Imagen 描画
Imagenは、Googleが開発した高度な画像生成AIモデルシリーズで、テキストプロンプトに基づいて高品質でリアルな画像を生成できます。このガイドでは、パラメータ設定、モデル選択、コード例など、ImagenシリーズAPIを使用して画像を生成する方法を説明します。 利用可能なモデルリスト:- imagen-4.0-ultra-generate-001
- imagen-4.0-generate-001
- imagen-4.0-fast-generate-001
- imagen-4.0-fast-generate-preview-06-06
- imagen-3.0-generate-002
モデルパラメータ
Imagenは現在、英語のプロンプトのみをサポートしており、以下のパラメータを提供しています。- numberOfImages: 生成する画像の数。1から4(含む)の範囲。デフォルト値は4です。また、
imagen-4.0-ultra-generate-001は一度に1枚しか生成できないことに注意してください。 - aspectRatio: 生成される画像の縦横比を変更します。「1:1」、「3:4」、「4:3」、「9:16」、「16:9」がサポートされています。デフォルト値は「1:1」です。
- personGeneration: モデルが人物画像を生成することを許可します。以下の値がサポートされています。
- 「DONT_ALLOW」:人物画像の生成をブロックします。
- 「ALLOW_ADULT」:成人画像を生成しますが、子供画像は生成しません。これがデフォルト値です。
料金
Imagen APIで画像を生成する料金は以下の通りです:- imagen-4-ultra:$0.06/枚
- imagen-4:$0.04/枚
- imagen-4-fast:$0.02/枚
- imagen-3:$0.03/枚 ご注意ください。1回の呼び出しで1~4枚の画像を生成でき、料金は実際に生成された枚数に応じて計算されます。
呼び出し例
以下は、Imagenを使用して画像を生成するPython呼び出しの例です。プロンプトのヒント
理想的な画像を得るためには、効果的なプロンプトを作成することが重要です。- 主題、スタイル、照明、角度など、詳細な説明を使用します。
- 芸術的なスタイル(映画のような、写実主義、アニメスタイルなど)を指定します。
- 技術的な詳細(DSLR、高解像度、詳細など)を含めます。
