Instalación con un clic para el plugin de Aihubmix
Solo tienes que hacer clic en el enlace siguiente y pulsar el botón Install en la página del Marketplace de Dify: 👉 Ir a la página del plugin de Dify Imagen de ejemplo: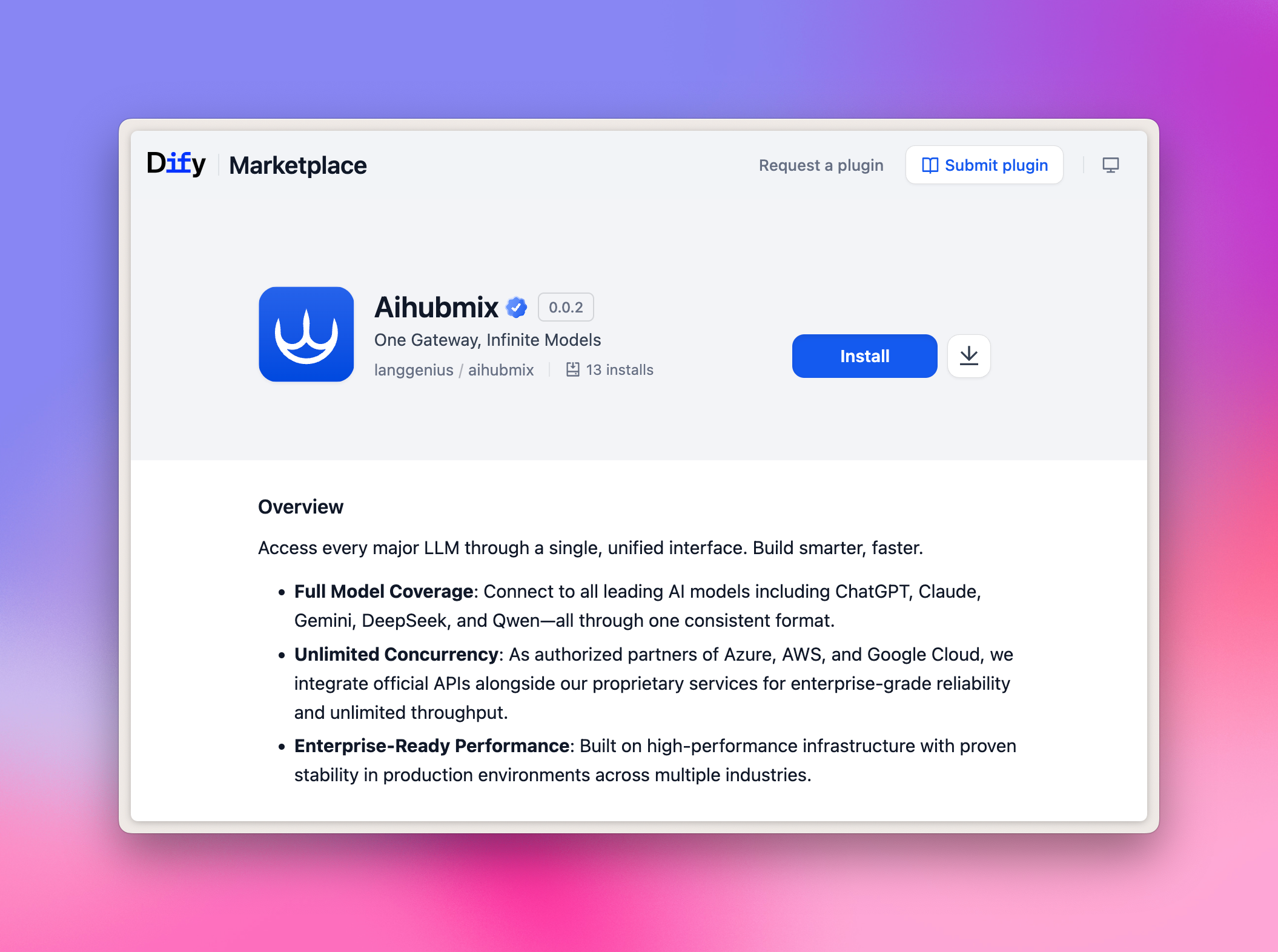
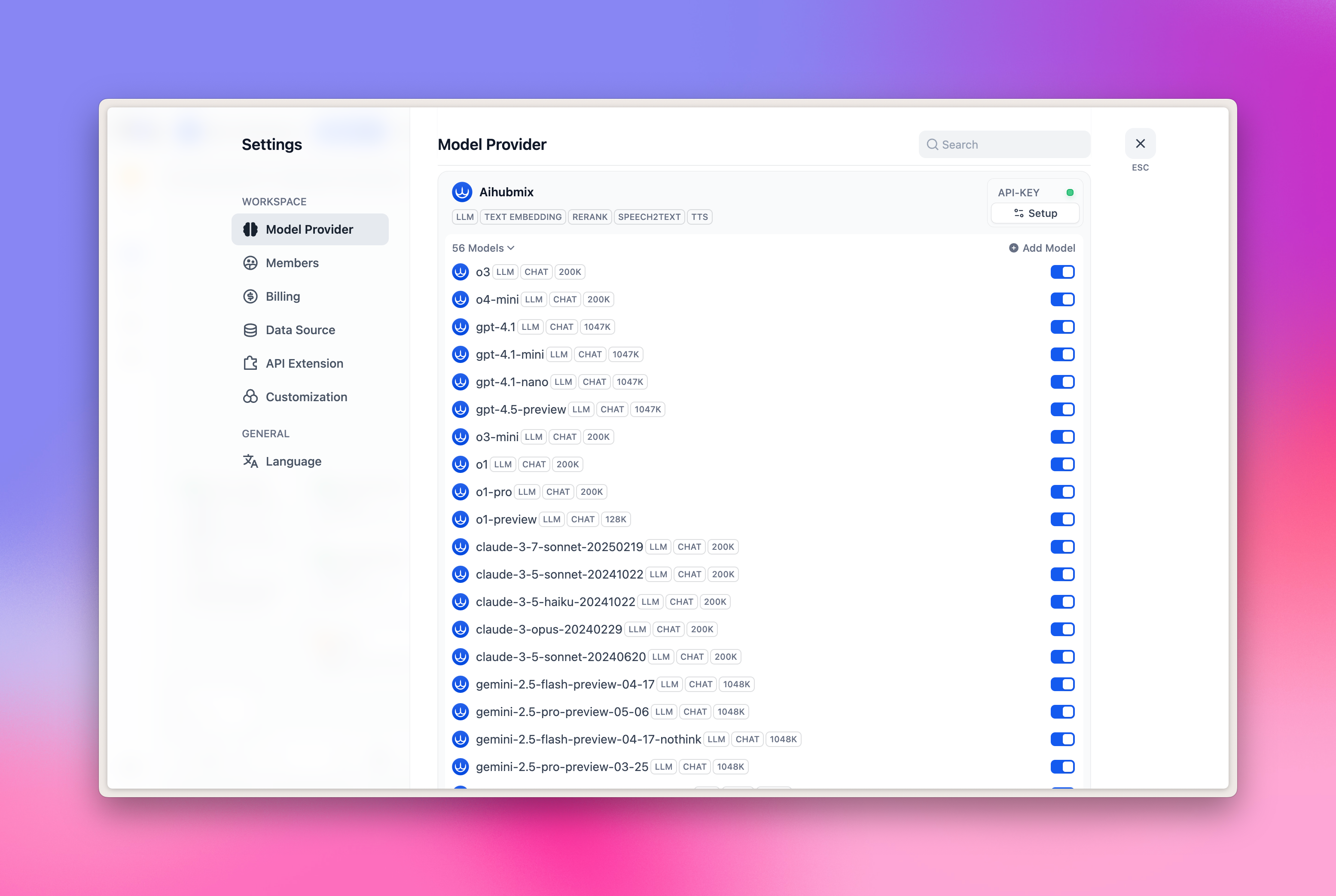
Configuración
