Imagen 繪圖
Imagen 是 Google 推出的先進圖像生成 AI 模型系列,能夠根據文字提示創建高品質、逼真的圖像。本指南將幫助您了解如何使用 Imagen 系列 API 生成圖像,包括參數設置、模型選擇和程式碼範例。 可用模型列表:- imagen-4.0-ultra-generate-001
- imagen-4.0-generate-001
- imagen-4.0-fast-generate-001
- imagen-4.0-fast-generate-preview-06-06
- imagen-3.0-generate-002
模型參數
Imagen 目前僅支援英文提示詞,並提供以下參數:- numberOfImages: 要生成的圖像數量,範圍從 1 到 4(含)。默認值為 4。另外注意
imagen-4.0-ultra-generate-001單次只能生成 1 張。 - aspectRatio: 更改生成圖像的寬高比。支援的值有 “1:1”、“3:4”、“4:3”、“9:16” 和 “16:9”。默認值為 “1:1”。
- personGeneration: 允許模型生成人物圖像。支援以下值:
- “DONT_ALLOW”: 阻止生成人物圖像。
- “ALLOW_ADULT”: 生成成人圖像,但不生成兒童圖像。這是默認值。
費率
使用 Imagen API 生成圖像的費用如下:- imagen-4-ultra:$0.06/張
- imagen-4:$0.04/張
- imagen-4-fast:$0.02/張
- imagen-3:$0.03/張
調用示例
以下是使用 Imagen 生成圖像的 Python 調用示例:提示詞技巧
創建有效的提示詞對於獲得理想的圖像至關重要:- 使用詳細的描述,包括主題、風格、光照、角度等。
- 指定藝術風格(如電影感、寫實主義、動漫風格等)。
- 包含技術細節(如 DSLR、高清、細節豐富等)。
- 避免負面或違禁內容。
- 避免在提示詞中包含大量文字,僅使用重點關鍵詞以獲得更穩定的結果。
- 關鍵詞包含
girl時容易觸發 TypeError: ‘NoneType’ object is not iterable 報錯,不推薦用於人物繪製
Gemini 2.0 Flash 圖像生成
Gemini 也提供了圖像生成能力,作為一種替代方案。與 Imagen 3.0 相比,Gemini 的圖像生成更適合於需要上下文理解和推理的場景,而非追求極致的藝術表現和視覺質量。- 更高的視覺質量 → 相比 exp 版,圖像更銳利、更豐富、更清晰。
