteLLM の model alias / fallback と何が違いますか?
A:AIHubMix は Key単位・プラットフォームでホスト されており、コンソールで一度設定すれば有効になり、クライアントコードの変更もゲートウェイの自前構築も不要です。詳しくは 第3節 を参照してください。
関連リソース
- Claude Desktop で AIHubMix を利用する:開発者モード、Gateway 設定、auth scheme などの完全な手順。
- AIHubMix モデルページ:モデル名、価格、
Input Modalitiesを確認できます。 - LiteLLM で AIHubMix を利用する:ゲートウェイの自前構築+モデルマッピング/フォールバックが必要な場合の参考。