Não deixe que uma indisponibilidade do upstream se torne a sua indisponibilidade.A AIHubMix oferece dois recursos no nível da Key. Configure-os uma vez no console e eles entram em vigor sem nenhuma alteração de código no cliente:
- Mapeamento de modelo é o recurso da camada de gateway que reescreve o alias do modelo em uma requisição do cliente para o modelo upstream real.
- Fallback de erro é o recurso pelo qual, quando a chamada ao modelo principal falha, o gateway tenta automaticamente os modelos reserva em uma ordem de prioridade pré-configurada, de forma transparente para o cliente.
A AIHubMix permite configurar o mapeamento de nome de modelo e o fallback em caso de erro no nível da Key, e cobra pelo modelo que efetivamente respondeu. Ambos são configurados por API Key na página de gerenciamento de Keys da AIHubMix.
Model name mapping e Fallback models on error do painel:
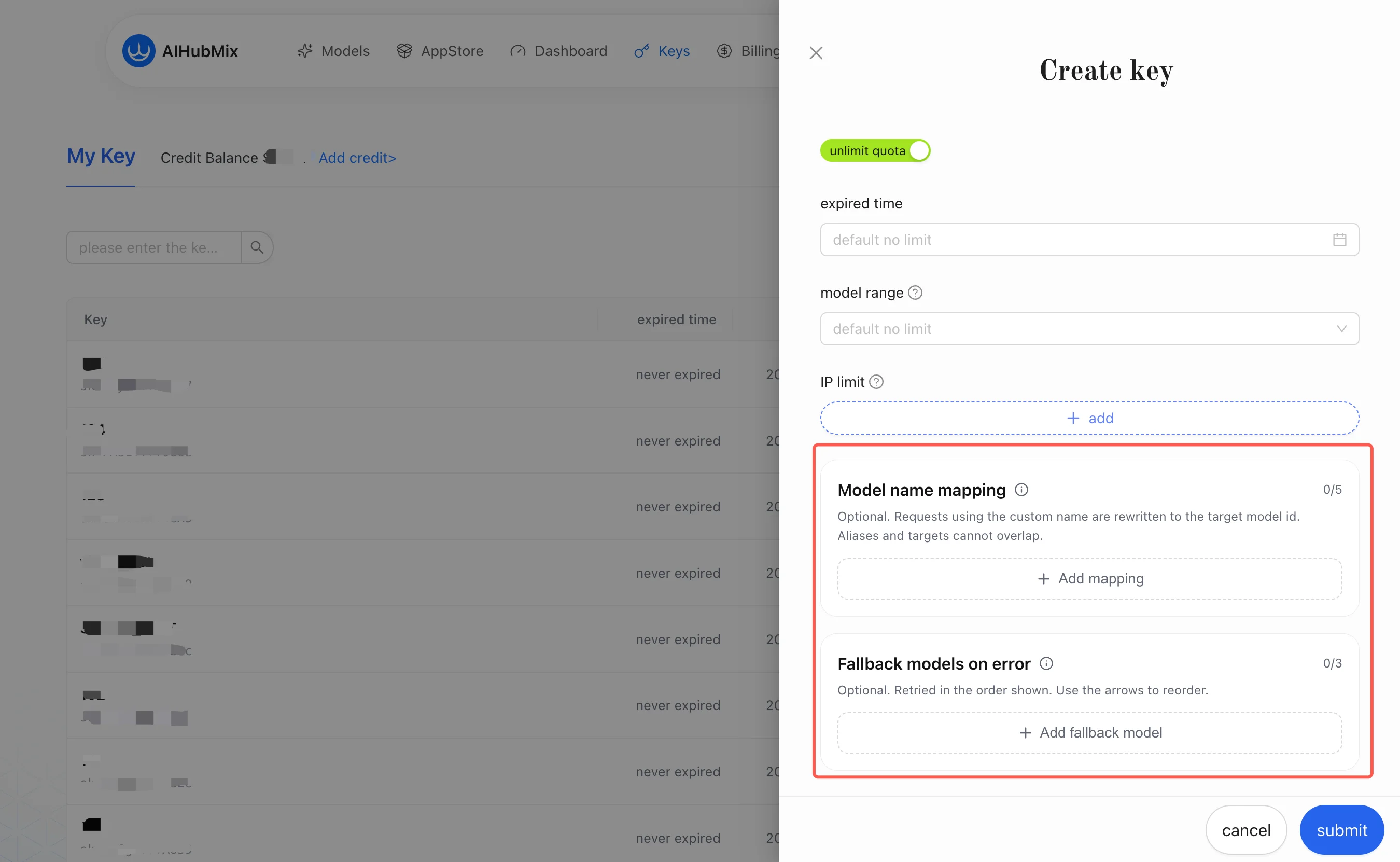
1. Mapeamento de nome de modelo
O mapeamento de nome de modelo lida com a divergência entre “o nome do modelo que o cliente vê” e “o modelo que a AIHubMix realmente chama”. É uma reescrita de alias por key: ele reescreve o alias da requisição para o modelo de destino que você configurou na Key.Depois que um canal é selecionado para o modelo de destino, a plataforma realiza internamente outro mapeamento, no nível do canal, para o modelo upstream real. Essa camada é transparente para você e não requer configuração. Você só precisa se preocupar com a camada “alias → modelo de destino”.Exemplo:
Todos os nomes de modelo da tabela acima podem ser consultados na página de modelos da AIHubMix.Usos comuns:
- O cliente restringe o formato do nome do modelo. Por exemplo, o Claude Desktop exige nomes de modelo no estilo Claude (veja a Seção 5).
- Definir um alias mais curto e estável para um Model ID complexo.
- Manter a configuração do cliente inalterada enquanto troca o modelo real no backend da AIHubMix.
- Várias plataformas compartilham um único esquema de nomes de conexão, mas roteiam para modelos diferentes com base na Key.
