No dejes que una caída del upstream se convierta en tu propia caída.AIHubMix ofrece dos capacidades a nivel de Key. Configúralas una vez en la consola y entran en vigor sin cambiar nada en el código del cliente:
- El mapeo de modelos es la capacidad de la capa del gateway que reescribe el alias de modelo de la solicitud del cliente en el modelo real del upstream.
- El fallback ante errores es la capacidad por la que, cuando la llamada al modelo principal falla, el gateway prueba automáticamente modelos de respaldo en un orden de prioridad preconfigurado, de forma transparente para el cliente.
AIHubMix permite configurar el mapeo de nombres de modelo y el fallback ante errores a nivel de Key, y factura según el modelo que finalmente responde. Ambos se configuran por API Key en la página de gestión de Keys de AIHubMix.
Model name mapping y Fallback models on error del panel:
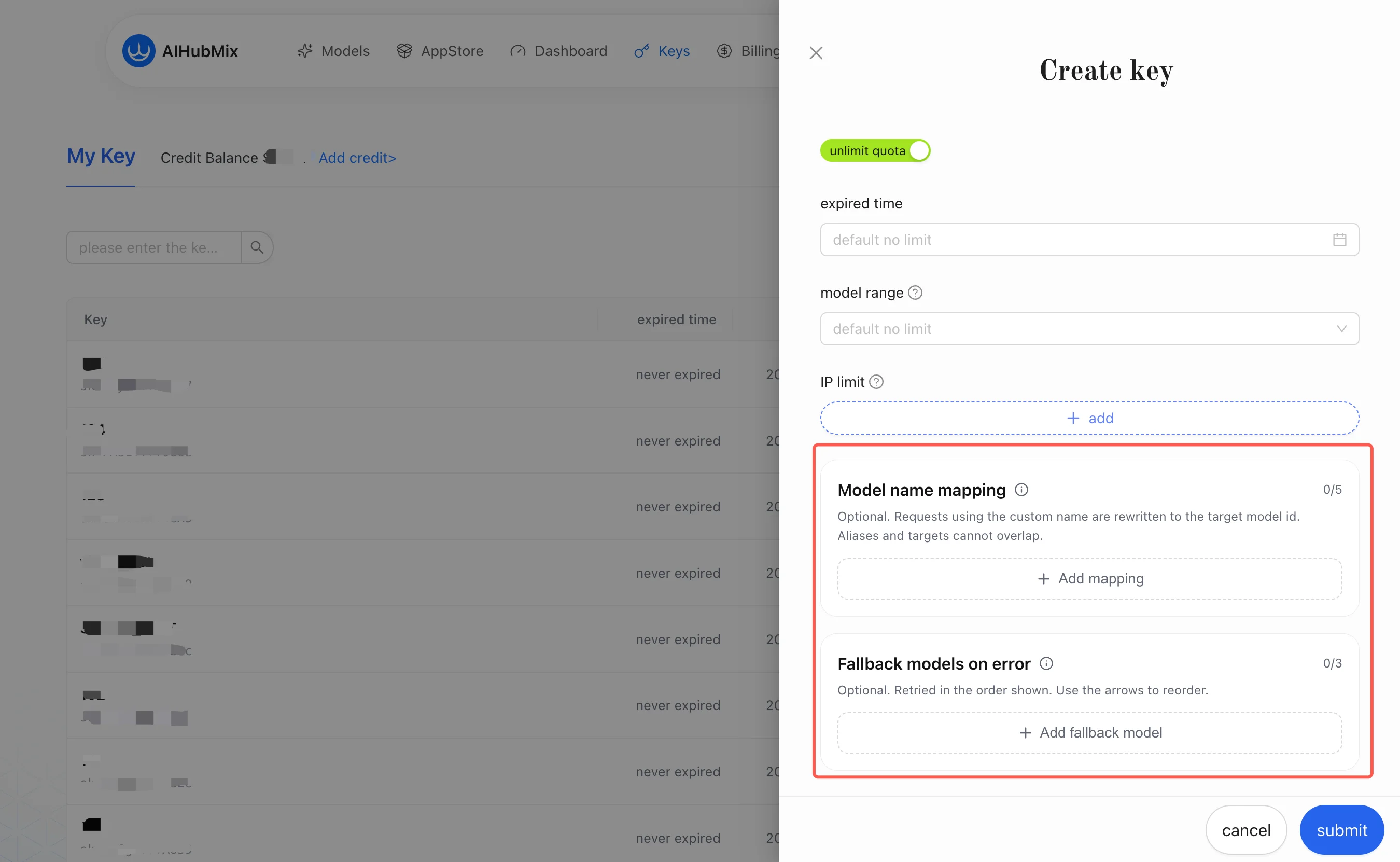
1. Mapeo de nombres de modelo
El mapeo de nombres de modelo resuelve la discrepancia entre “el nombre de modelo que ve el cliente” y “el modelo que AIHubMix realmente llama”. Es una reescritura de alias por key: reescribe el alias de la solicitud en el modelo de destino que configuraste en la Key.Una vez seleccionado un canal para el modelo de destino, la plataforma realiza internamente otro mapeo a nivel de canal hacia el modelo real del upstream. Esa capa es transparente para ti y no requiere configuración. Solo necesitas preocuparte por la capa “alias → modelo de destino”.Ejemplo:
Todos los nombres de modelo de la tabla anterior se pueden consultar en la página de modelos de AIHubMix.Usos comunes:
- El cliente restringe el formato del nombre de modelo. Por ejemplo, Claude Desktop exige nombres de modelo al estilo Claude (consulta la Sección 5).
- Asignar un alias más corto y estable a un Model ID complejo.