- Haz clic en el avatar de la parte superior derecha de la página → Selecciona “Settings”
- Haz clic en la pestaña “Model Provider”
- Busca Aihubmix en el lado derecho → Expande Setup e introduce tu clave API
 Actualmente, las siguientes 5 categorías de modelos están preconfiguradas:
Actualmente, las siguientes 5 categorías de modelos están preconfiguradas:
- LLM: Modelo de lenguaje grande
- TEXT EMBEDDING: Modelo de embeddings vectoriales
- RERANK: Modelo de reordenamiento
- SPEECH2TEXT: Modelo de voz a texto
- TTS: Modelo de texto a voz
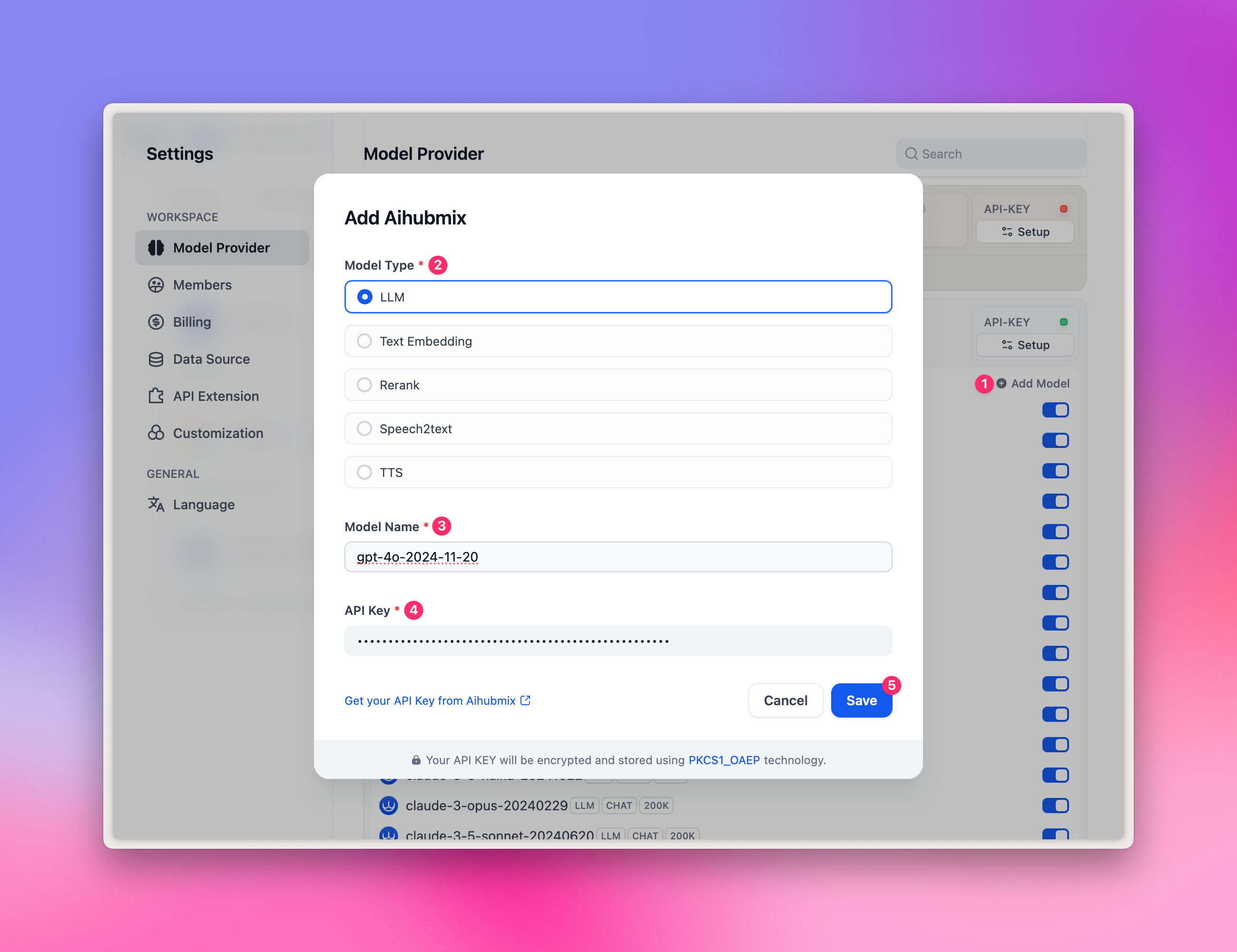
- Introduce cualquier ID de modelo de la galería de modelos, como
gpt-4o-2024-11-20. - Introduce tu clave API y haz clic en “Save”.
gpt-image-1.
