Guía de Imagen
Imagen es una serie avanzada de modelos de IA para generación de imágenes desarrollada por Google, capaz de crear imágenes realistas de alta calidad a partir de prompts de texto. Esta guía te ayudará a entender cómo usar la API de Imagen para generar imágenes, incluida la configuración de parámetros, la selección de modelo y ejemplos de código. Modelos disponibles:- imagen-4.0-ultra-generate-001
- imagen-4.0-generate-001
- imagen-4.0-fast-generate-001
- imagen-4.0-fast-generate-preview-06-06
- imagen-3.0-generate-002
Parámetros del modelo
Imagen actualmente solo admite prompts en inglés y ofrece los siguientes parámetros:- numberOfImages: El número de imágenes a generar, en un rango de 1 a 4 (ambos incluidos). El valor predeterminado es 4.
imagen-4.0-ultra-generate-001solo puede generar 1 imagen a la vez.- aspectRatio: Cambia la relación de aspecto de las imágenes generadas. Los valores admitidos son “1:1”, “3:4”, “4:3”, “9:16” y “16:9”. El valor predeterminado es “1:1”.
- personGeneration: Permite al modelo generar imágenes de personas. Admite los siguientes valores:
- “DONT_ALLOW”: Evita la generación de imágenes que contengan personas.
- “ALLOW_ADULT”: Genera imágenes de adultos pero no de niños. Este es el valor predeterminado.
Precios de uso
El costo de utilizar la API de Imagen para generar imágenes:- imagen-4-ultra: $0.06/imagen
- imagen-4: $0.04/imagen
- imagen-4-fast: $0.02/imagen
- imagen-3: $0.03/imagen
Ejemplo de llamada a la API
A continuación, un ejemplo en Python para generar imágenes con Imagen 3.0:Consejos para prompts
Crear prompts eficaces es fundamental para obtener las imágenes deseadas:- Usa descripciones detalladas que incluyan sujeto, estilo, iluminación, ángulo, etc.
- Especifica estilos artísticos (como cinematográfico, fotorrealista, estilo anime, etc.).
- Incluye detalles técnicos (como DSLR, alta definición, rico en detalles, etc.).
- Evita contenidos negativos o prohibidos.
- Evita incluir grandes cantidades de texto en los prompts, usa solo palabras clave esenciales para obtener resultados más estables.
Generación de imágenes con Gemini