- Mantener la configuración del cliente sin cambios mientras se cambia el modelo real en el backend de AIHubMix.
- Varias plataformas comparten un mismo esquema de nombres de conexión pero enrutan a modelos distintos según la Key.
Coincidencia carácter por carácter: El nombre de modelo que envía el cliente debe coincidir con el lado izquierdo del mapeo carácter por carácter. Por ejemplo,my-gpt-5.5ymy-gpt-5-5son dos cadenas diferentes; si no coinciden, el mapeo no se activará.
2. Fallback ante errores
El fallback ante errores prueba modelos de respaldo en orden cuando el modelo principal falla. No es un reintento del lado del cliente; es un cambio de modelo realizado en el lado del gateway de AIHubMix bajo la misma configuración de Key. El integrador no necesita pasar ningún parámetro de enrutamiento adicional en cada solicitud. Puedes pensar en el fallback como un “mapeo a una lista ordenada”: después de que el modelo principal falla, el gateway avanza automáticamente por la lista hasta el siguiente modelo de respaldo. Ejemplo (configurado en la misma Key):2.1 Condiciones de activación
El fallback solo ocurre cuando se cumplen todas las siguientes condiciones:- La Key tiene configurada una lista de modelos de respaldo no vacía.
- Todos los canales del modelo principal se han probado y todos fallaron con un “error reintentable” (canales agotados).
- La respuesta aún no ha comenzado a devolverse (el primer byte / la cabecera aún no se ha enviado al cliente).
- El error no es un error a nivel de Key / usuario (consulta la tabla comparativa 2.2 más abajo).
2.2 Qué hace fallback y qué no
Nota: “Key inválida” aquí significa que tu propia Key de AIHubMix es inválida, lo que no hace fallback. Si la key de algún canal del upstream está rota, el gateway cambia de canal, y tras agotar los canales todavía puede hacer fallback. No confundas ambos casos.