Selección de LLM
En el nodo del flujo de trabajo (Workflow), selecciona “LLM” y podrás elegir los modelos proporcionados por Aihubmix. Imagen de ejemplo: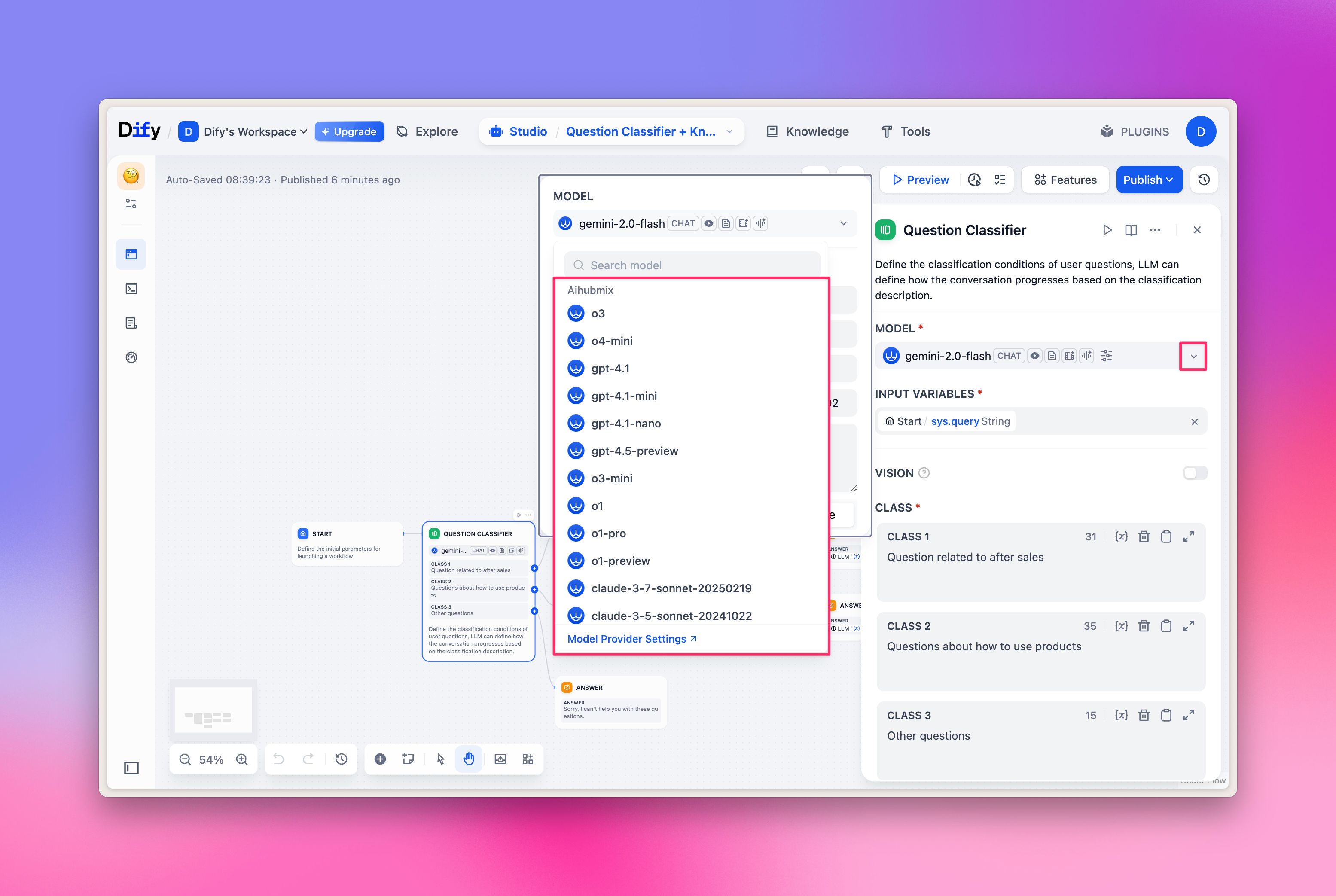
Selección de modelos de Embeddings/Reranker
Los modelos de Embeddings/Reranker se utilizan principalmente para la respuesta a preguntas sobre bases de conocimiento; puedes probarlo rápidamente en la pestaña superior Knowledge, y también seleccionar el modelo