El umbral mínimo de tokens que se pueden almacenar en caché varía según el modelo de Claude (512 / 1.024 / 2.048 / 4.096) y no es proporcional a la versión del modelo: por ejemplo, Claude Opus 4.8 es 1.024, Claude Opus 4.7 es 2.048, y Claude Opus 4.6 / 4.5 y Claude Haiku 4.5 son 4.096. El desglose completo está más abajo, en «Limitaciones de la caché». El contenido por debajo del umbral no se escribe en caché aunque esté marcado con
cache_control, y tampoco genera error.Cómo funciona la caché de prompts
Cuando envías una solicitud con la caché de prompts habilitada:- El sistema comprueba si un prefijo del prompt, hasta un punto de corte de caché especificado, ya está almacenado en caché de una consulta reciente.
- Si lo encuentra, utiliza la versión en caché, reduciendo el tiempo de procesamiento y los costos.
- De lo contrario, procesa el prompt completo y almacena en caché el prefijo cuando comienza la respuesta. Esto es especialmente útil para:
- Prompts con muchos ejemplos
- Grandes cantidades de contexto o información de fondo
- Tareas repetitivas con instrucciones consistentes
- Conversaciones largas de múltiples turnos
Error común: caché que “solo escribe pero nunca lee”
El escenario de fallo más habitual es este: en cada turno el valor decache_creation_input_tokens es grande (siempre se está escribiendo en caché), pero cache_read_input_tokens se mantiene en 0 (nunca se lee), lo que equivale a no ahorrar nada.
La causa raíz es una sola: el contenido anterior al punto de corte de caché (cache_control) cambió entre dos solicitudes. Un acierto de caché requiere que el punto de corte y todo lo que va antes de él (en el orden tools → system → messages) sean idénticos byte a byte; basta con que cambie un solo carácter antes del punto de corte para que toda la caché del prefijo se invalide y se reescriba.
❌ Forma incorrecta: poner la pregunta que cambia en cada turno antes del punto de corte
✅ Forma correcta: el documento extenso primero + punto de corte + la pregunta al final
Comparación medida (claude-opus-4-6, intervalo de unos segundos entre las dos llamadas)
Puntos clave:
- Coloca el bloque grande e invariable (documento de referencia, contexto extenso) en la parte más al frente del mensaje
userdemessages, con elcache_controlmarcado al final de ese bloque; ese contenido no puede cambiar ni un carácter. - Pon la pregunta/instrucción que cambia en cada turno después del punto de corte (en el mismo mensaje
user, tras el documento extenso, o en mensajes posteriores); en las conversaciones de múltiples turnos solo añade contenido al final y no vuelvas a modificar los mensajes históricos. - Cuando
thinkingestá activado, los bloques de razonamiento de los turnos históricos del asistente deben devolverse tal cual; de lo contrario el prefijo también se rompe (ver más abajo “Qué no se puede almacenar en caché”). - Si un bloque es menor que el umbral mínimo de caché (varía entre 512 y 4.096 tokens según el modelo, ver más abajo “Limitaciones de la caché”), no se escribirá en caché aunque esté marcado con
cache_control; este es el comportamiento esperado.
