提示词缓存的工作原理
当你发送启用了提示词缓存的请求时:- 系统会检查是否已经缓存了最近查询中指定缓存断点之前的提示词前缀
- 如果找到,就使用缓存版本,减少处理时间和成本
- 否则,系统会处理完整提示词,并在开始响应时缓存前缀部分
- 包含大量示例的提示词
- 大量的上下文或背景信息
- 具有一致指令的重复任务
- 长时间的多轮对话
常見錯誤:寫了緩存卻「只寫不讀」
最常見的失效場景是:每輪請求cache_creation_input_tokens 都很大(一直在寫緩存),但 cache_read_input_tokens 始終為 0(從來讀不到),等於完全沒省到錢。
根因只有一個:緩存斷點(cache_control)之前的內容,在兩次請求之間發生了變化。 緩存命中要求斷點及其之前的所有內容(按 tools → system → messages 順序)逐位元組完全一致;只要斷點前有任何一個字變了,整段前綴緩存全部作廢、重新寫入。
❌ 錯誤寫法:把每輪會變的問題放在斷點前面
✅ 正確寫法:大文件放最前 + 斷點 + 問題放最後
實測對照(claude-opus-4-6,固定同一渠道,兩次調用間隔數秒)
| 寫法 | 第 2 次只改了什麼 | cache_creation | cache_read | 結果 |
|---|---|---|---|---|
| ❌ 錯誤 | 斷點前的內容 | 19821 | 0 | 整段重寫,未命中 |
| ✅ 正確 | 僅斷點後的問題 | 0 | 19814 | 完整命中 |
- 固定不變的大塊(參考文件、長上下文)放在
messages用戶消息的最前面,cache_control打在它末尾,這段內容一個字都不能動; - 每輪變化的問題/指令放到斷點之後(同一條
user消息裡大文件之後,或後續消息);多輪對話只往後追加,不要回頭修改歷史消息; - 開啟
thinking時,歷史助手輪裡的思考塊要原樣回傳,否則前綴同樣會斷(見下文「無法緩存的內容」); - 若塊小於最小緩存門檻(Opus 4.5/4.6、Haiku 4.5 為 4096 Token),即使標了
cache_control也不會寫入緩存——這是預期行為,見下文「緩存限制」。
緩存定價
提示詞緩存采用新的定價結構。下表顯示了每個支持模型的百萬 Token 價格:| 模型 | 基礎輸入 Token | 5 分鐘緩存寫入 | 1 小時緩存寫入 | 緩存命中和刷新 | 輸出 Token |
|---|---|---|---|---|---|