- 否定的または禁止されたコンテンツを避けます。
- プロンプトに大量のテキストを含めないでください。より安定した結果を得るには、重要なキーワードのみを使用してください。
- キーワードに
girlが含まれている場合、TypeError: ‘NoneType’ object is not iterableエラーが発生しやすいです。人物の描画には推奨されません。
Gemini 2.0 Flash 画像生成
Geminiも画像生成機能を提供しており、代替案として利用できます。Imagen 3.0と比較して、Geminiの画像生成は、究極の芸術的表現や視覚的品質を追求するのではなく、コンテキスト理解と推論が必要なシナリオに適しています。- より高い視覚的品質 → 実験版と比較して、画像はより鮮明で、より豊かで、よりクリアです。
- より正確なテキスト表現 → 生成されたビジュアル内のテキストは、より正確で、きれいで、読みやすいです。
- フィルタリングによるブロックが大幅に減少 → よりスマートで寛容なフィルタリングメカニズムのおかげで、作成中に中断されることはほとんどありません。
- モデルID:
gemini-2.0-flash-preview-image-generation - 料金(入力→出力):0.4/Mトークン
- 新機能
"modalities":["text","image"]を体験するには、新しいパラメータを追加する必要があります。 - 画像はBase64エンコード形式で渡され、出力されます。
- 実験モデルであるため、「画像を生成」と明示的に指定することをお勧めします。そうしないと、テキストのみになる可能性があります。
- 出力画像のデフォルトの高さは1024pxです。
- Python呼び出しには最新のOpenAI SDKサポートが必要です。まず
pip install -U openaiを実行してください。 - 詳細については、Gemini公式ドキュメントをご覧ください。
画像とテキストの生成
入力:テキスト + 画像 出力:テキスト + 画像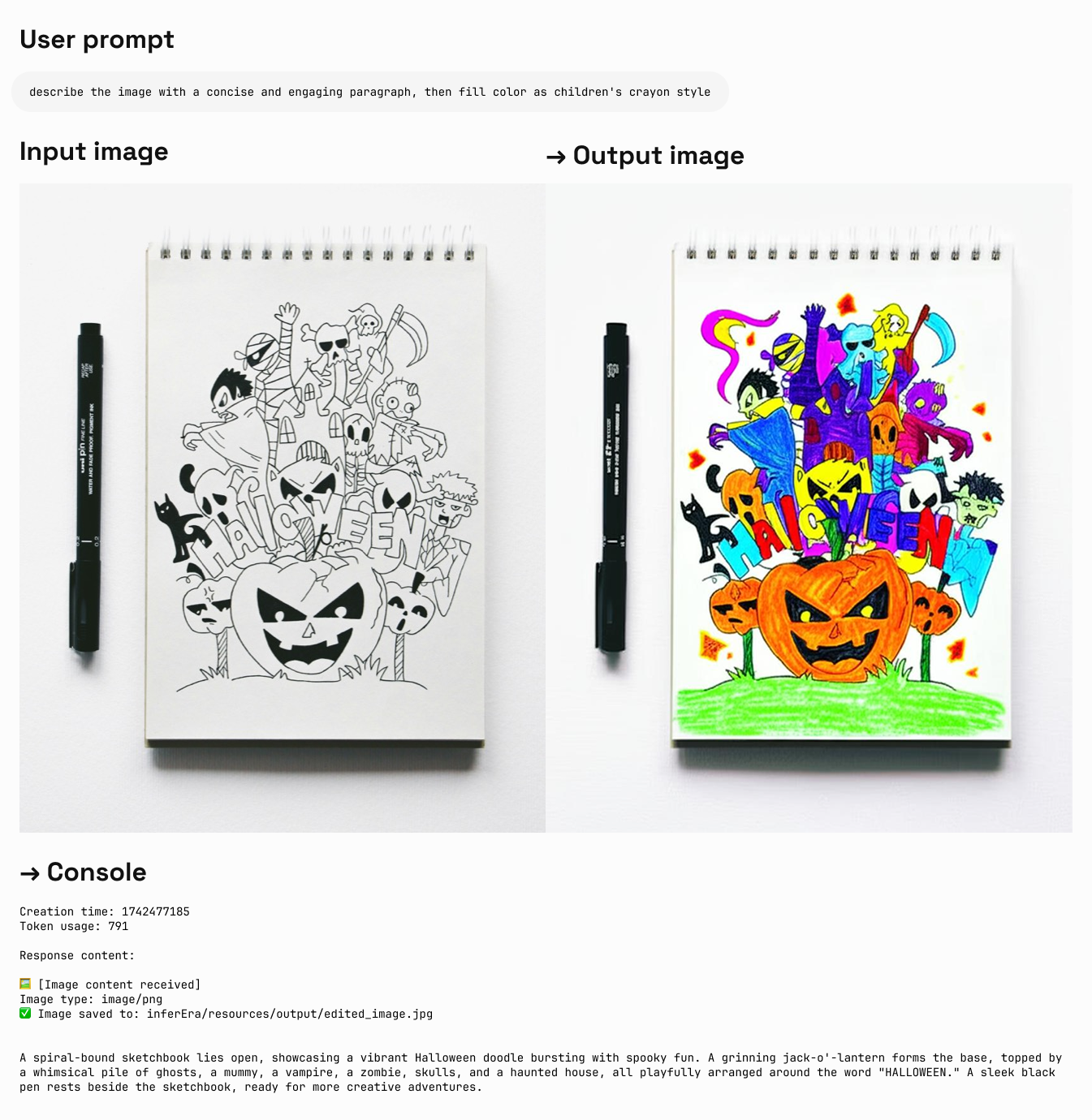
画像編集
入力:テキスト + 画像 出力:テキスト + 画像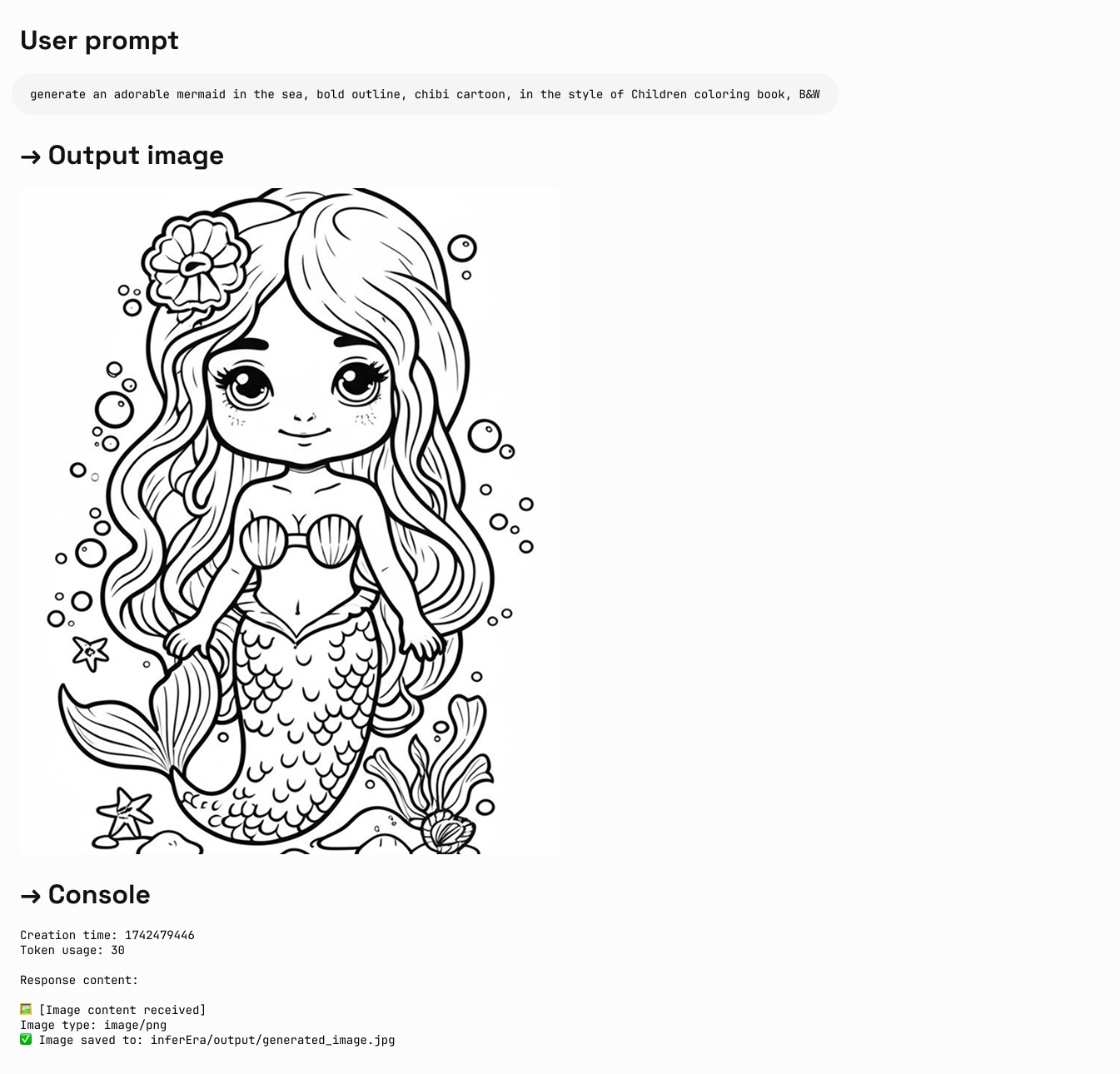
正しい描画モデルの選択
Geminiを選択する場合:
- 世界の知識と推論能力を活用して、コンテキストに関連する画像を生成する必要がある場合。
- テキストと画像をシームレスに組み合わせる必要がある場合。