correspondiente en el nodo del flujo de trabajo. Imagen de ejemplo: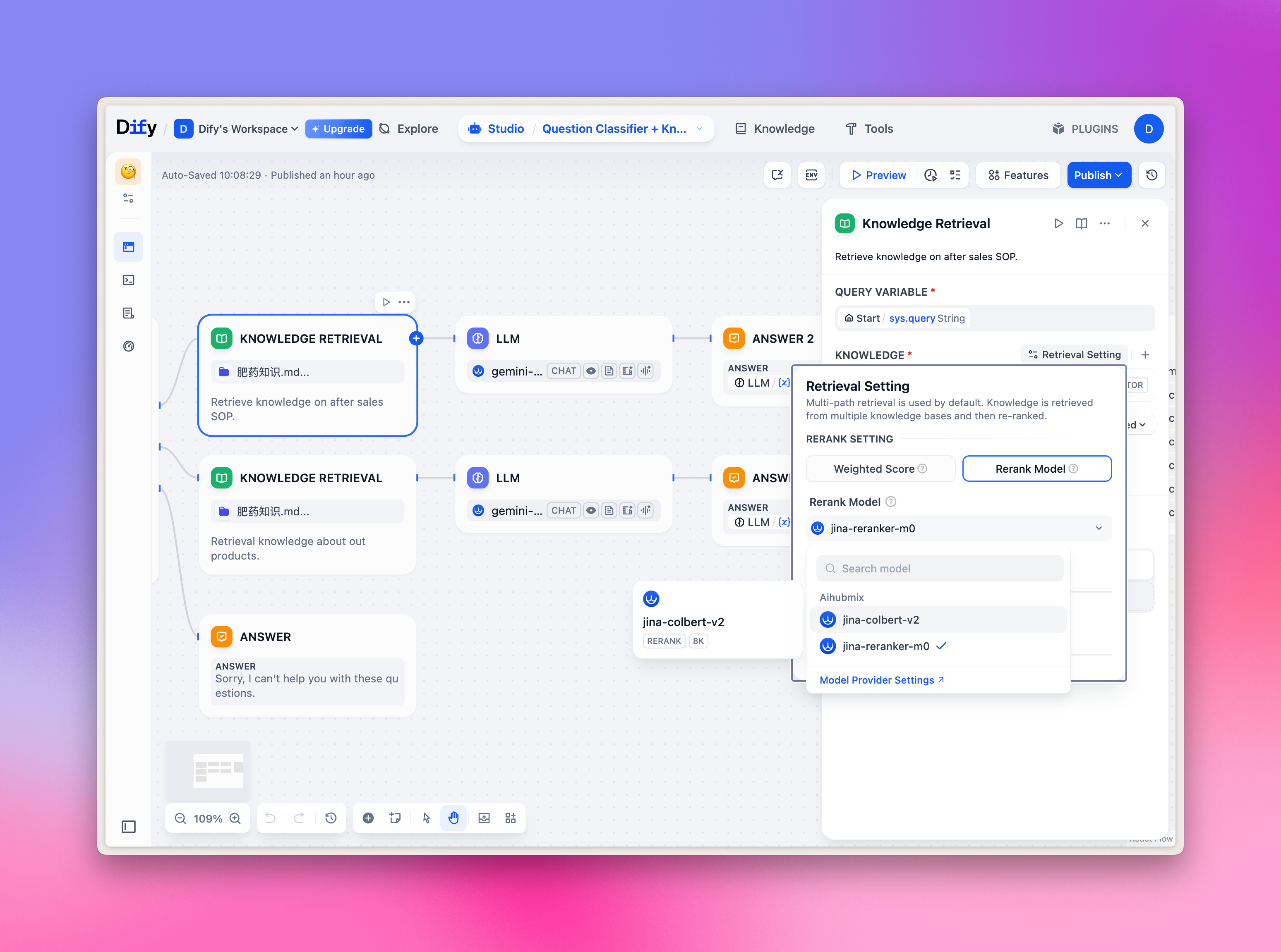
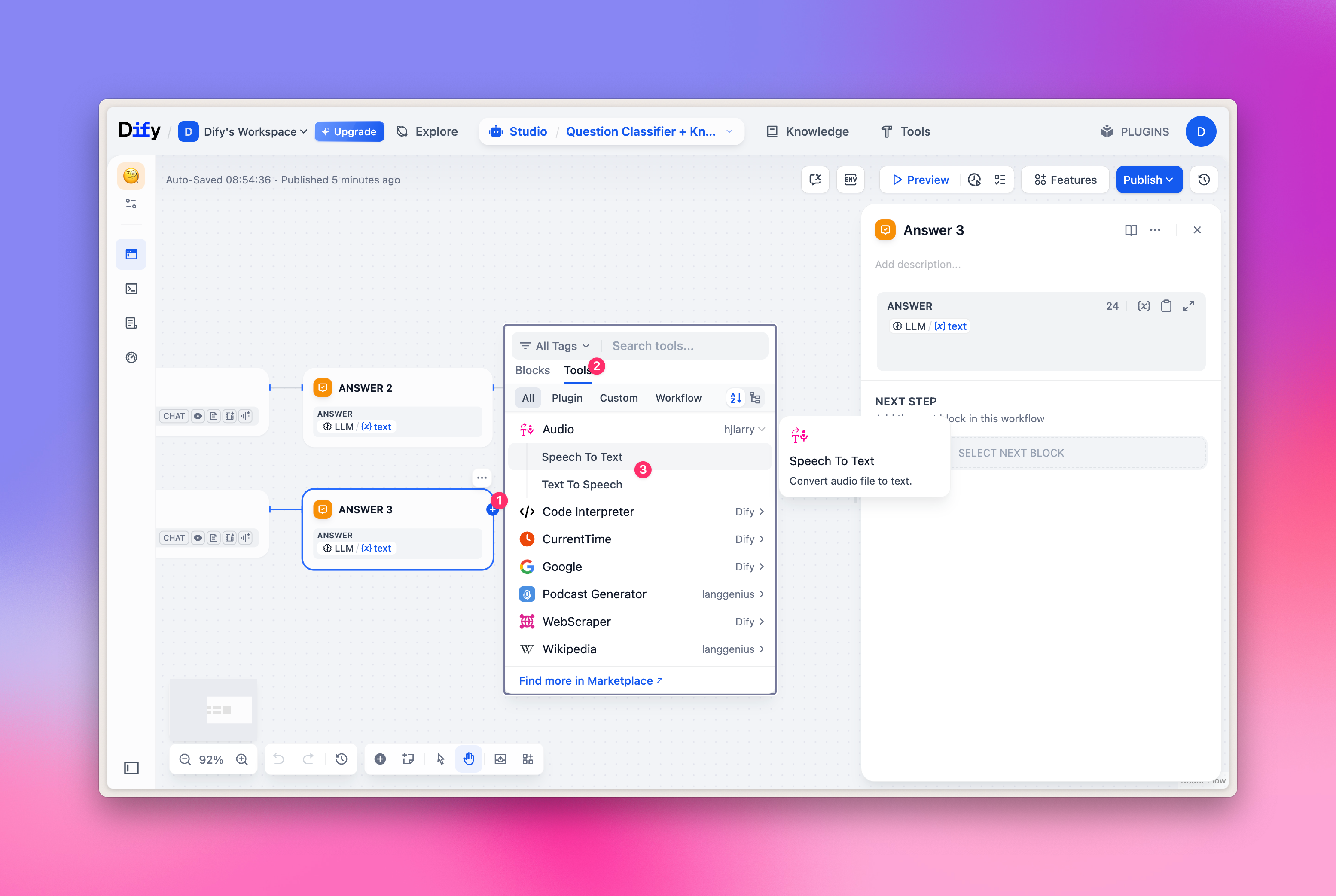
Selección de TTS/SST
Los modelos TTS/SST se utilizan principalmente para el análisis y la síntesis de voz; al seleccionar herramientas, el elemento correspondiente no es el habitual “LLM”, sino el tipo “Audio” en la pestaña “Tools”. Correspondencia:- TTS texto a voz: selecciona “Text to Speech”
- SST voz a texto: selecciona “Speech to Text”
Caché de prompts de Claude
Para habilitar la caché de prompts para los modelos de Claude en Dify mediante este plugin: envuelve el prompt que quieres almacenar en caché con<cache>…</cache> y establece el “umbral de caché automática para mensajes grandes” de los parámetros del modelo en un entero positivo. Para el uso completo y los puntos clave de los aciertos, consulta Caché de prompts de Claude.
Última actualización: 2026-06-01