| Claude Opus 4 | 按平台定價 | 1.25x 基礎價格 | 2x 基礎價格 | 0.1x 基礎價格 | 按平台定價 |
| Claude Sonnet 4 | 按平台定價 | 1.25x 基礎價格 | 2x 基礎價格 | 0.1x 基礎價格 | 按平台定價 |
| Claude Sonnet 3.7 | 按平台定價 | 1.25x 基礎價格 | 2x 基礎價格 | 0.1x 基礎價格 | 按平台定價 |
| Claude Sonnet 3.5 | 按平台定價 | 1.25x 基礎價格 | 2x 基礎價格 | 0.1x 基礎價格 | 按平台定價 |
| Claude Haiku 3.5 | 按平台定價 | 1.25x 基礎價格 | 2x 基礎價格 | 0.1x 基礎價格 | 按平台定價 |
| Claude Opus 3 | 按平台定價 | 1.25x 基礎價格 | 2x 基礎價格 | 0.1x 基礎價格 | 按平台定價 |
| Claude Haiku 3 | 按平台定價 | 1.25x 基礎價格 | 2x 基礎價格 | 0.1x 基礎價格 | 按平台定價 |
- 5 分鐘緩存寫入 Token 價格為基礎輸入 Token 價格的 1.25 倍
- 1 小時緩存寫入 Token 價格為基礎輸入 Token 價格的 2 倍
- 緩存讀取 Token 價格為基礎輸入 Token 價格的 0.1 倍
- 常規輸入和輸出 Token 按平台標準費率計價
如何實現提示詞緩存
支持的模型
目前支持提示詞緩存的模型包括:- Claude Opus 4
- Claude Sonnet 4
- Claude Sonnet 3.7
- Claude Sonnet 3.5
- Claude Haiku 3.5
- Claude Haiku 3
- Claude Opus 3
構建提示詞結構
將靜態內容 (工具定義、系統指令、上下文、示例) 放在提示詞的前面。使用cache_control 參數標記要緩存的可用內容的結束位置。
緩存前綴按以下順序創建:tools、system,然後是 messages。
使用 cache_control 參數,你可以定義最多 4 個緩存斷點,允許分別緩存不同的可用部分。對於每個斷點,系統會自動檢查之前位置的緩存命中情況,如果找到就使用最長的匹配前綴。
緩存限制
最小可緩存提示詞長度為:- Claude Opus 4、Claude Sonnet 4、Claude Sonnet 3.7、Claude Sonnet 3.5 和 Claude Opus 3 為 1024 個 Token