Precios
La caché de prompts introduce una nueva estructura de precios. La siguiente tabla muestra el precio por millón de tokens para cada modelo admitido:
Nota:
- Los tokens de escritura en caché de 5 minutos cuestan 1,25 veces el precio de los tokens de entrada base
- Los tokens de escritura en caché de 1 hora cuestan 2 veces el precio de los tokens de entrada base
- Los tokens de lectura de caché cuestan 0,1 veces el precio de los tokens de entrada base
- Los tokens regulares de entrada y salida tienen los precios estándar de la plataforma
Cómo implementar la caché de prompts
Modelos admitidos
Toda la gama de modelos Claude de Anthropic admite la caché de prompts, incluidos los modelos actuales Claude Opus 4.8 / 4.7 / 4.6 / 4.5, Claude Sonnet 5 / 4.6 / 4.5, Claude Haiku 4.5 y Claude Fable 5, así como los modelos anteriores Claude Opus 4, Sonnet 4, Sonnet 3.7, Sonnet 3.5, Haiku 3.5, Haiku 3 y Opus 3. El umbral mínimo de tokens que se pueden almacenar en caché de cada modelo está más abajo, en «Limitaciones de la caché».Caché automática (cache_control de nivel superior)
Añade un campocache_control en el nivel superior del cuerpo de la solicitud para habilitar la caché automática: el sistema aplica automáticamente el punto de corte de caché al último bloque cacheable y lo desplaza hacia adelante a medida que crece la conversación, lo que resulta adecuado para la caché deslizante en conversaciones de múltiples turnos. El punto de corte automático ocupa 1 de los 4 espacios de puntos de corte y puede combinarse con puntos de corte explícitos a nivel de bloque. Amazon Bedrock no admite la caché automática.
Estructuración de tu prompt
Coloca el contenido estático (definiciones de herramientas, instrucciones del sistema, contexto, ejemplos) al principio de tu prompt. Marca el final del contenido reutilizable para almacenarlo en caché usando el parámetrocache_control.
Los prefijos de caché se crean en el siguiente orden: tools, system y, después, messages.
Usando el parámetro cache_control, puedes definir hasta 4 puntos de corte de caché, lo que te permite almacenar en caché por separado distintas secciones reutilizables. Para cada punto de corte, el sistema comprobará automáticamente si hay aciertos de caché en posiciones previas y usará el prefijo coincidente más largo si lo encuentra.
Limitaciones de la caché
La longitud mínima del prompt que se puede almacenar en caché varía según el modelo y no es proporcional a la versión:
Los prompts más cortos no se pueden almacenar en caché, aunque estén marcados con
cache_control. Cualquier solicitud para almacenar en caché menos tokens que esta cifra se procesará sin caché. Para comprobar si un prompt se almacenó en caché, consulta los campos de uso de la respuesta.
Para solicitudes concurrentes, ten en cuenta que una entrada de caché solo está disponible después de que comience la primera respuesta. Si necesitas aciertos de caché para solicitudes en paralelo, espera la primera respuesta antes de enviar las solicitudes posteriores.
Vidas útiles de caché admitidas actualmente:
- “ephemeral”: Vida útil predeterminada de 5 minutos
- Caché de 1 hora: Establece
"ttl": "1h"encache_control, para escenarios que requieran una duración de caché más larga
Duración de caché de 1 hora
Para escenarios que requieran una duración de caché más larga, ofrecemos una opción de caché de 1 hora. Basta con incluirttl en la definición de cache_control; no se requiere ningún encabezado adicional:
Cuándo usar la caché de 1 hora
La caché de 1 hora es especialmente adecuada para:- Procesamiento por lotes: Procesar grandes volúmenes de solicitudes con prefijos comunes
- Sesiones de larga duración: Conversaciones que requieren mantener el contexto durante periodos prolongados
- Análisis de documentos grandes: Múltiples tipos diferentes de análisis sobre el mismo documento
- Preguntas y respuestas sobre código: Múltiples consultas sobre la misma base de código a lo largo de periodos prolongados
Combinando distintos TTL
Puedes combinar diferentes duraciones de caché dentro de la misma solicitud:Qué se puede almacenar en caché
Cada bloque de la solicitud puede designarse para almacenarlo en caché con cache_control. Esto incluye:- Herramientas: Definiciones de herramientas en el array
tools - Mensajes del sistema: Bloques de contenido en el array
system - Mensajes: Bloques de contenido en el array
messages.content, tanto en los turnos del usuario como en los del asistente - Imágenes y documentos: Bloques de contenido en el array
messages.content, en los turnos del usuario - Uso de herramientas y resultados de herramientas: Bloques de contenido en el array
messages.content, tanto en los turnos del usuario como en los del asistente
cache_control para habilitar el almacenamiento en caché de esa parte de la solicitud.