2.3 Base de facturación
Se factura según el modelo que finalmente responde. Si el modelo de fallback responde en última instancia, la facturación, las capacidades y los límites de contexto se basan todos en el modelo que finalmente responde. Ese modelo también se refleja en la cabecera de respuesta (consulta la Sección 4).2.4 Regla del modelo gratuito
Un modelo gratuito no puede usarse como opción de fallback — un modelo gratuito solo puede ser el modelo principal. Ponerlo en la lista de respaldo provoca que se omita silenciosamente y el gateway continúa con la siguiente entrada. Por lo tanto, no pongas modelos gratuitos en la lista de fallback.Uso típico: Configura un modelo gratuito como modelo principal y pon modelos de pago en la lista de respaldo. Cuando el modelo principal gratuito alcanza una cuota / límite de tasa, hace fallback automáticamente a un modelo de respaldo de pago. Normalmente ahorras costes usando la cuota gratuita, y tras el límite de tasa cambias sin interrupciones a un modelo de pago para garantizar la disponibilidad. Este es uno de los usos más comunes del fallback.
3. AIHubMix frente a OpenRouter / LiteLLM
El mapeo de modelos y el fallback no son conceptos nuevos; OpenRouter, LiteLLM y otros ofrecen capacidades similares. Lo que distingue a AIHubMix es el menor coste de configuración:
En una frase: Sin gateway propio, sin cambiar ni una sola línea de código del cliente — configúralo una vez en la Key y entra en vigor.
4. Configuración y verificación
4.1 Configuración
- Configura el mapeo de alias en la Key: el alias de la izquierda debe coincidir carácter por carácter con el nombre de modelo que el cliente envía realmente.
- Configura la lista de modelos de respaldo (una lista de prioridad ordenada) en la misma Key.
- La lista de respaldo debe contener únicamente modelos de pago / disponibles, no modelos gratuitos (se omitirán).
- Los modelos de la lista de respaldo deben estar dentro del rango de modelos disponibles de la Key (los modelos fuera de rango se omitirán).
4.2 Verificación — revisa primero las cabeceras de respuesta, no los logs
Al diagnosticar un problema, no te fijes solo en qué modelo seleccionó el cliente. La forma más autoritativa y automatizable es leer las cabeceras de respuesta:X-Aihubmix-Fallback: true: en esta solicitud ocurrió un fallback (se añade cuando el modelo final ≠ el modelo principal).X-Aihubmix-Model: el modelo que realmente respondió en esta solicitud y según el cual se facturó.
5. Escenario uno Claude Desktop
Claude Desktop se conecta a AIHubMix a través deGateway, un escenario típico para el mapeo de nombres de modelo.
Esta sección asume que ya has completado la integración básica de Claude Desktop. Para los pasos completos de integración (descarga e instalación, modo desarrollador, configuración de Gateway, esquema de autenticación, etc.), consulta Conectar AIHubMix en Claude Desktop. Esta sección solo cubre la configuración incremental para el mapeo y el fallback.
5.1 Por qué es necesario el mapeo
Claude Desktop se conecta víaGateway (compatible con Anthropic), y el cliente limita los nombres de modelo al estilo Claude, por lo que los nombres de modelo deben usar el prefijo claude-.
Esto crea un conflicto: del lado del cliente solo se pueden escribir nombres al estilo claude-, pero lo que realmente quieres llamar es gpt-5.5, gemini-3.1-pro-preview y similares. El mapeo de nombres de modelo está hecho justo para esto — el cliente escribe el alias claude-g-p-t-5.5 y AIHubMix lo mapea al gpt-5.5 real.
Claude Desktop usa la interfaz nativa de Claude /v1/messages, por lo que en los ejemplos de este artículo tanto el mapeo como el Fallback entran en vigor.