- Claude Haiku 3.5 和 Claude Haiku 3 為 2048 個 Token
cache_control,更短的提示詞也無法緩存。任何請求緩存少於這個數量的 Token 都會在不使用緩存的情況下處理。要查看提示詞是否被緩存,請查看響應使用情況字段。
對於並發請求,注意緩存條目只有在第一個響應開始後才可用。如果需要並行請求的緩存命中,請等待第一個響應後再發送後續請求。
目前支持兩種緩存類型:
- “ephemeral”:默認 5 分鐘生存期
- 1 小時緩存(Beta):適用於需要更長緩存時間的場景
1 小時緩存持續時間(Beta)
對於需要更長緩存時間的場景,我們提供 1 小時緩存選項。 要使用擴展緩存,需要在請求中添加extended-cache-ttl-2025-04-11 作為 beta header,然後在 cache_control 定義中包含 ttl:
何時使用 1 小時緩存
1 小時緩存特別適用於:- 批處理作業:處理大量具有共同前綴的請求
- 長時間會話:需要在較長時間內保持上下文的對話
- 大型文件分析:對同一文件進行多次不同類型的分析
- 代碼庫問答:在較長時間內對同一代碼庫進行多次查詢
混合不同的 TTL
你可以在同一個請求中混合使用不同的緩存持續時間:可以緩存的内容
請求中的每個塊都可以用 cache_control 指定緩存。這包括:- 工具:tools 數組中的工具定義
- 系統消息:system 數組中的內容塊
- 消息:messages.content 數組中的內容塊,包括用戶和助手的對話輪次
- 圖片和文件:用戶對話輪次中 messages.content 數組的內容塊
- 工具使用和工具結果:用戶和助手對話輪次中 messages.content 數組的內容塊
cache_control 標記來啟用該部分請求的緩存。
無法緩存的内容
雖然大多數請求塊都可以緩存,但有一些例外:- 思考塊無法直接使用
cache_control緩存。但是,當思考塊出現在之前的助手回合中時,可以與其他內容一起緩存。以這種方式緩存時,從緩存讀取時它們確實計為輸入 Token。 - 子內容塊(如引用)本身無法直接緩存。相反,緩存頂級塊。
- 空文本塊無法緩存。
跟踪緩存性能
