別讓上游當機變成你的當機。AIHubMix 提供兩個Key 層級的能力,在主控台設定一次即可生效,用戶端程式碼無需改動:
- 模型名映射(Model Mapping)是指在閘道層把用戶端請求裡的模型別名改寫為真實上游模型的能力。
- 錯誤時回退模型(Fallback)是指當主模型呼叫失敗時,閘道按預先設定的優先順序自動嘗試備用模型,對用戶端無感。
AIHubMix 支援在 Key 層級設定模型名映射與錯誤回退,並按最終回應模型計費。兩者都在 AIHubMix Key 管理頁 為單個 API Key 設定。
Model name mapping 與 Fallback models on error 兩個區塊分別設定:
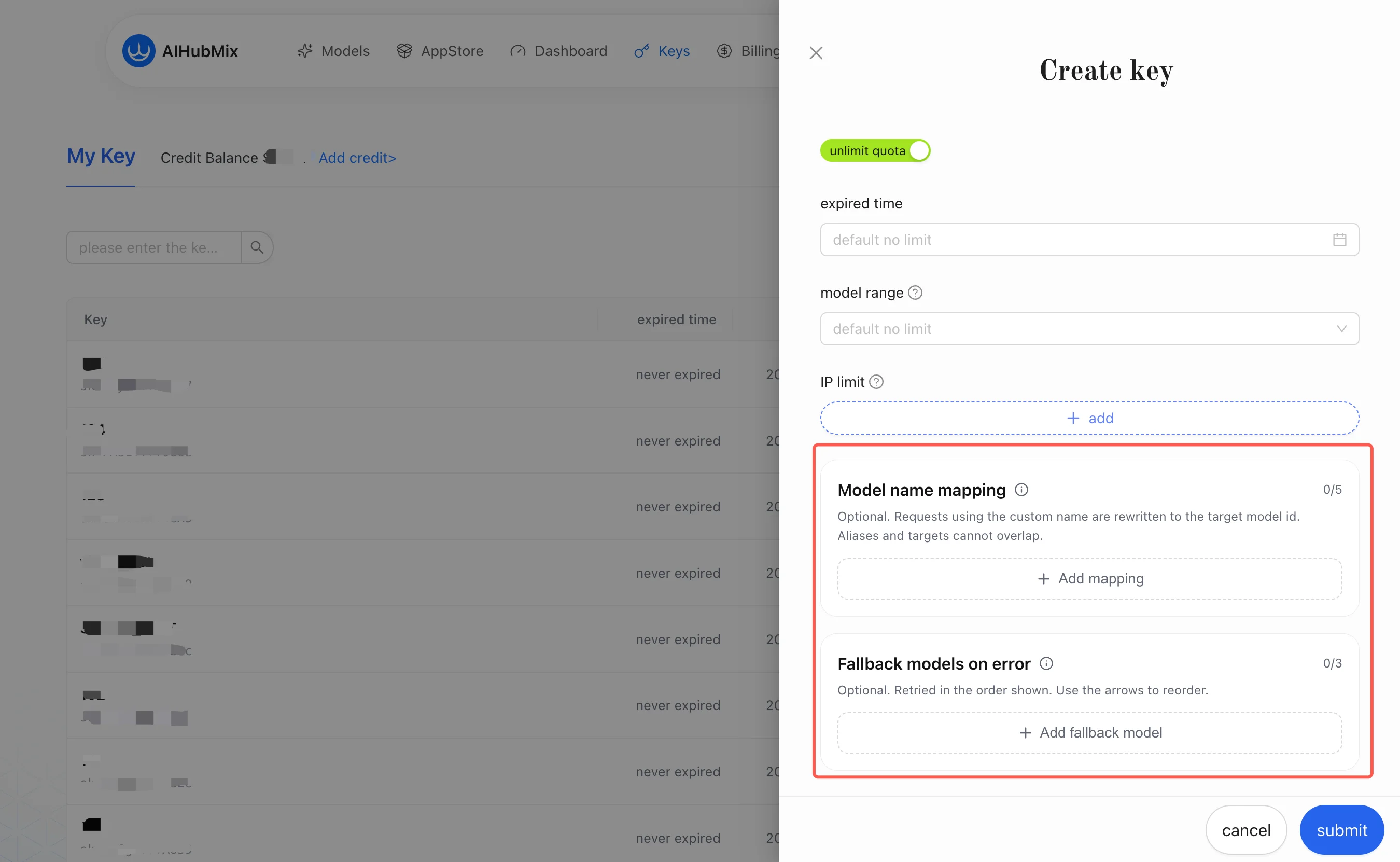
1. 模型名映射(Model Mapping)
模型名映射用於處理「用戶端看到的模型名」和「AIHubMix 實際呼叫的模型」不一致的問題。它是Key 層級(per-key)的別名改寫:把請求裡的別名改寫成你在 Key 裡設定的目標模型。目標模型在選定通道後,平台內部還會做一層通道級映射到真實上游模型;該層對使用者透明、無需設定。你只需要關心「別名 → 目標模型」這一層。範例:
上表模型名均可在 AIHubMix 模型頁 查詢。常見用途:
- 用戶端限制模型名格式,例如 Claude Desktop 要求模型名符合 Claude 風格(見 第 5 節)。
- 給複雜模型 ID 設定更短、更穩定的別名。
- 用戶端設定保持不變,AIHubMix 後台切換真實模型。
- 多個平台共用一套接入命名,但根據 Key 路由到不同模型。
逐字元一致:用戶端傳送的模型名必須和映射左側逐字元一致。例如my-gpt-5.5和my-gpt-5-5是兩個不同的字串,不一致就不會命中映射。
2. 錯誤時回退模型(Fallback)