5.2 Configuración de mapeo y Fallback de AIHubMix
Ejemplo de configuración: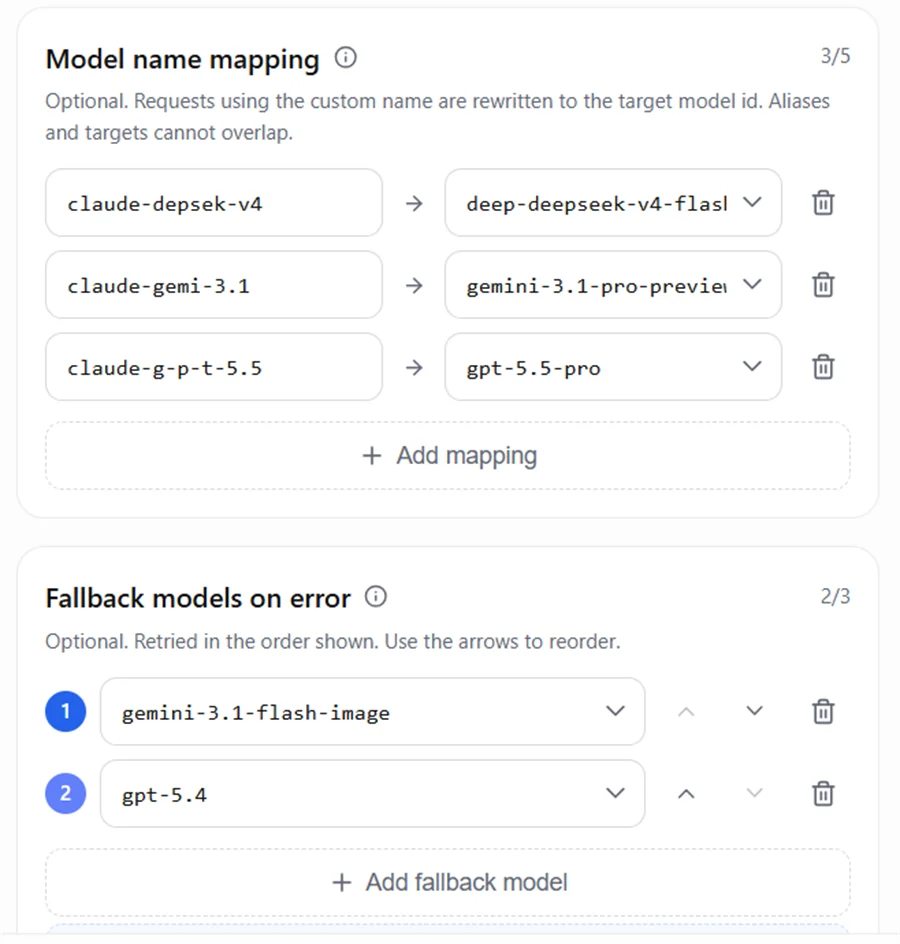
5.3 Lista de modelos de Claude Desktop
Lo que configuras en laModel list de Claude Desktop es el alias antes del mapeo — es decir, el nombre de modelo que Claude Desktop envía a AIHubMix, no el nombre de modelo real del upstream.
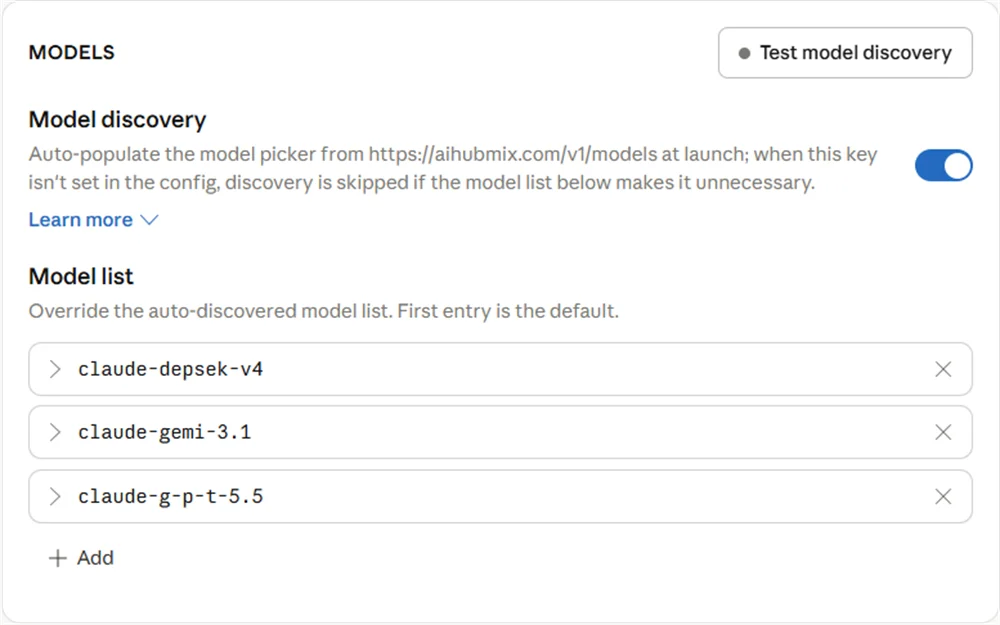