通過響應中的這些 API 響應字段 (或流式傳輸時的 message_start 事件) 監控緩存性能:cache_creation_input_tokens: 創建新緩存條目時寫入緩存的 Token 數cache_read_input_tokens: 從緩存中檢索的 Token 數input_tokens: 未從緩存讀取或用於創建緩存的輸入 Token 數
有效緩存的最佳實踐
要優化提示詞緩存性能:- 緩存穩定的、可用重用的內容,如系統指令、背景信息、大型上下文或常用工具定義
- 將緩存內容放在提示詞前面以獲得最佳性能
- 策略性地使用緩存斷點來分隔不同的可用前綴部分
- 定期分析緩存命中率並根據需要調整策略
- 對於長期使用的内容,考慮使用 1 小時緩存以獲得更好的成本效益
針對不同用例的優化
根據你的場景調整提示詞緩存策略:- 對話代理:減少長時間對話的成本和延遲,特別是那些有長指令或上傳文件的對話
- 編程助手:通過在提示詞中保留相關部分或代碼庫的摘要版本,改善自動完成和代碼庫問答
- 大文件處理:在提示詞中包含完整長篇材料 (包括圖片),而不增加響應延遲
- 詳細指令集:共享廣泛的指令、程序和示例列表來微調 Claude 的響應。開發者通常在提示詞中包含一兩個示例,但使用提示詞緩存,你可以通過包含 20+ 個高質量答案的多元化示例獲得更好的性能
- 代理工具使用:提升涉及多個工具調用和迭代代碼更改的場景性能,每個步驟通常需要新的 API 調用
- 與書籍、論文、文件、播客記錄和其他長篇內容對話:通過在提示詞中嵌入整個文件,讓用戶能夠提問
常見問題解決
- 確保緩存部分在不同調用之間完全相同,並在相同位置標記了
cache_control - 檢查調用是否在緩存生存期內(5 分鐘或 1 小時)
- 驗證
tool_choice和圖片使用在調用之間保持一致 - 確認你緩存的 Token 數至少達到最小要求
- 雖然系統會嘗試使用緩存斷點之前位置的已緩存內容,但你可以使用額外的
cache_control參數來保證查找提示詞前面部分的緩存,這對於包含很長內容塊列表的查詢可能很有用
緩存儲存和共享
- 組織隔離: 緩存在組織之間是隔離的。不同組織永遠不會共享緩存,即使它們使用相同的提示詞。
- 精確匹配: 緩存命中需要 100% 相同的提示詞段,包括標記有 cache control 的塊之前及其本身的所有文本和圖片。在緩存讀取和創建期間必須用 cache_control 標記相同的塊。
- 輸出 Token 生成: 提示詞緩存不會影響輸出 Token 生成。你收到的響應將與不使用提示詞緩存時完全相同。
在客戶端 / 平台中啟用 Claude 緩存