錯誤時回退模型用於在主模型失敗時按順序嘗試備用模型。它不是用戶端側重試,而是 AIHubMix 閘道側在同一個 Key 設定下完成的模型切換;接入方不需要在每次請求裡傳額外路由參數。 可以把 Fallback 理解成「映射到一個有序列表」:主模型失敗後,閘道自動沿列表往下一個備用模型走。 範例(在同一個 Key 裡設定):2.1 觸發條件(必須全部滿足才回退)
只有以下條件全部成立時才會發生回退:- Key 設定了非空的備用模型列表。
- 主模型的所有通道都被試過、且都以「可重試錯誤」失敗(通道耗盡)。
- 回應尚未開始返回(首位元組 / header 還沒發給用戶端)。
- 錯誤不是 Key / 使用者級錯誤(見下方 2.2 對照表)。
2.2 哪些會回退、哪些不會
說明:這裡「Key 失效」指的是你自己的 AIHubMix Key失效,不會回退。若是某個上游通道的 key 壞了,閘道會換通道,通道耗盡後仍可回退——兩者不要混淆。
2.3 計費口徑
按最終回應模型計費。 如果最終由回退模型回應,計費、能力和上下文限制都以最終回應的那個模型為準。這個模型也會體現在回應標頭裡(見 第 4 節)。2.4 免費模型規則(重要)
免費模型不能作為 fallback 選項——免費模型只能作主模型,放進備用列表會被靜默跳過,繼續往下一個。所以不要把免費模型寫進 fallback 列表。典型用法:把免費模型設為主模型、付費模型放進備用列表。免費主模型觸發額度 / 頻率限流時,會自動回退到備用的付費模型——平時省成本用免費額度,限流後無縫切到付費模型保證可用。這是 fallback 最常見的用法之一。
3. 和 OpenRouter / LiteLLM 的區別
模型映射和回退並不是新概念,OpenRouter、LiteLLM 等都提供類似能力。AIHubMix 的差異在於設定成本最低:
一句話:不用自建閘道、不用改一行用戶端程式碼,在 Key 上設定一次就生效。
4. 設定與驗證