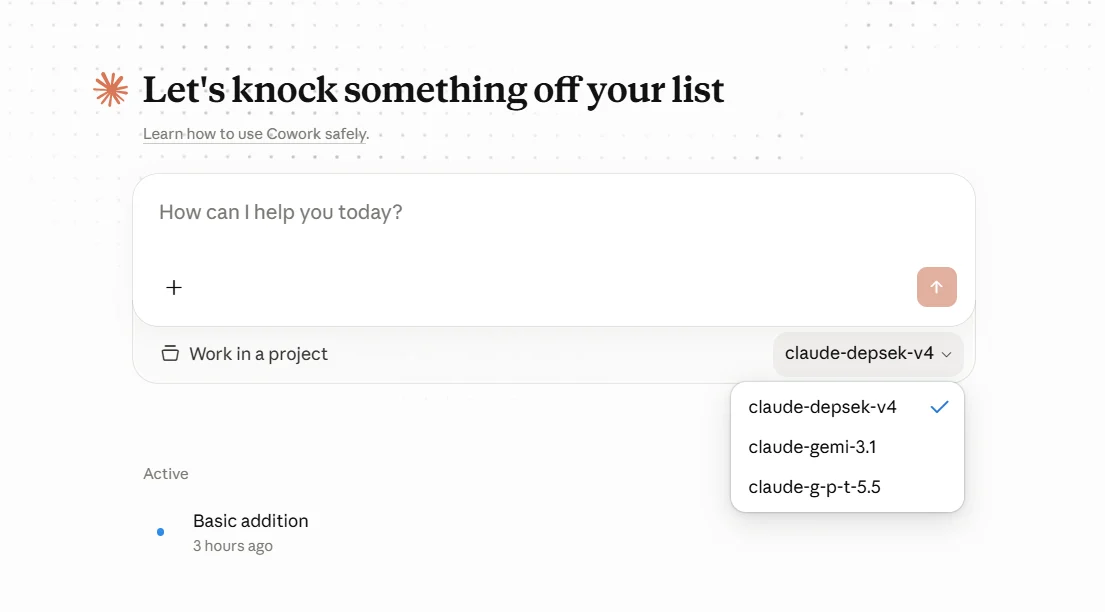
- Usa el prefijo
claude-para elModel ID. - No escribas directamente nombres de familias de modelos reales como
gpt,geminiodeepseek; usa alias comog-p-t,gemi,depsek. - El
Model IDdebe coincidir carácter por carácter con el lado izquierdo del mapeo de AIHubMix; de lo contrario, la solicitud no activará el mapeo esperado y puede continuar hasta el modelo de fallback ante errores.