很多客戶端的介面沒有地方直接填cache_control,而是用各自的「語法糖」或開關替你注入。底層規則與上文完全一致——被緩存的前綴必須每輪逐字不變,會變化的內容放在緩存斷點之後,否則會「只寫不讀」(見上文「常見錯誤」)。
Dify(通過 Aihubmix 外掛)
Aihubmix 的 Dify 外掛繼承了 Anthropic 官方外掛的語法糖,兩步開啟:- 用
<cache>…</cache>包裹要緩存的提示詞(固定不變的系統提示詞 / 長上下文),外掛會在該處自動轉換成cache_control斷點; - 在模型參數裡把「大消息自動緩存閾值」設為一個正整數:內容達到該 Token 閾值才會真正寫緩存(仍受下文「緩存限制」的最小緩存約束,Opus 4.5/4.6、Haiku 4.5 為 4096 Token),設 0 或留空則關閉。
Cherry Studio
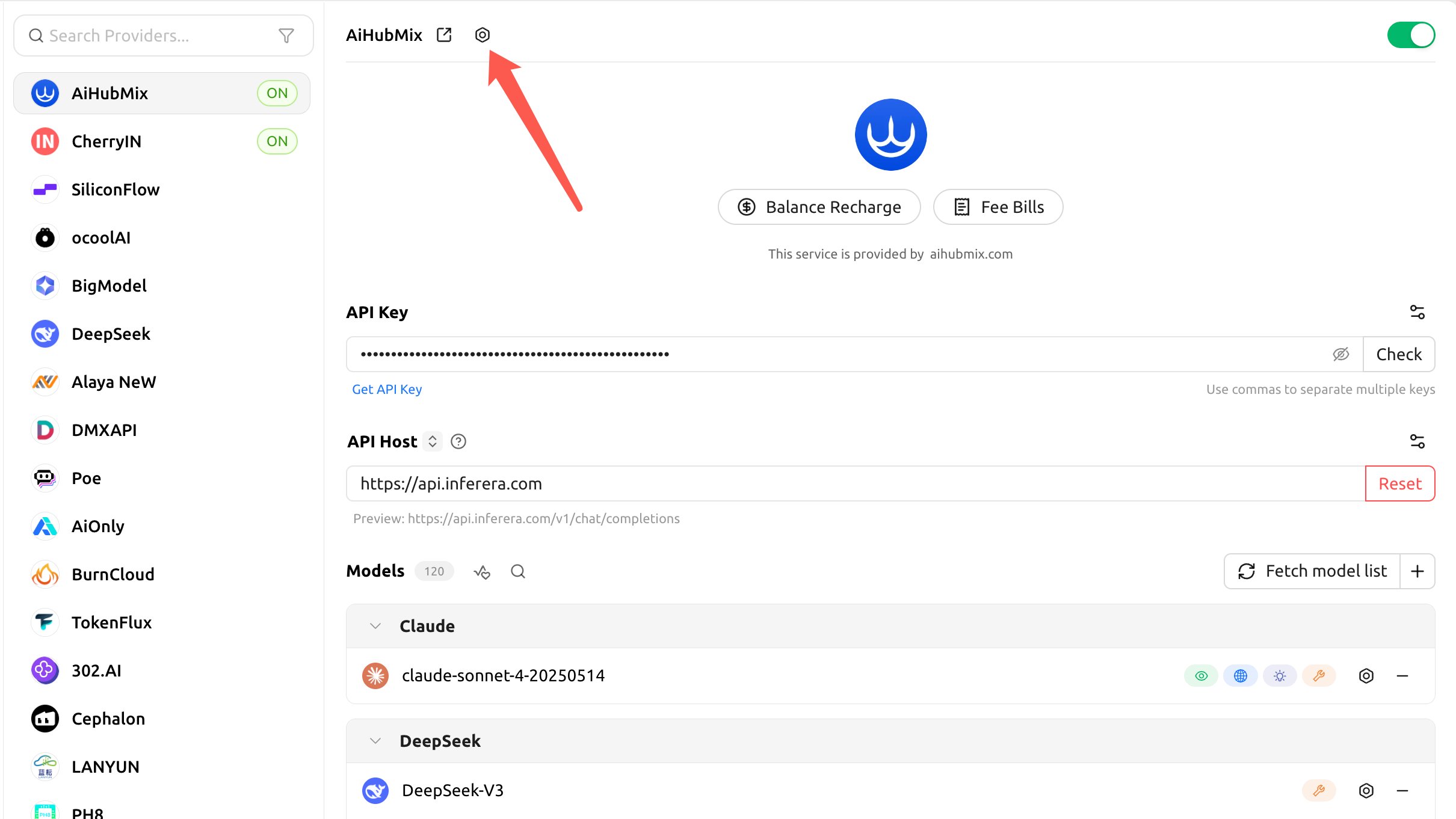
Cherry Studio 經 Aihubmix 調用 Claude 默認不開緩存(「緩存 Token 閾值」默認為0),需要在供應商的「API 設定」裡打開。
- 點擊 Aihubmix 供應商名稱右側的齒輪,打開「API 設定」(API Settings):
- 配置以下三項,客戶端會據此為 Claude 自動注入
cache_control:
- 緩存 Token 閾值(Cache Token Threshold):內容超過該 Token 數才注入緩存斷點(設正數開啟,0 或留空關閉);
- 緩存系統消息(Cache System Message):開啟後給
system消息打緩存斷點(適合緩存固定的長系統提示詞); - 緩存最後 N 條消息(Cache Last N Messages):給最近 N 條消息打緩存斷點(適合多輪對話滾動緩存)。
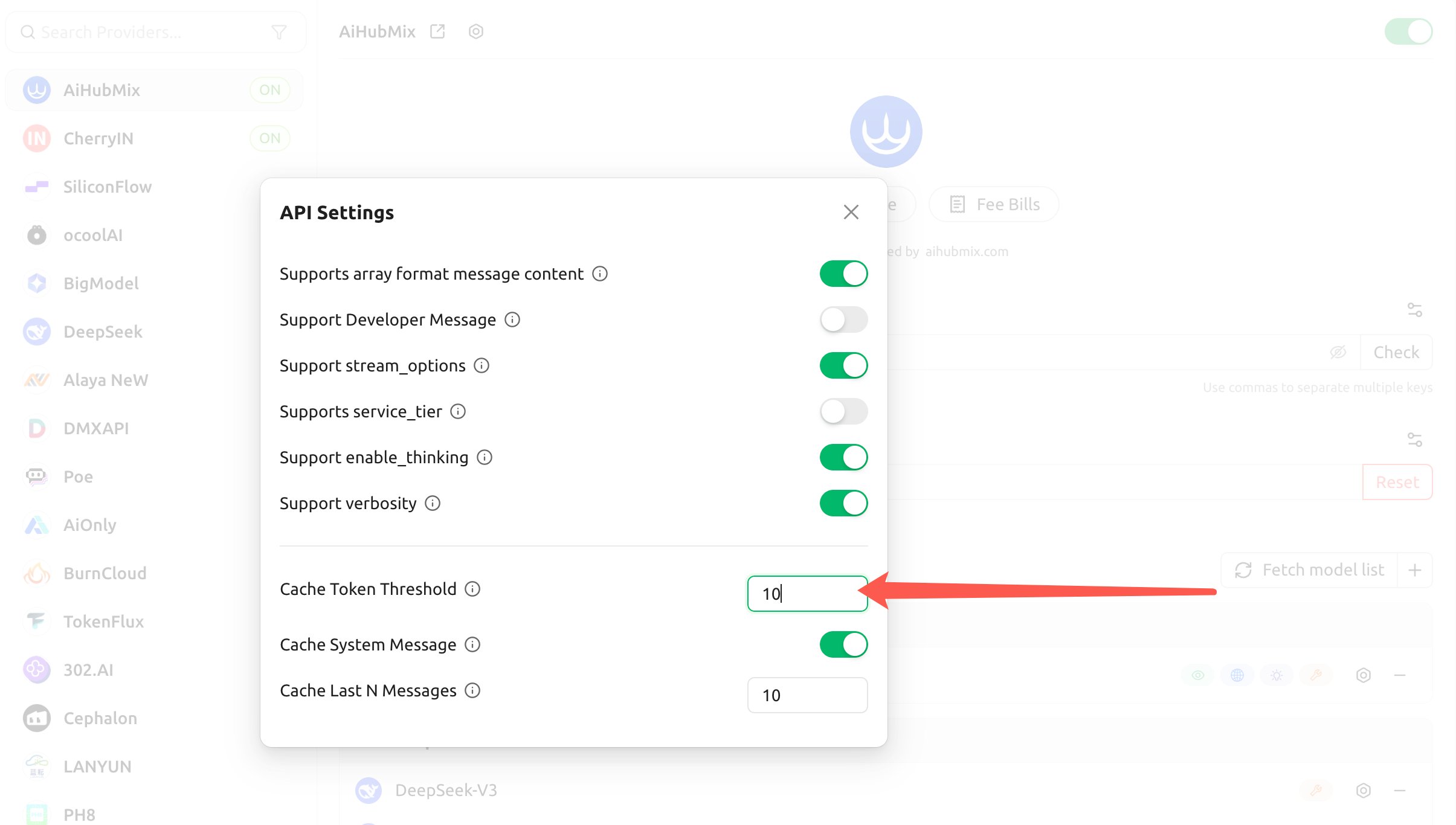
上述閾值只決定客戶端「何時注入斷點」,並不改變 Anthropic 的最小緩存要求:實際寫入仍需被緩存內容達到最小緩存 Token(Opus 4.5/4.6、Haiku 4.5 為 4096)。若把每輪會變的內容(如輪換的指令)放進被緩存的系統提示詞裡,同樣會「只寫不讀」。
常見問題(FAQ)
為什麼寫了緩存(cache_creation_input_tokens 很大)卻一直讀不到(cache_read_input_tokens 為 0)?