- 長いテキストシーケンスに正確な視覚コンテンツを埋め込む必要がある場合。
- コンテキストを維持しながら、対話形式で画像を編集したい場合。
Imagenを選択する場合:
- 画像の品質、写真のようなリアルさ、芸術的な詳細、または特定のスタイル(印象派、アニメなど)が最優先事項である場合。
- 製品の背景更新や画像の拡大など、プロフェッショナルな編集タスクを実行する場合。
- ブランド、スタイルを注入したり、ロゴや製品デザインを生成したりする場合。
ベストプラクティス
- プロンプトの最適化:高品質な出力を得るための鍵となるプロンプトを慎重に設計します。
- パラメータの実験:さまざまなアスペクト比と設定を試して、ニーズに最適な構成を見つけます。
- バッチ生成:複数の画像を生成して、理想的な結果を得る可能性を高めます。
- メタデータの保存:プロンプトとタイムスタンプを画像と一緒に保存して、成功した結果を追跡および複製できるようにします。
- 使用ポリシーの遵守:使用がGoogleのコンテンツポリシーと利用規約に準拠していることを確認します。
Veo 3.0 ビデオ生成
VEO 3.0は、Google DeepMindが開発した最新の高度なビデオ生成モデルです。VEO 3.0を使用すると、以下の特徴を持つビデオを生成できます。- テキストと画像プロンプトから生成される品質の向上
- 音声、例えば会話やナレーション
- 音声、例えば音楽や効果音
既知の制限
現在、VEO 3.0のパラメータは固定されており、変更できません。- 解像度: 720p(横長)
- フレームレート: 24fps
- ビデオ長: 8秒
料金
VEO 3.0 APIの使用料は1秒あたり$0.675です(Aihubmixは10%の期間限定割引を提供)。呼び出し例
VEO 3.0は現在、curlコマンド呼び出しのみをサポートしており、2段階の処理方法を採用しています。sk-***は、AiHubMixで生成したキーに置き換えてください。
戻り値の例
ステップ1の戻り値:ベストプラクティス
- 辛抱強く待つ:ビデオ生成には通常数分かかりますが、ピーク時にはさらに時間がかかる場合があります。
- ステータスの確認:戻り値に
done: trueがない場合、まだ処理中です。 - 操作IDの保存:後続のクエリのために、ステップ1で返された操作IDを必ず保存してください。
- 使用ポリシーの遵守:使用がGoogleのコンテンツポリシーと利用規約に準拠していることを確認してください。