4.1 設定
- 在Key裡設定別名映射:左側別名要和用戶端實際傳送的模型名逐字元一致。
- 在同一 Key裡設定備用模型列表(有序優先順序列表)。
- 備用列表只放付費 / 可用模型,不放免費模型(會被跳過)。
- 備用列表裡的模型必須在該 Key 的可用模型範圍內(越權模型會被跳過)。
4.2 驗證(優先看回應標頭,而不是翻日誌)
排查時不要只看用戶端選了哪個模型,最權威、可自動化的方式是讀回應標頭:X-Aihubmix-Fallback: true:本次請求發生了回退(最終模型 ≠ 主模型時附加)。X-Aihubmix-Model:本次實際回應、且據此計費的模型。
5. 場景一:Claude Desktop
Claude Desktop 透過Gateway 接入 AIHubMix,是模型名映射的典型場景。
本節假設你已經完成 Claude Desktop 的基礎接入。完整接入步驟(下載安裝、開發者模式、Gateway 設定、auth scheme 等)見 在 Claude Desktop 中接入 AIHubMix,本節只講映射與回退的增量設定。
5.1 為什麼需要映射
Claude Desktop 以Gateway(Anthropic-compatible)方式接入,用戶端會按 Claude 風格約束模型名,因此模型名必須使用 claude- 前綴。
於是產生一個矛盾:用戶端那側只能寫 claude- 風格的名字,但你真正想呼叫的是 gpt-5.5、gemini-3.1-pro-preview 這些。模型名映射正是為此而生——用戶端寫別名 claude-g-p-t-5.5,AIHubMix 側映射到真實的 gpt-5.5。
Claude Desktop 走的是 Claude 原生 /v1/messages 介面,所以本文範例裡映射和 Fallback 都生效。
5.2 AIHubMix 映射與回退設定