因為緩存斷點(cache_control)之前的內容在兩次請求之間變了。命中要求斷點及其之前的所有內容逐位元組一致;一旦把每輪會變的內容放在斷點前面,整段前綴緩存就作廢、每輪重寫。把固定內容放最前、變化內容放斷點之後即可,詳見上文「常見錯誤」。
緩存最少需要多少 Token?
低於最小緩存長度的內容即使標了cache_control 也不會緩存。Claude Opus 4.5/4.6、Haiku 4.5 為 4096 Token;其餘 Claude 模型多為 1024 Token,Haiku 3/3.5 為 2048 Token。詳見下文「緩存限制」。
緩存有效期多久?能改成 1 小時嗎?
默認 5 分鐘,每次命中都會刷新。需要更久可用 1 小時緩存(Beta):加anthropic-beta: extended-cache-ttl-2025-04-11 請求頭,並在 cache_control 中設 "ttl": "1h"。詳見下文「1 小時緩存持續時間(Beta)」。
在 Dify / Cherry Studio 裡怎麼開緩存?
這些客戶端不直接填cache_control:Dify 用 <cache>…</cache> 包裹要緩存的內容並設「大消息自動緩存閾值」;Cherry Studio 在「API 設定」裡設「緩存 Token 閾值 / 緩存系統消息 / 緩存最後 N 條消息」。詳見上文「在客戶端 / 平台中啟用 Claude 緩存」。
不同模型的支持情況
- 是否支持 Prompt Caching 賴於模型本身。
- 如果模型本身支持,並且不需要顯式聲明的參數,則通過 opanai 兼容格式轉發可以支持。
- Openai 默認支持 Prompt Caching,緩存不計費,緩存 Tokens 讀取費用減半,處於未復用狀態 5-10 分鐘之後會自動清除。文件
- Claude 需要原生的
cache_control: { type: "ephemeral" }聲明,緩存費率為常規輸入的 1.25 倍(5 分鐘)或 2 倍(1 小時),緩存 Tokens 讀取費用為 0.1 倍,生命周期 5 分鐘或 1 小時。文件 - Deepseek V3 和 R1 原生支持,緩存費率為常規輸入的 1 倍,緩存 Tokens 讀取費用為 0.1 倍。文件
- Gemini 模型支持隱式緩存:
- 隱式緩存:默認情況下為所有 Gemini 2.5 模型啟用。如果你的請求命中緩存,會自動傳遞成本節省。此功能自 2025 年 5 月 8 日起生效。上下文緩存的最低輸入 Token 數:Gemini 2.5 Flash 為 1,024,Gemini 2.5 Pro 為 2,048。
- 提高隱式緩存命中率的技巧:
- 將大塊的常見內容放在提示的前面。
- 嘗試在短時間內發送前綴相似的請求。
- 你可以在響應對象的
usage_metadata字段中查看緩存命中的 Token 數量。 - 成本節省是根據預填充緩存命中次數衡量的。只有預填充緩存和 YouTube 視頻預處理緩存支持隱式緩存。
- 提高隱式緩存命中率的技巧:
- 隱式緩存:默認情況下為所有 Gemini 2.5 模型啟用。如果你的請求命中緩存,會自動傳遞成本節省。此功能自 2025 年 5 月 8 日起生效。上下文緩存的最低輸入 Token 數:Gemini 2.5 Flash 為 1,024,Gemini 2.5 Pro 為 2,048。
最後更新:2026-06-01