- 更準確的文字呈現 → 生成的視覺中,文字更加精准、乾淨、易讀。
- 顯著減少過濾攔截 → 得益於更智能、寬鬆的過濾機制,創作時幾乎不再被打斷。
- 模型 id:
gemini-2.0-flash-preview-image-generation - 費率(輸入→輸出):0.4/M tokens
- 需要新增參數來體驗新特性
"modalities":["text","image"] - 圖片以 Base64 編碼形式傳遞與輸出
- 作為實驗模型,建議明確指出 “輸出圖片”,否則可能只有文字
- 輸出圖片的默認高度為 1024px
- python 調用需要最新的 openai sdk 支援,請先運行
pip install -U openai - 了解更多請訪問 Gemini 官方文件
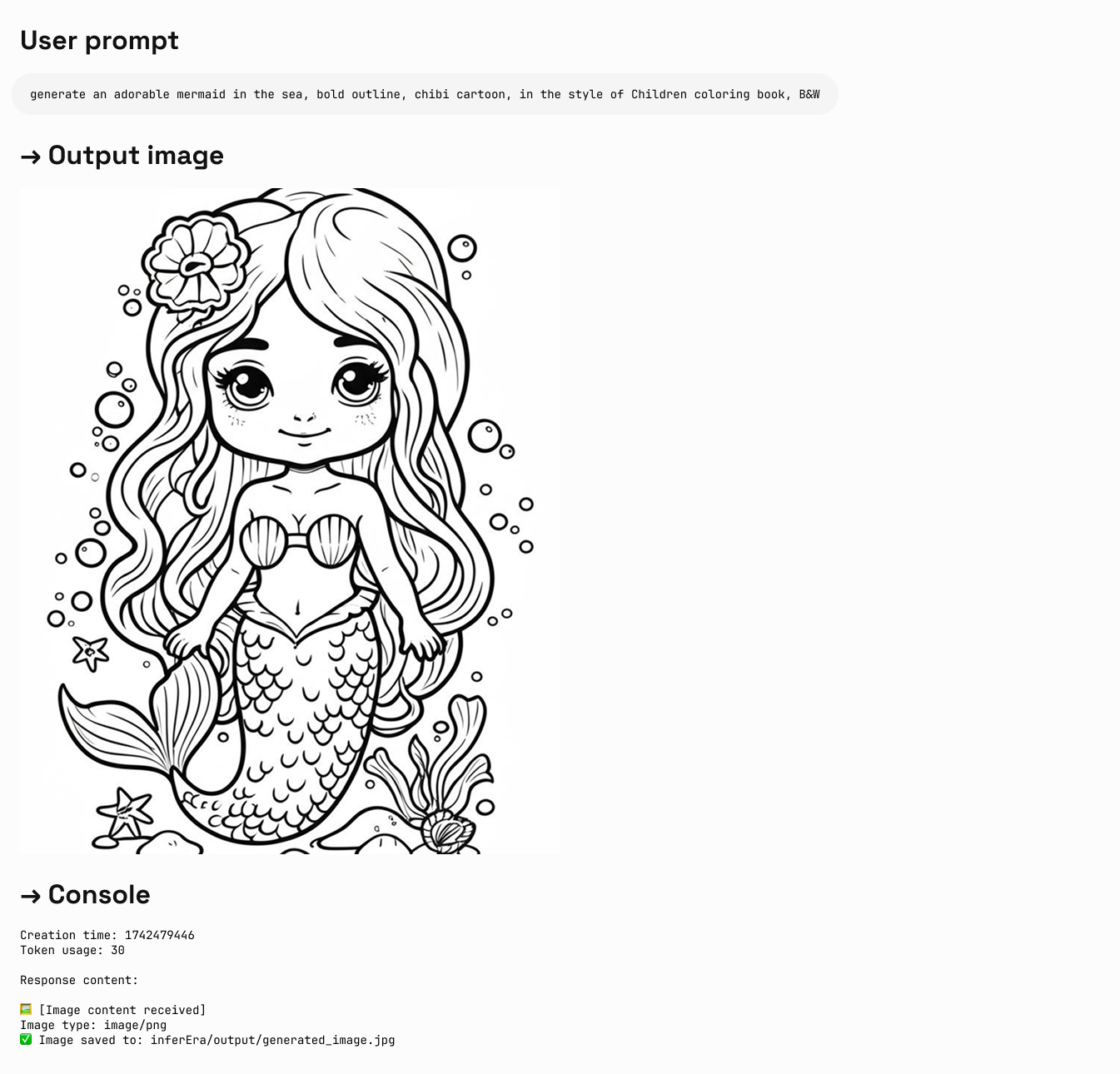
圖文生成
Iuput:text Output:text + image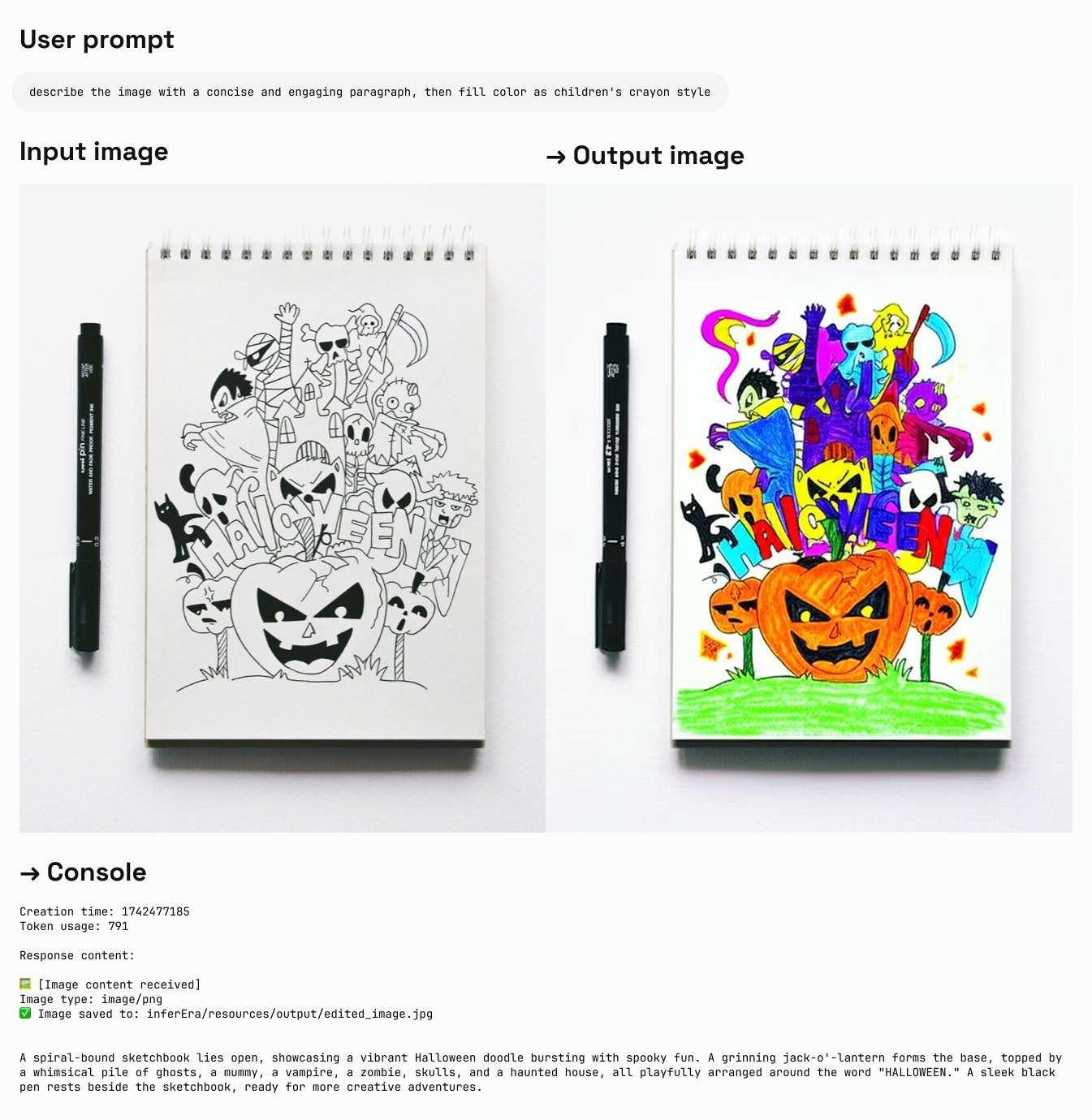
圖片編輯
Iuput:text + imageOutput:text + image
選擇正確的繪圖模型
選擇 Gemini 的情況:
- 需要利用世界知識和推理能力生成上下文相關的圖像。
- 需要無縫混合文字和圖像。
- 希望在長文字序列中嵌入準確的視覺內容。
- 希望在保持上下文的同時以對話方式編輯圖像。
選擇 Imagen 的情況:
- 圖像質量、照片真實感、藝術細節或特定風格(如印象派、動漫)是首要考慮因素。
- 執行專業編輯任務,如產品背景更新或圖像放大。
- 注入品牌、風格或生成標誌和產品設計。
最佳實踐
- 優化提示詞:精心設計提示詞,這是獲得高品質輸出的關鍵。
- 實驗參數:嘗試不同的寬高比和設置,找到最適合您需求的配置。
- 批量生成:生成多張圖像以增加獲得理想結果的機會。
- 保存元數據:將提示詞和時間戳與圖像一起保存,以便追踪和複製成功的結果。
- 遵守使用政策:確保您的使用符合 Google 的內容政策和使用條款。
Veo 3.0 影片生成
VEO 3.0 是由 Google DeepMind 開發的最新先進影片生成模型。使用 VEO 3.0,您可以生成具有以下特點的影片:- 從文字和圖像提示中生成的質量提升
- 語音,例如對話和配音
- 音頻,例如音樂和聲音效果
已知限制
目前 VEO 3.0 的參數固定,無法更改:- 分辨率: 720p(橫屏)