範例設定: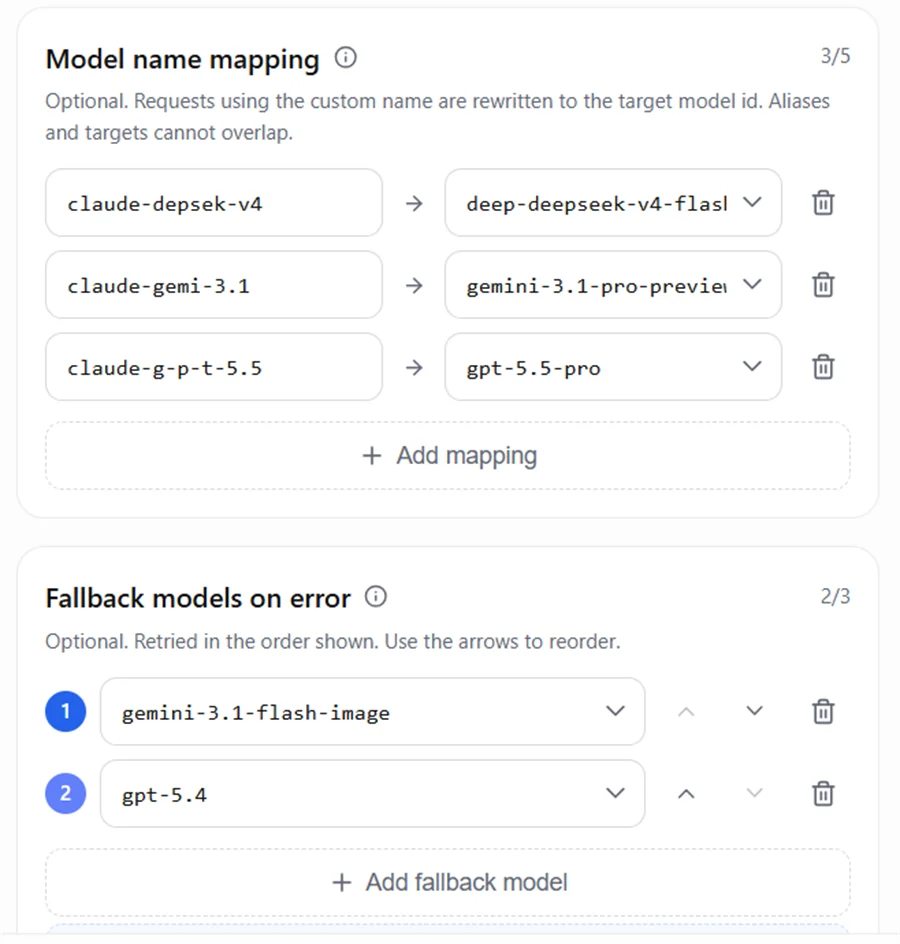
5.3 Claude Desktop 模型列表
在 Claude Desktop 的Model list 裡設定的是映射前的別名——也就是 Claude Desktop 發給 AIHubMix 的模型名,不是真實上游模型名。
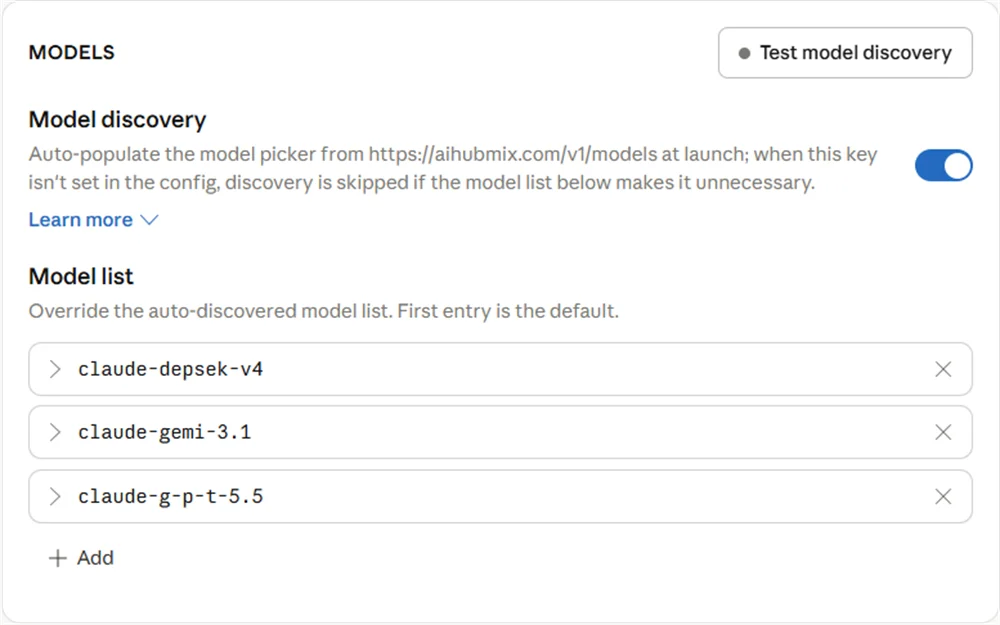
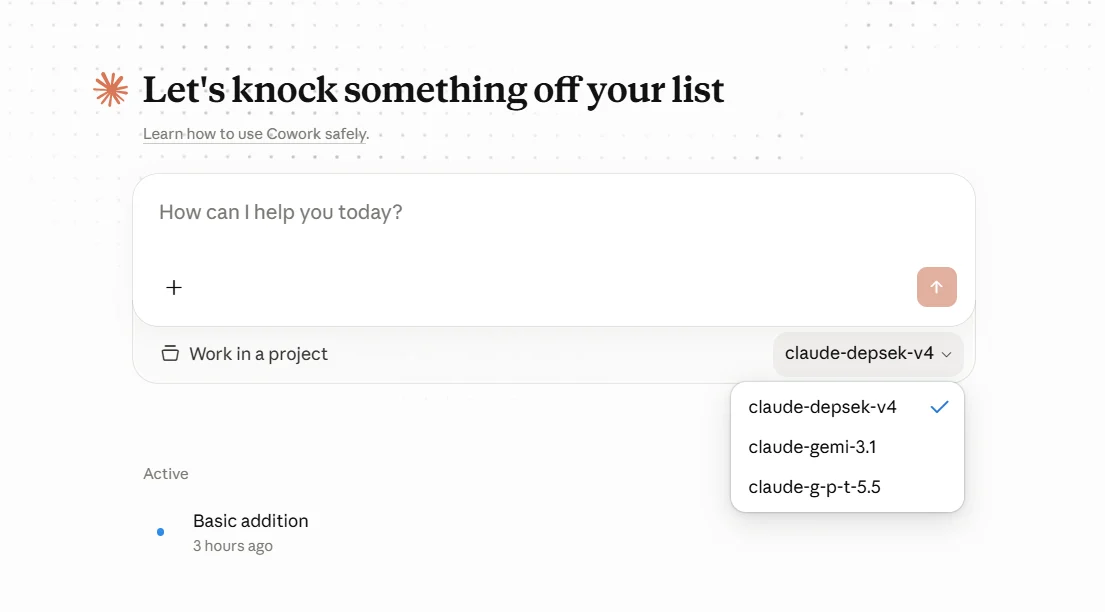
Model ID使用claude-前綴。- 不要直接寫
gpt、gemini、deepseek等真實模型系列名,可使用g-p-t、gemi、depsek等別名。 Model ID必須和 AIHubMix 映射左側逐字元一致,否則請求不會命中預期映射,可能繼續走錯誤回退模型。
6. 場景二:多模態能力兜底
多模態能力兜底用於處理「主模型能回答文字,但不支援當前輸入類型」的場景。比如用戶端傳送了圖片或影片,主模型只有文字輸入能力,AIHubMix 可以繼續嘗試回退列表裡支援對應模態的模型。 下面是一條實際測試鏈路。這條 Key 的映射與 fallback 設定如下(見下方截圖),重點是 fallback 列表裡既有文字模型也有支援圖片理解的模型:claude-g-l-m-4.6——一個只支援文字輸入的模型。使用者上傳了一張 AIHubMix 模型列表頁面截圖,並詢問「這個網站是做什麼的」。因為請求裡包含圖片,文字模型無法直接處理該輸入,於是觸發了 fallback。
Google AI Studio/gemini-3.1-flash-image,也就是 fallback 列表裡的第 2 個。第 1 個 gpt-5.4 同樣不支援該圖片輸入、對這次請求繼續返回可重試錯誤,於是閘道接著往下,落到了支援圖片理解的 gemini-3.1-flash-image。
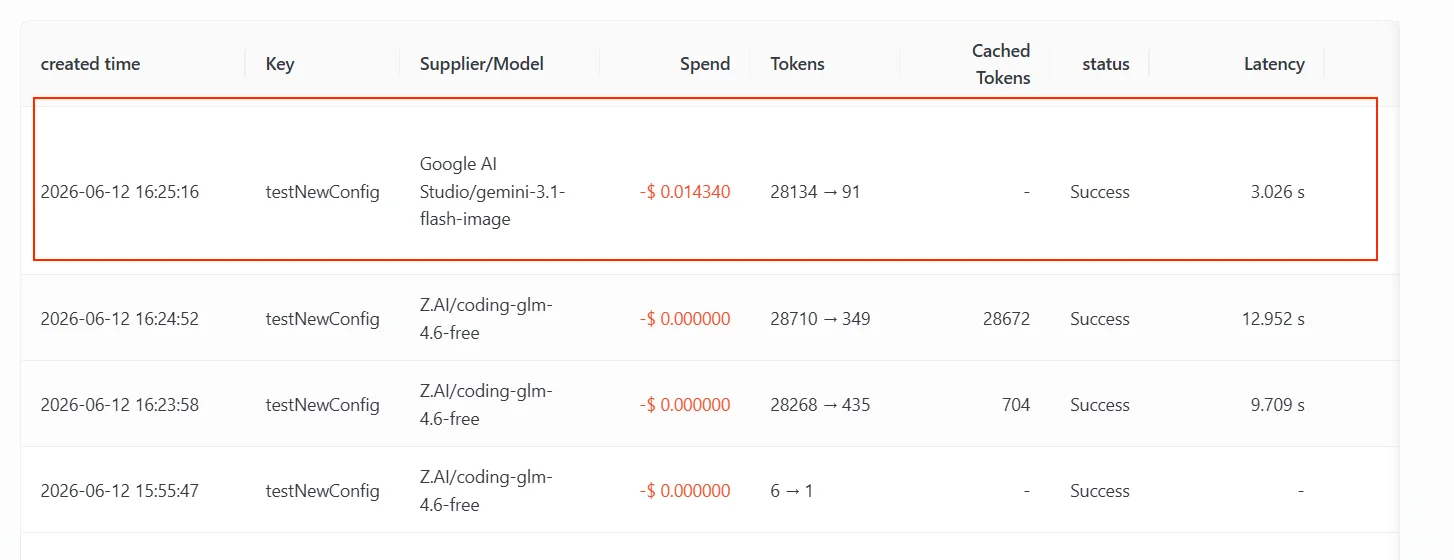