Gemini también ofrece capacidades de generación de imágenes como alternativa. En comparación con Imagen, la generación de imágenes de Gemini se adapta mejor a escenarios que requieren comprensión y razonamiento contextual, en lugar de buscar la máxima expresión artística y calidad visual. Instrucciones:- ID de modelo:
gemini-2.5-flash-image-preview - Precios de entrada/salida: Texto: $0.3→$2.5/M tokens; Imagen: $0.3→$30/M tokens
- Se requiere añadir parámetros para experimentar nuevas funciones:
"modalities":["text","image"] - Las imágenes se pasan y se devuelven en codificación Base64
- La altura predeterminada de las imágenes de salida es 1024 px
- Las llamadas en Python requieren el SDK más reciente de OpenAI; ejecuta primero
pip install -U openai - Para más información, visita la documentación oficial de Gemini
Generación de texto a imagen
Entrada: texto Salida: texto + imagen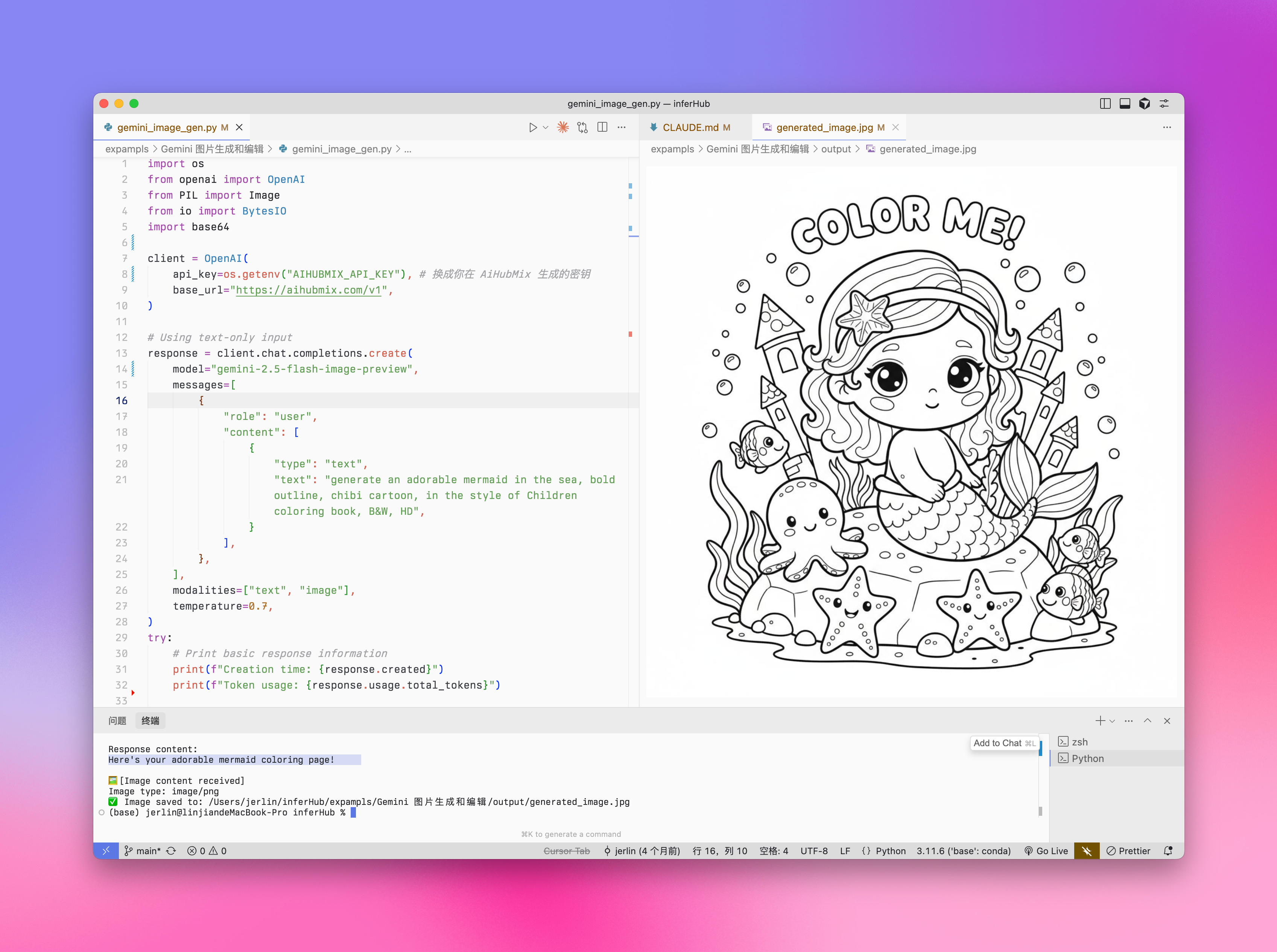
Editar imagen
Entrada: texto + imagenSalida: texto + imagen
Elegir el modelo adecuado
Cuándo elegir Gemini:
- Cuando necesites aprovechar el conocimiento del mundo y las habilidades de razonamiento para generar imágenes contextualmente relevantes.
- Cuando necesites una integración fluida entre texto e imágenes.
- Cuando quieras incrustar contenido visual preciso en secuencias largas de texto.
- Cuando quieras editar imágenes de forma conversacional manteniendo el contexto.
Cuándo elegir Imagen:
- Cuando la calidad de imagen, el fotorrealismo, el detalle artístico o los estilos específicos (como impresionismo, anime) sean las consideraciones principales.
- Cuando realices tareas de edición profesional, como actualizaciones de fondos de productos o ampliación de imágenes.
- Cuando incorpores marca, estilo o generes logotipos y diseños de producto.
Buenas prácticas
- Optimizar los prompts: Elaborar cuidadosamente los prompts es clave para obtener resultados de alta calidad.
- Experimentar con los parámetros: Prueba diferentes relaciones de aspecto y ajustes para encontrar la configuración que mejor se adapte a tus necesidades.
- Generación por lotes: Genera varias imágenes para aumentar las probabilidades de obtener resultados ideales.
