- 桌面端 AI 客户端——像 ChatGPT 客户端一样开箱即用,本地存储
- 私有 RAG 系统——上传 PDF/Word/网页,AI 基于这些文档回答你的问题
- 多用户协作平台(Docker 自托管)——团队共享知识库 + 权限管理
核心能力清单
- 多格式文档导入:PDF、Word、Excel、CSV、纯文本、Markdown、代码文件、整个网站
- Workspace 机制:每个工作区是独立知识库,文档/对话/模型互不污染
- 多模型 LLM 支持:OpenAI、Anthropic、Google、Azure、AWS Bedrock、Ollama、LM Studio,以及任意 OpenAI 兼容端点( AIHubMix 入口)
- 多 Embedder 支持:OpenAI、Cohere、Voyage、本地模型(如 nomic-embed-text、bge-m3)
- 内置向量数据库:默认 LanceDB(零配置),也可接 Pinecone、Chroma、Weaviate、Qdrant 等
- Agent 能力:在 RAG 之外让模型调用工具——网页抓取、SQL 查询、自定义脚本
- API 服务:暴露 OpenAI 兼容接口,可被 n8n、Make、Raycast 等工具反向调用
AnythingLLM 在 RAG 工具谱里的位置
AnythingLLM 的核心卖点:装好就能用。下载桌面版,首次启动 5 分钟就能完成”上传 PDF → 提问”的完整流程。它内置了向量库(LanceDB)、文档解析器、Embedder 调用器、Workspace 隔离机制——你只需要选一个 LLM Provider 和一个 Embedder Provider。
通用配置方法
先从 AnythingLLM 官网 下载并安装桌面版。进入应用后,打开左下角头像菜单,在设置页里找到 LLM 配置入口。
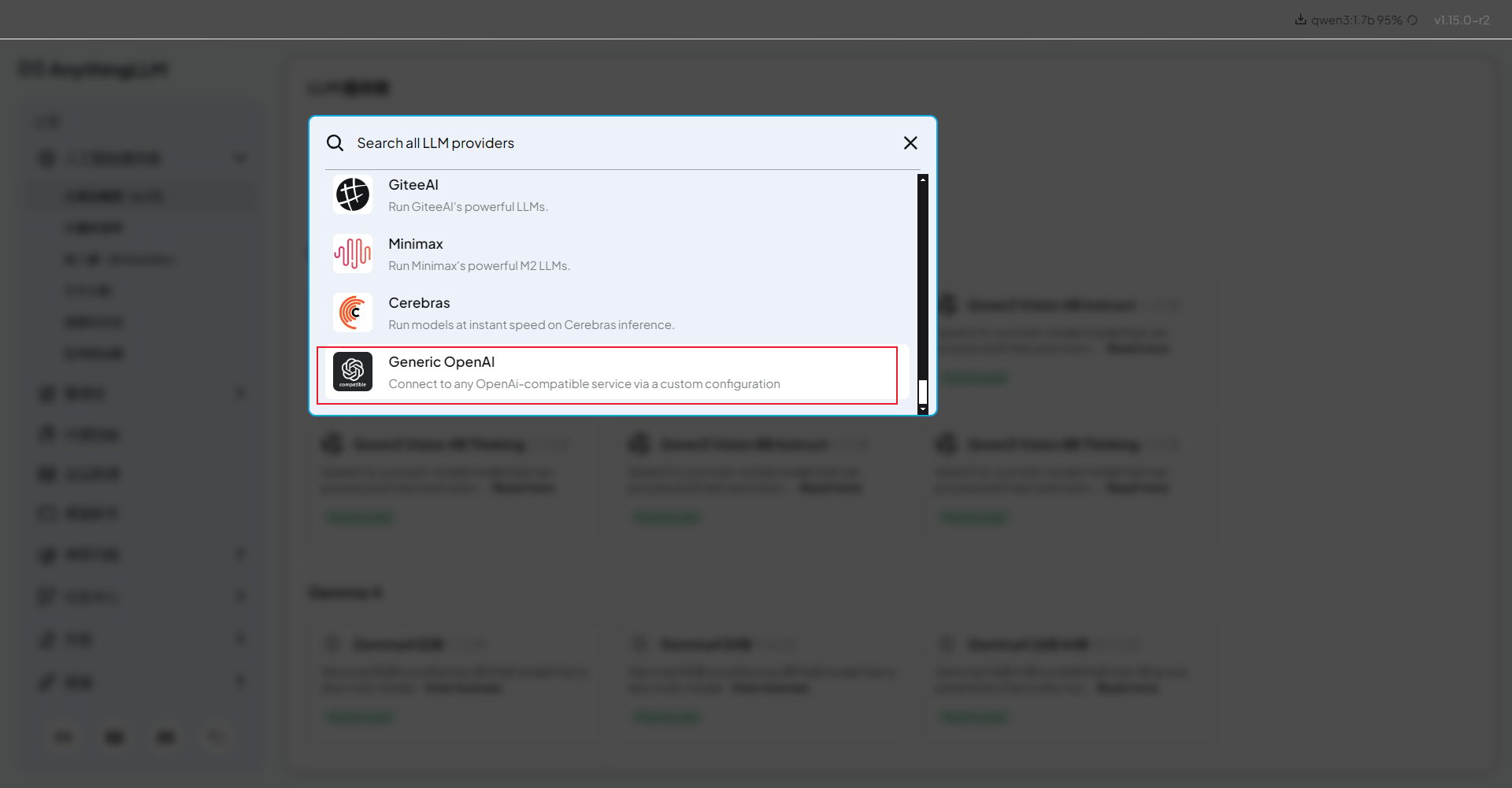
- Base URL 填写:
如遇当前 API 主地址不可用,可将此处域名替换为备用地址
https://api.inferera.com,路径保持不变。- API Key 填写你在 AIHubMix 控制台 创建的 Key。
- Chat Model Name 填写要使用的模型 ID,例如
gpt-4o-mini、claude-haiku-4-5等。模型 ID 建议从 AIHubMix 模型广场复制,避免手动输入出错。 - Token context window 和 Max Tokens 可以按模型能力调整;如果不确定,先使用默认值,确认能正常对话后再按需要增大。
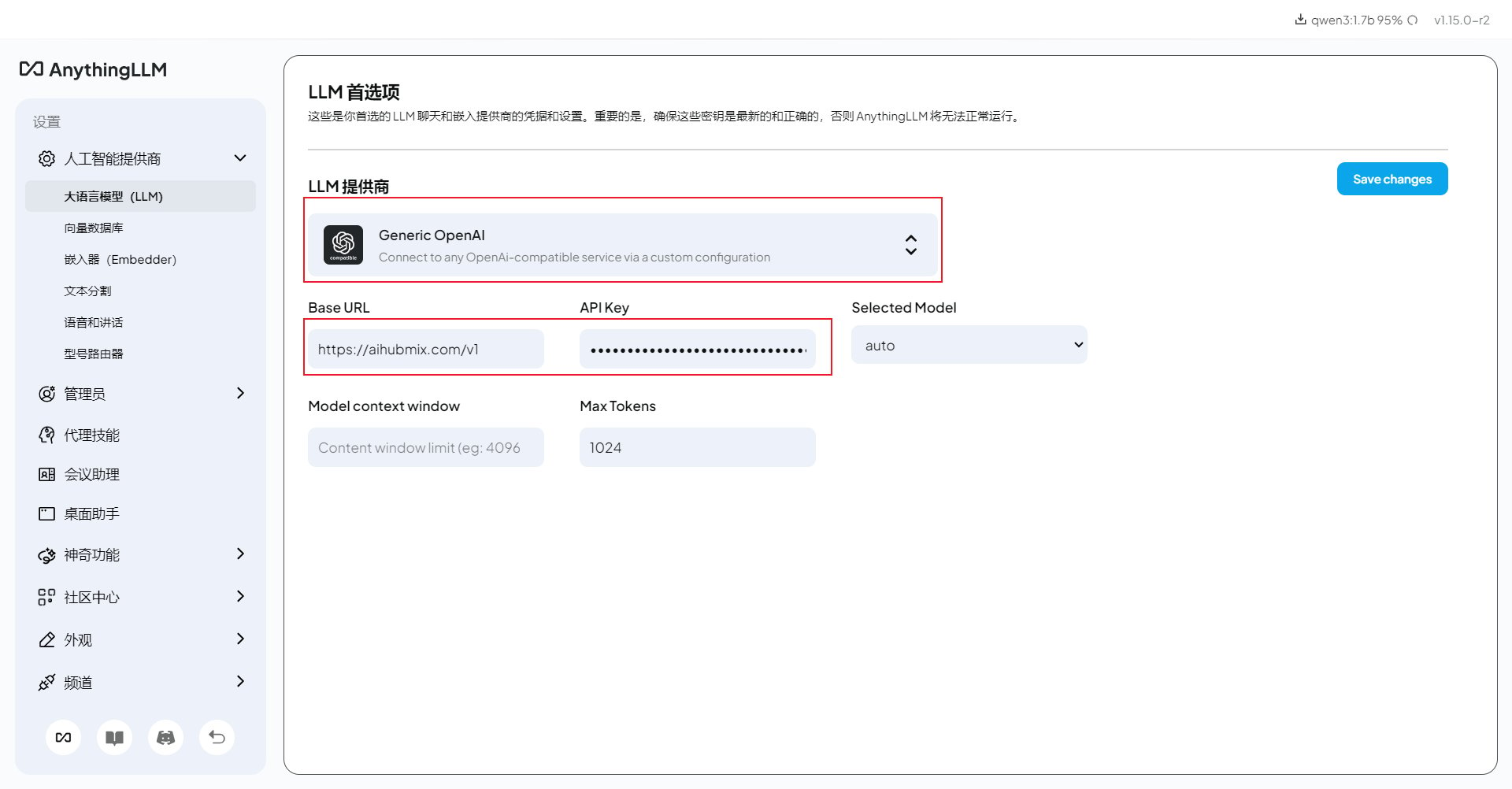
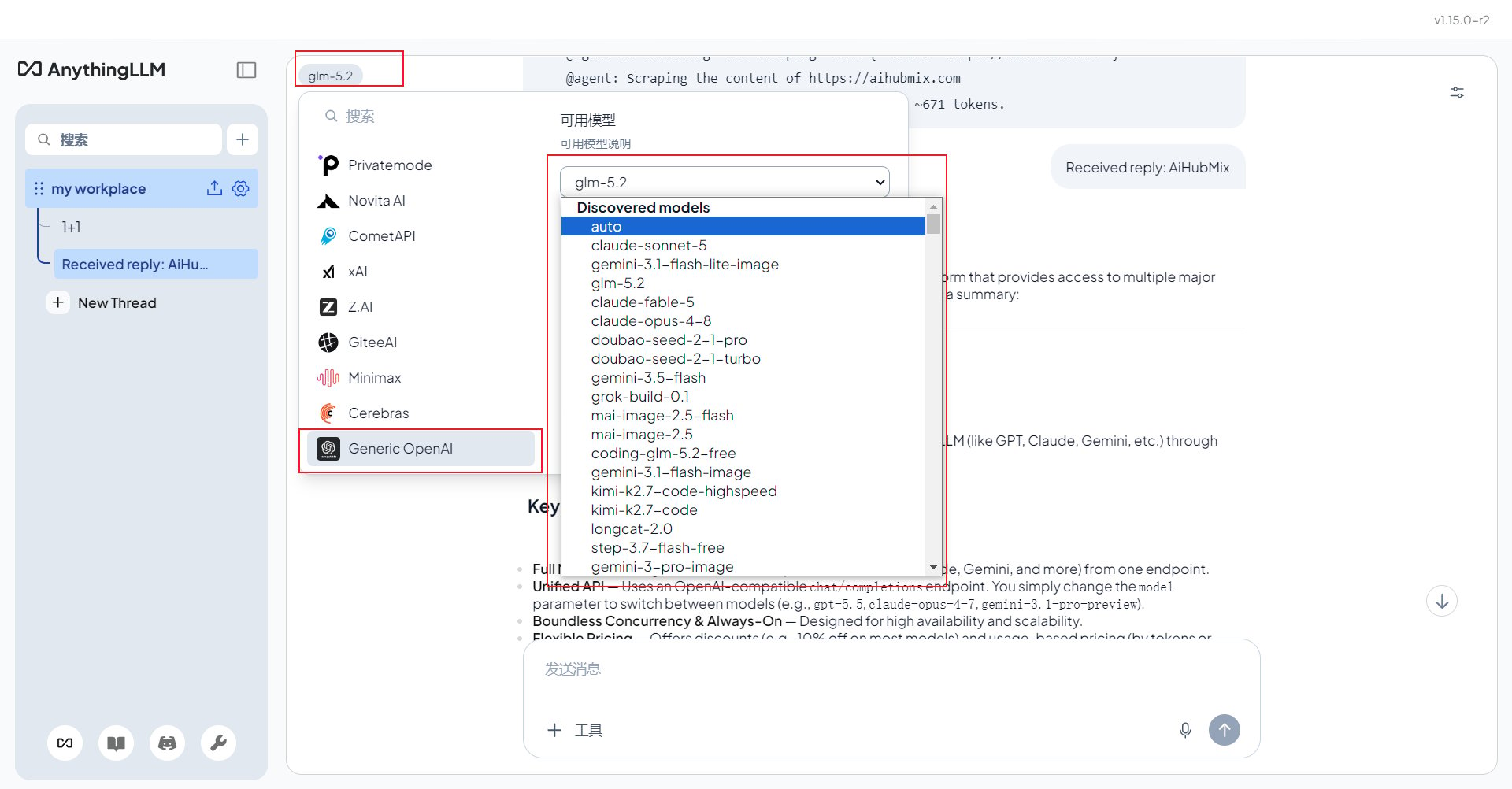
非 OpenAI 模型使用方法