6. Escenario dos Fallback de capacidad multimodal
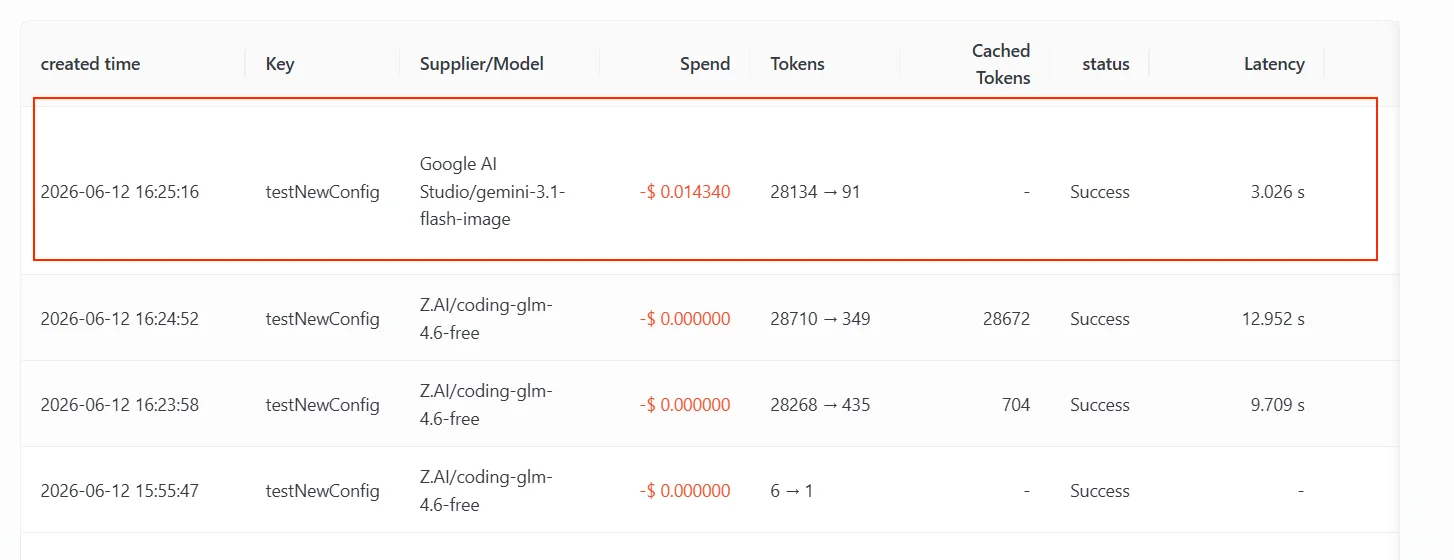
El fallback de capacidad multimodal aborda el escenario en el que “el modelo principal puede responder texto pero no admite el tipo de entrada actual”. Por ejemplo, el cliente envía una imagen o un vídeo mientras que el modelo principal solo tiene capacidad de entrada de texto; AIHubMix puede seguir probando modelos de la lista de fallback que admitan la modalidad correspondiente. A continuación se muestra una ruta de prueba real. La configuración de mapeo y fallback de esta Key es la siguiente (consulta la captura de pantalla más abajo). El punto clave es que la lista de fallback contiene tanto un modelo de texto como un modelo que admite la comprensión de imágenes:claude-g-l-m-4.6 — un modelo que solo admite entrada de texto. El usuario subió una captura de pantalla de la página de la lista de modelos de AIHubMix y preguntó “para qué sirve este sitio web”. Como la solicitud contenía una imagen, el modelo de texto no pudo procesar directamente la entrada, lo que activó el fallback.
Google AI Studio/gemini-3.1-flash-image, la 2.ª entrada de la lista de fallback. La 1.ª entrada, gpt-5.4, tampoco admite esta entrada de imagen y siguió devolviendo un error reintentable para esta solicitud, por lo que el gateway continuó descendiendo y aterrizó en gemini-3.1-flash-image, que admite la comprensión de imágenes.
Ten claro el motivo de la activación: El fallback aquí ocurre porque el upstream devolvió un error reintentable para esta entrada de imagen y los canales del modelo principal se agotaron — es el mismo mecanismo de fallback que “hacer fallback después de que el modelo principal sea limitado en tasa”, solo que activado por un tipo de error distinto (el primero es una entrada no admitida, el segundo es una cuota / límite de tasa).
Distingue comprensión de generación: Esto se refiere al fallback de comprensión de imágenes / vídeo, no a la generación de imágenes o generación de vídeo. Una solicitud de chat no se convierte automáticamente en un endpoint de generación; para probar el dibujo o la generación de vídeo, debes usar el endpoint y el modelo de generación correspondientes. Las capacidades de un modelo se determinan por los Input Modalities marcados actualmente en la página de modelos de AIHubMix.