觸發原因要講清:這裡兜底是因為上游對該圖片輸入返回了可重試錯誤、且主模型通道耗盡——和「主模型限流後回退」是同一套回退機制,只是觸發的錯誤類型不同(前者是輸入不被支援,後者是額度 / 頻率限流)。
注意區分理解與生成:這裡說的是圖片 / 影片理解兜底,不是圖片生成或影片生成。聊天請求不會自動變成生成介面;要測試畫圖或影片生成,應走對應的生成介面和模型。模型能力以 AIHubMix 模型頁當前標註的 Input Modalities 為準。
7. 場景三:免費模型兜底(省成本 + 保可用)
這是 fallback 最常見的用法之一:把免費模型設為主模型、付費模型放進備用列表。平時請求都走免費模型、省成本;一旦免費主模型觸發額度 / 頻率限流,閘道自動回退到備用的付費模型,保證服務不中斷。 範例 Key 設定:- 免費額度還夠用時,請求由主模型
coding-glm-5.2-free回應,按免費計費。 - 免費主模型觸發限流後,自動回退到
gpt-5.4;若gpt-5.4也不可用,再嘗試gemini-3.1-pro-preview。 - 最終由哪個模型回應,就按那個模型計費(見 2.3)。
注意:免費模型只能作主模型,不能放進 fallback 列表(放進去會被跳過,見 2.4)。所以「免費兜底」的正確姿勢是:免費在主、付費在備,而不是反過來。驗證方式同樣是看回應標頭:發生回退時返回
X-Aihubmix-Fallback: true,X-Aihubmix-Model 顯示最終回應模型(見 第 4 節)。
8. 支援的端點
模型映射與錯誤回退目前支援以下介面類別:
要點:
- 模型映射與錯誤回退支援 OpenAI 相容介面、Claude 原生
/v1/messages、OpenAI Responses/v1/responses三類介面。 - 其他原生透傳介面(Gemini 原生、Ideogram、影片、TTS、Stability、OCR、predictions 等)、指定通道透傳、以及按資源 ID 檢索 / 檔案類介面暫不支援。