Qué no se puede almacenar en caché
Aunque la mayoría de los bloques de la solicitud pueden almacenarse en caché, hay algunas excepciones:- Los bloques de razonamiento (thinking) no pueden almacenarse en caché directamente con
cache_control. Sin embargo, los bloques de razonamiento SÍ pueden almacenarse en caché junto con otro contenido cuando aparecen en turnos anteriores del asistente. Cuando se almacenan así, SÍ cuentan como tokens de entrada cuando se leen de la caché. - Los subbloques de contenido (como las citas) no pueden almacenarse en caché directamente por sí mismos. En su lugar, almacena en caché el bloque de nivel superior.
- Los bloques de texto vacíos no se pueden almacenar en caché.
Seguimiento del rendimiento de la caché
Monitoriza el rendimiento de la caché usando estos campos de la respuesta de la API, dentro deusage en la respuesta (o en el evento message_start si usas streaming):
cache_creation_input_tokens: Número de tokens escritos en la caché al crear una nueva entrada.cache_read_input_tokens: Número de tokens recuperados de la caché para esta solicitud.input_tokens: Número de tokens de entrada que no se leyeron desde la caché ni se usaron para crear una caché.
Buenas prácticas para una caché eficaz
Para optimizar el rendimiento de la caché de prompts:- Almacena en caché contenido estable y reutilizable como instrucciones del sistema, información de fondo, contextos extensos o definiciones de herramientas frecuentes.
- Coloca el contenido en caché al principio del prompt para obtener el mejor rendimiento.
- Usa los puntos de corte de caché de forma estratégica para separar distintas secciones de prefijo cacheables.
- Analiza regularmente las tasas de acierto de caché y ajusta tu estrategia según sea necesario.
- Para contenido a largo plazo, considera usar la caché de 1 hora para una mejor eficiencia de costos.
Optimización para distintos casos de uso
Adapta tu estrategia de caché de prompts a tu escenario:- Agentes conversacionales: Reduce el costo y la latencia en conversaciones extensas, especialmente aquellas con instrucciones largas o documentos cargados.
- Asistentes de programación: Mejora el autocompletado y las preguntas y respuestas sobre la base de código manteniendo en el prompt las secciones relevantes o una versión resumida de la base de código.
- Procesamiento de documentos grandes: Incorpora material extenso completo, incluidas imágenes, en tu prompt sin aumentar la latencia de la respuesta.
- Conjuntos de instrucciones detallados: Comparte listas exhaustivas de instrucciones, procedimientos y ejemplos para afinar las respuestas de Claude. Los desarrolladores suelen incluir uno o dos ejemplos en el prompt, pero con la caché de prompts puedes obtener un rendimiento aún mejor incluyendo más de 20 ejemplos diversos de respuestas de alta calidad.
- Uso agentic de herramientas: Mejora el rendimiento en escenarios que involucran múltiples llamadas a herramientas y cambios iterativos de código, donde cada paso suele requerir una nueva llamada a la API.
- Conversar con libros, papers, documentación, transcripciones de podcasts y otro contenido extenso: Da vida a cualquier base de conocimiento incrustando los documentos completos en el prompt y dejando que los usuarios hagan preguntas.
Solución de problemas comunes
Si experimentas un comportamiento inesperado:- Asegúrate de que las secciones cacheadas sean idénticas y estén marcadas con cache_control en las mismas ubicaciones en todas las llamadas
- Comprueba que las llamadas se realicen dentro de la vida útil de la caché (5 minutos o 1 hora)
- Verifica que
tool_choicey el uso de imágenes se mantengan consistentes entre las llamadas - Valida que estás almacenando en caché al menos el número mínimo de tokens
- Aunque el sistema intentará utilizar el contenido cacheado previamente en las posiciones anteriores a un punto de corte de caché, puedes usar un parámetro
cache_controladicional para garantizar la búsqueda en caché en porciones previas del prompt, lo que puede ser útil en consultas con listas muy largas de bloques de contenido
Almacenamiento y compartición de la caché
- Aislamiento por organización: Las cachés están aisladas entre organizaciones. Distintas organizaciones nunca comparten cachés, incluso si usan prompts idénticos.