- Guardar los metadatos: Guarda los prompts y las marcas temporales junto con las imágenes para rastrear y replicar los resultados exitosos.
- Cumplir con las políticas de uso: Asegúrate de que tu uso cumpla con las políticas de contenido y los términos de servicio de Google.
Generación de vídeo con Veo 3.0
VEO 3.0 es el último modelo avanzado de generación de vídeo desarrollado por Google DeepMind. Con VEO 3.0, puedes generar vídeos con las siguientes funciones:- Calidad mejorada a partir de prompts de texto e imagen
- Habla, como diálogos y locuciones
- Audio, como música y efectos de sonido
Limitaciones conocidas
Actualmente, los parámetros de VEO 3.0 son fijos y no se pueden cambiar:- Resolución: 720p (horizontal)
- Velocidad de fotogramas: 24fps
- Duración del vídeo: 8 segundos
Precios
El coste de la API de VEO 3.0 es de $0.675/segundo (Aihubmix ofrece un descuento del 10 % por tiempo limitado)Ejemplo de uso
VEO 3.0 actualmente solo admite llamadas mediante comandos curl, usando un proceso de dos pasos: Nota:sk-*** es tu clave generada en AiHubMix.
Ejemplos de respuesta
Respuesta del paso 1:Buenas prácticas
- Sé paciente: La generación de vídeo suele tardar unos minutos, más durante las horas pico
- Comprueba el estado: Si la respuesta no contiene
done: true, sigue procesándose - Guarda el ID de operación: Asegúrate de guardar el ID de operación devuelto en el paso 1 para consultas posteriores
- Cumple con las políticas de uso: Asegúrate de que tu uso cumple con las políticas de contenido y los términos de uso de Google
Generación de vídeo con Veo 2.0
VEO 2.0 es un modelo avanzado de IA para generación de vídeo lanzado por Google, capaz de crear vídeos cortos realistas y de alta calidad a partir de prompts de texto. Esta sección te ayudará a entender cómo usar la API de VEO 2.0 para generar vídeos, incluida la configuración de parámetros, la selección de modelo y ejemplos de código.Parámetros del modelo
VEO 2.0 ofrece los siguientes parámetros:- numberOfVideos: El número de vídeos a generar; las opciones son 1 o 2. Por defecto 2.
- aspectRatio: La relación de aspecto de los vídeos generados. Los valores admitidos son “16:9” y “9:16”.
- durationSeconds: Duración del vídeo; las opciones son 5 segundos u 8 segundos. Por defecto 8 segundos.
- personGeneration: Controla si se permiten vídeos que contengan personas. Admite los siguientes valores:
- “dont_allow”: Evita la generación de vídeos que contengan personas.
- “allow_adult”: Permite la generación de vídeos que contengan adultos, pero no niños.
Precios
El coste de la API de VEO 2.0 es de $0.35/sEjemplo de uso
A continuación, un ejemplo en Python para usar VEO 2.0 para generar vídeos:Consejos para prompts
Crear prompts eficaces es fundamental para obtener los vídeos deseados:- Describe escenas, acciones y ambiente claros
- Especifica estilos de filmación (como panorámico, primer plano, planos de seguimiento, etc.)
- Describe las condiciones de iluminación (como soleado, atardecer, iluminación interior, etc.)
- Especifica el sujeto principal y sus acciones (p. ej., “un gatito durmiendo bajo el sol”)
- Evita narrativas demasiado complejas o escenas que cambien rápidamente
- Evita contenidos negativos o prohibidos
Buenas prácticas
- Prompts claros y concisos: Usa descripciones claras y específicas para guiar la generación del vídeo.
- La paciencia es clave: La generación de vídeo tarda 2-3 minutos; espera a que se complete.
- Prueba diferentes parámetros: Experimenta con diferentes relaciones de aspecto y duraciones para encontrar los ajustes que mejor se adapten a tus necesidades.
- Guarda los registros de generación: Registra los prompts junto con los vídeos generados para hacer seguimiento de los resultados exitosos.
- Cumple con las políticas de uso: Asegúrate de que tu uso cumple con las políticas de contenido y los términos de uso de Google.
Última actualización: 2026-06-01