模型服务商选择 Generic OpenAI 不变,在 Chat Model Name 一栏手动修改所需模型名称即可。在 AIHubMix 模型列表中复制需要使用的模型 ID,填入 Chat Model Name 即可。
Docker 部署给团队用
桌面版是单机使用,团队需要 AnythingLLM Docker 镜像。Docker 版本的核心区别:- 多用户登录,管理员可控权限
- Workspace 可在用户间共享(只读/可写)
- 文档解析、向量化运行在服务端
- LLM 与 Embedder 配置由管理员统一管理——也就是说,只要管理员配好一个 AIHubMix Key,全团队成员都能用
http://localhost:3001,登录后在系统设置里按上文配置 AIHubMix 即可。
常见故障排查
问题:文档上传了,提问时模型说”找不到相关信息” 90% 的情况是 Embedder 没配置好,或者 chunk size 太大。检查:- Embedder 是否真的设置成了向量模型(不是 Chat 模型)
- 文档是否真的被向量化(在 Workspace 设置里看 “Pinned Documents” 列表)
- 提问时是否在正确的 Workspace 里(每个 Workspace 文档独立)
Generic OpenAI选对了吗?选成OpenAI会忽略 Base URL- Base URL 是
https://aihubmix.com/v1(带/v1),不要漏 - Chat Model Name 与 AIHubMix 实际支持的模型 ID 一致(去
aihubmix.com复制) - AIHubMix 余额是否充足
- 检查模型是不是
gpt-5/o3/deepseek-reasoner这种推理模型——RAG 场景下确实需要推理时,慢是正常的;只是问”文档里 X 是什么”这种简单检索,换成gpt-4o-mini或claude-haiku-4-5立刻就快 - 检查 Token context window 是否设太大,导致每次请求要塞海量上下文
- 检查 Embedder——
text-embedding-3-small对中文已经不错,但本地bge-m3对中文更优 - 检查 chunk 大小——中文建议 chunk size 设为 300–500 字符,过大会稀释相关性
- 检查文档质量——PDF 表格、扫描件需要先 OCR
参考资料
- AnythingLLM 官网:anythingllm.com
- AnythingLLM 文档:docs.anythingllm.com
- AIHubMix 模型列表与 Key 管理:aihubmix.com
- AnythingLLM Docker Hub:hub.docker.com/r/mintplexlabs/anythingllm
更新时间:2026-07-03