- 幀率: 24fps
- 影片長度: 8秒
費率
使用 VEO 3.0 API 的費用是 $0.675/秒(Aihubmix 提供 10% 限時優惠)調用示例
VEO 3.0 目前僅支援 curl 命令調用,採用兩步處理方式: 其中:sk-*** 換成你在 AiHubMix 生成的密鑰。
返回示例
步驟 1 返回:最佳實踐
- 耐心等待:影片生成通常需要幾分鐘,高峰期可能更長
- 檢查狀態:如果返回中沒有
done: true,說明仍在處理中 - 保存操作 ID:確保保存步驟 1 返回的操作 ID 用於後續查詢
- 遵守使用政策:確保您的使用符合 Google 的內容政策和使用條款
Veo 2.0 影片生成
VEO 2.0 是 Google 推出的先進影片生成 AI 模型,能夠根據文字提示創建高品質、逼真的短影片。下面的指南將幫助您了解如何使用 VEO 2.0 API 生成影片,包括參數設置、模型選擇和程式碼範例。模型參數
VEO 2.0 提供以下參數:- numberOfVideos: 要生成的影片數量,可選 1 或 2。默認值為 2。
- aspectRatio: 生成影片的寬高比。支援的值有 “16:9” 和 “9:16”。
- durationSeconds: 影片時長,可選 5 秒或 8 秒。默認值為 8 秒。
- personGeneration: 控制是否允許生成含人物的影片。支援以下值:
- “dont_allow”: 阻止生成含人物的影片。
- “allow_adult”: 允許生成含成人的影片,但不生成兒童影片。
費率
使用 VEO 2.0 API 的費用是 $0.35/秒調用示例
以下是使用 VEO 2.0 生成影片的 Python 調用示例:提示詞技巧
創建有效的提示詞對於獲得理想的影片至關重要:- 描述清晰的場景、動作和氛圍
- 指定拍攝風格(如全景、特寫、跟隨鏡頭等)
- 描述光照條件(如陽光明媚、黃昏、室內燈光等)
- 指明主體對象及其動作(如”貓咪在陽光下睡覺”)
- 避免過於複雜的叙事或快速變化的場景
- 避免負面或違禁內容
最佳實踐
- 簡潔明瞭的提示詞:使用清晰、具體的描述來指導影片生成。
- 耐心等待:影片生成需要 2-3 分鐘,請耐心等待完成。
- 測試不同參數:嘗試不同的寬高比和時長,找到最適合您需求的設置。
- 保存生成記錄:將提示詞與生成的影片一起記錄,以便追踪成功的結果。
- 遵守使用政策:確保您的使用符合 Google 的內容政策和使用條款。
最後更新:2026-06-01