- Coincidencia exacta: Los aciertos de caché requieren segmentos de prompt 100 % idénticos, incluido todo el texto e imágenes hasta el bloque marcado con cache_control. El mismo bloque debe marcarse con cache_control tanto en la lectura como en la creación de la caché.
- Generación de tokens de salida: La caché de prompts no afecta a la generación de tokens de salida. La respuesta que recibirás será idéntica a la que obtendrías sin caché de prompts.
Habilitar la caché de Claude en clientes / plataformas
La interfaz de muchos clientes no tiene un lugar donde rellenar directamentecache_control, sino que usa su propio “azúcar sintáctico” o interruptores para inyectarlo por ti. La regla de fondo es exactamente la misma que arriba: el prefijo que se almacena en caché debe ser idéntico carácter a carácter en cada turno, y el contenido que cambia debe ir después del punto de corte de caché; de lo contrario, “solo se escribe pero nunca se lee” (ver “Error común” más arriba).
Dify (mediante el plugin de Aihubmix)
El plugin de Dify de Aihubmix hereda el azúcar sintáctico del plugin oficial de Anthropic, y se habilita en dos pasos:- Envuelve el prompt que quieres almacenar en caché (el prompt de sistema fijo e invariable / contexto extenso) con
<cache>…</cache>; el plugin lo convertirá automáticamente en un punto de corte decache_controlen ese lugar. - En los parámetros del modelo, establece el “umbral de caché automática para mensajes grandes” en un entero positivo: la caché solo se escribe realmente cuando el contenido alcanza ese umbral de tokens (sigue sujeto a la restricción mínima de caché de “Limitaciones de la caché” más abajo, 4096 tokens para Opus 4.5/4.6 y Haiku 4.5); con 0 o vacío se desactiva.
Cherry Studio
Cuando Cherry Studio llama a Claude a través de Aihubmix, la caché no está activada por defecto (el “umbral de tokens de caché” es0 por defecto); hay que activarla en la “API Settings” del proveedor.
- Haz clic en el engranaje a la derecha del nombre del proveedor Aihubmix para abrir “API Settings”:
- Configura los tres elementos siguientes; el cliente inyectará automáticamente
cache_controlpara Claude en función de ellos:
- Cache Token Threshold: solo inyecta el punto de corte de caché cuando el contenido supere ese número de tokens (un número positivo lo activa; 0 o vacío lo desactiva).
- Cache System Message: al activarlo, marca un punto de corte de caché en el mensaje
system(ideal para almacenar en caché un prompt de sistema largo y fijo). - Cache Last N Messages: marca un punto de corte de caché en los últimos N mensajes (ideal para una caché deslizante en conversaciones de múltiples turnos).