- Claude Desktop 走的是 Claude 原生
/v1/messages,所以本文範例裡映射和 Fallback 都生效。
9. 常見問題 FAQ
Q:Claude Desktop 提示 model not found 怎麼辦? A:檢查 Claude Desktop 裡的Model ID 是否和 AIHubMix 映射左側逐字元一致;不一致就不會命中映射。
Q:回退會不會影響計費?
A:按最終回應模型計費。最終是哪個模型回應,就按那個模型的價格、能力和上下文限制計算。
Q:怎麼確認這次請求到底走沒走回退?
A:看回應標頭 X-Aihubmix-Fallback: true(發生了回退)和 X-Aihubmix-Model(最終回應模型),見 第 4 節。
Q:哪些錯誤會觸發回退,哪些不會?
A:見 2.2 的對照表。簡單說:上游可重試失敗、通道耗盡、回應未開始才會回退;指定通道、回應已開始、用戶端中斷 / 逾時、Key / 使用者級錯誤都不回退。
Q:免費模型能放進 fallback 列表嗎?
A:不能,會被跳過。免費模型只能作主模型。
Q:和 OpenRouter / LiteLLM 的 model alias / fallback 有什麼區別?
A:AIHubMix 是Key 級、平台託管,在主控台設定一次就生效,不用改用戶端程式碼、也不用自建閘道。詳見 第 3 節。
相關資源
- 在 Claude Desktop 中接入 AIHubMix:開發者模式、Gateway 設定、auth scheme 等完整步驟。
- AIHubMix 模型頁:查詢模型名稱、價格與
Input Modalities。 - 在 LiteLLM 中接入 AIHubMix:需要自建閘道 + 模型映射 / 回退時的參考。