7. Escenario tres Fallback de modelo gratuito
Este es uno de los usos más comunes del fallback: configurar un modelo gratuito como modelo principal y poner modelos de pago en la lista de respaldo. Normalmente todas las solicitudes pasan por el modelo gratuito y ahorran coste; una vez que el modelo principal gratuito alcanza una cuota / límite de tasa, el gateway hace fallback automáticamente a un modelo de respaldo de pago, garantizando que el servicio no se interrumpa. Ejemplo de configuración de Key:- Mientras la cuota gratuita siga siendo suficiente, la solicitud la responde el modelo principal
coding-glm-5.2-freey se factura como gratuita. - Tras limitar la tasa del modelo principal gratuito, hace fallback automáticamente a
gpt-5.4; sigpt-5.4también está no disponible, prueba entoncesgemini-3.1-pro-preview. - Cualquiera que sea el modelo que finalmente responde es aquel por el que se te factura (consulta 2.3).
Nota: Un modelo gratuito solo puede ser el modelo principal y no puede ponerse en la lista de fallback (si lo haces, se omitirá; consulta 2.4). Por lo tanto, la forma correcta de hacer “fallback de modelo gratuito” es: gratuito como principal, de pago como respaldo, no al revés.La verificación se realiza de nuevo leyendo las cabeceras de respuesta: cuando ocurre un fallback, se devuelve
X-Aihubmix-Fallback: true, y X-Aihubmix-Model muestra el modelo que finalmente responde (consulta la Sección 4).
8. Endpoints admitidos
El mapeo de modelos y el fallback ante errores admiten actualmente las siguientes categorías de interfaz:
Puntos clave:
- El mapeo de modelos y el fallback ante errores admiten tres categorías de interfaz: interfaces compatibles con OpenAI, la interfaz nativa de Claude
/v1/messagesy OpenAI Responses/v1/responses. - Otras interfaces nativas de paso directo (Gemini nativo, Ideogram, vídeo, TTS, Stability, OCR, predictions, etc.), el paso directo a un canal concreto y las interfaces de recuperación por ID de recurso / tipo de archivo aún no se admiten.
- Claude Desktop usa la interfaz nativa de Claude
/v1/messages, por lo que en los ejemplos de este artículo tanto el mapeo como el Fallback entran en vigor.
9. Preguntas frecuentes
P: ¿Qué debo hacer si Claude Desktop muestra que el modelo no se encuentra? R: Comprueba si elModel ID de Claude Desktop coincide carácter por carácter con el lado izquierdo del mapeo de AIHubMix; si no coinciden, el mapeo no se activará.
P: ¿Afecta el fallback a la facturación?
R: Se factura según el modelo que finalmente responde. Cualquiera que sea el modelo que responda en última instancia, se te cobra según el precio, las capacidades y los límites de contexto de ese modelo.
P: ¿Cómo confirmo si esta solicitud realmente usó fallback?
R: Mira las cabeceras de respuesta X-Aihubmix-Fallback: true (ocurrió un fallback) y X-Aihubmix-Model (el modelo que finalmente responde); consulta la Sección 4.
P: ¿Qué errores activan el fallback y cuáles no?
R: Consulta la tabla comparativa 2.2. En resumen: el fallback solo ocurre ante un fallo reintentable del upstream, con los canales agotados y la respuesta aún sin comenzar; un canal concreto, la respuesta ya comenzada, la desconexión / expiración del cliente y los errores a nivel de Key / usuario no hacen fallback.
P: ¿Se puede poner un modelo gratuito en la lista de fallback?
R: No, se omitirá. Un modelo gratuito solo puede ser el modelo principal.
P: ¿En qué se diferencia esto del alias de modelo / fallback de OpenRouter / LiteLLM?
R: AIHubMix es a nivel de Key y gestionado por la plataforma — configúralo una vez en la consola y entra en vigor, sin cambios en el código del cliente y sin un gateway propio. Consulta la Sección 3 para más detalles.
Recursos relacionados
- Conectar AIHubMix en Claude Desktop: pasos completos para el modo desarrollador, la configuración de Gateway, el esquema de autenticación y más.
- Página de modelos de AIHubMix: consulta nombres de modelo, precios e
Input Modalities. - Conectar AIHubMix en LiteLLM: una referencia para cuando necesites un gateway propio + mapeo / fallback de modelos.