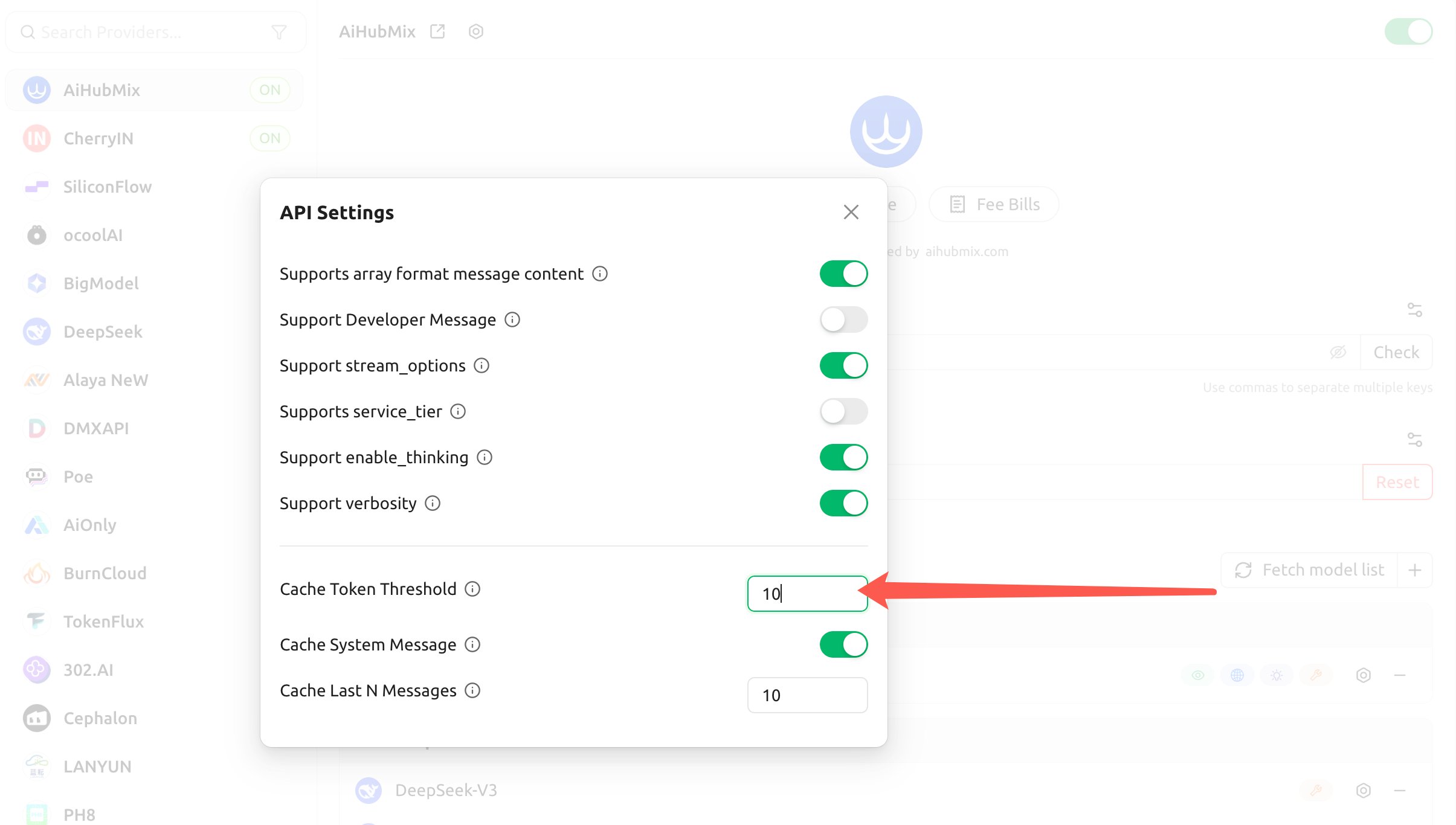
Los umbrales anteriores solo deciden “cuándo inyecta el cliente el punto de corte”, y no cambian el requisito mínimo de caché de Anthropic: la escritura real sigue requiriendo que el contenido almacenado en caché alcance el mínimo de tokens de caché (4096 para Opus 4.5/4.6 y Haiku 4.5). Si pones contenido que cambia en cada turno (como instrucciones rotativas) dentro del prompt de sistema almacenado en caché, igualmente “solo se escribirá pero nunca se leerá”.
Preguntas frecuentes (FAQ)
¿Por qué escribo en caché (cache_creation_input_tokens es grande) pero nunca leo (cache_read_input_tokens es 0)?