Veo 2.0 ビデオ生成
VEO 2.0は、Googleが開発した高度なビデオ生成AIモデルで、テキストプロンプトに基づいて高品質でリアルな短いビデオを生成できます。以下のガイドでは、パラメータ設定、モデル選択、コード例など、VEO 2.0 APIを使用してビデオを生成する方法を説明します。モデルパラメータ
VEO 2.0は以下のパラメータを提供しています。- numberOfVideos: 生成するビデオの数。1または2を選択できます。デフォルト値は2です。
- aspectRatio: 生成されるビデオの縦横比。「16:9」と「9:16」がサポートされています。
- durationSeconds: ビデオの長さ。5秒または8秒を選択できます。デフォルト値は8秒です。
- personGeneration: 人物を含むビデオの生成を許可するかどうかを制御します。以下の値がサポートされています。
- 「dont_allow」:人物を含むビデオの生成をブロックします。
- 「allow_adult」:成人を含むビデオの生成を許可しますが、子供のビデオは生成しません。
料金
VEO 2.0 APIの使用料は1秒あたり$0.35です。呼び出し例
以下は、VEO 2.0を使用してビデオを生成するPython呼び出しの例です。プロンプトのヒント
理想的なビデオを得るためには、効果的なプロンプトを作成することが重要です。- シーン、アクション、雰囲気を明確に記述します。
- 撮影スタイル(パノラマ、クローズアップ、トラッキングショットなど)を指定します。
- 照明条件(晴れ、夕暮れ、室内照明など)を記述します。
- 主題とそのアクションを指示します(例:「猫が日差しの中で眠っている」)。
- 複雑すぎる物語や急速に変化するシーンは避けます。
- 否定的または禁止されたコンテンツは避けます。
ベストプラクティス
- 簡潔で明確なプロンプト:明確で具体的な説明を使用してビデオ生成をガイドします。
- 辛抱強く待つ:ビデオ生成には2〜3分かかりますので、完了まで辛抱強くお待ちください。
- 異なるパラメータをテスト:さまざまなアスペクト比と長さを試して、ニーズに最適な設定を見つけます。
- 生成記録を保存:プロンプトと生成されたビデオを一緒に記録して、成功した結果を追跡できるようにします。
- 使用ポリシーの遵守:使用がGoogleのコンテンツポリシーと利用規約に準拠していることを確認してください。
最終更新日:2026-06-01