Porque el contenido anterior al punto de corte de caché (cache_control) cambió entre dos solicitudes. Un acierto requiere que el punto de corte y todo lo que va antes sean idénticos byte a byte; en cuanto pones contenido que cambia en cada turno antes del punto de corte, toda la caché del prefijo se invalida y se reescribe en cada turno. Pon el contenido fijo al principio y el contenido cambiante después del punto de corte; ver más arriba “Error común”.
¿Cuántos tokens como mínimo necesita la caché?
El contenido por debajo de la longitud mínima de caché no se almacena, aunque esté marcado concache_control. Claude Opus 4.5/4.6 y Haiku 4.5 requieren 4096 tokens; la mayoría de los demás modelos de Claude requieren 1024 tokens, y Haiku 3/3.5 requieren 2048 tokens. Ver más arriba “Limitaciones de la caché”.
¿Cuánto dura la caché? ¿Se puede cambiar a 1 hora?
Por defecto 5 minutos, y se renueva sin coste en cada acierto. Si necesitas más tiempo, establece"ttl": "1h" en cache_control; no se requiere ningún encabezado adicional. La escritura en caché de 1 hora se factura a 2 veces el precio de entrada base. Ver más arriba “Duración de caché de 1 hora”.
¿Cómo activo la caché en Dify / Cherry Studio?
Estos clientes no rellenancache_control directamente: Dify envuelve el contenido a almacenar en caché con <cache>…</cache> y establece el “umbral de caché automática para mensajes grandes”; Cherry Studio configura “Cache Token Threshold / Cache System Message / Cache Last N Messages” en la “API Settings”. Ver más arriba “Habilitar la caché de Claude en clientes / plataformas”.
Soporte en distintos modelos
- Si Prompt Caching está admitido o no depende del propio modelo.
- Si el modelo admite inherentemente la caché sin necesidad de declaraciones de parámetros explícitas, puede admitirse mediante el reenvío compatible con OpenAI.
- OpenAI admite Prompt Caching por defecto, con activación automática (prefijo ≥1024 tokens). En los modelos anteriores a GPT-5.6, la escritura en caché no tiene cargo adicional y la caché se borra automáticamente tras 5-10 minutos de inactividad; en GPT-5.6 y posteriores, la escritura en caché se factura a 1,25 veces el precio de entrada, la lectura a 0,1 veces, la caché se conserva al menos 30 minutos y se admiten puntos de corte de caché explícitos. Detalles en Caché de prompts de GPT.
- Claude requiere la declaración nativa
cache_control: { type: "ephemeral" }. La tasa de almacenamiento es 1,25 veces el costo de entrada estándar (5 minutos) o 2 veces (1 hora), la recuperación de tokens cacheados cuesta 0,1 veces la tarifa normal, con un ciclo de vida de 5 minutos o 1 hora. Detalles - Deepseek V3 y R1 admiten la caché de forma nativa. La tasa de almacenamiento equivale al costo de entrada estándar y la recuperación de tokens cacheados cuesta 0,1 veces la tarifa normal. Detalles
- Soporte de caché implícita de Gemini:
- Caché implícita: Habilitada por defecto para todos los modelos Gemini 2.5. Si tu solicitud acierta en la caché, los ahorros de costo se aplican automáticamente. Esta función entró en vigor el 8 de mayo de 2025. El recuento mínimo de tokens de entrada para la caché de contexto es de 1.024 para Gemini 2.5 Flash y de 2.048 para Gemini 2.5 Pro.
- Consejos para mejorar la tasa de aciertos de la caché implícita:
- Intenta colocar al principio del prompt el contenido extenso y de uso frecuente.
- Intenta enviar solicitudes con prefijos similares dentro de una ventana de tiempo corta.
- Puedes ver el número de tokens con acierto de caché en el campo
usage_metadatadel objeto de respuesta. - Los ahorros de costos se calculan según los aciertos de caché en prefill. Solo la caché de prefill y la caché de preprocesamiento de vídeo de YouTube son elegibles para la caché implícita.
Última actualización: 2026-07-10