Correspondência caractere a caractere: O nome do modelo que o cliente envia deve corresponder ao lado esquerdo do mapeamento caractere a caractere. Por exemplo,my-gpt-5.5emy-gpt-5-5são duas strings diferentes; se não corresponderem, o mapeamento não será acionado.
2. Fallback de erro
O fallback de erro tenta os modelos reserva em ordem quando o modelo principal falha. Não é uma nova tentativa do lado do cliente; é uma troca de modelo realizada no lado do gateway da AIHubMix sob a mesma configuração de Key. O integrador não precisa passar nenhum parâmetro extra de roteamento em cada requisição. Você pode pensar no fallback como um “mapeamento para uma lista ordenada”: depois que o modelo principal falha, o gateway desce automaticamente na lista até o próximo modelo reserva. Exemplo (configurado na mesma Key):2.1 Condições de acionamento
O fallback só acontece quando todas as condições a seguir são verdadeiras:- A Key está configurada com uma lista não vazia de modelos reserva.
- Todos os canais do modelo principal foram tentados e todos falharam com um “erro recuperável” (canais esgotados).
- A resposta ainda não começou a ser retornada (o primeiro byte / cabeçalho ainda não foi enviado ao cliente).
- O erro não é um erro no nível da Key / do usuário (veja a tabela comparativa da 2.2 abaixo).
2.2 O que faz fallback e o que não faz
Observação: “Key inválida” aqui significa que sua própria Key da AIHubMix está inválida, o que não faz fallback. Se a key de algum canal upstream estiver com problema, o gateway troca de canal e, depois que os canais se esgotam, ele ainda pode fazer fallback. Não confunda os dois.
2.3 Base de cobrança
Cobrança pelo modelo que efetivamente respondeu. Se o modelo de fallback for o que responde no final, a cobrança, as capacidades e os limites de contexto são todos baseados no modelo que efetivamente respondeu. Esse modelo também é refletido no cabeçalho da resposta (veja a Seção 4).2.4 Regra de modelo gratuito
Um modelo gratuito não pode ser usado como opção de fallback — um modelo gratuito só pode ser o modelo principal. Colocá-lo na lista de reserva faz com que ele seja silenciosamente pulado e o gateway continua para a próxima entrada. Portanto, não coloque modelos gratuitos na lista de fallback.Uso típico: Defina um modelo gratuito como modelo principal e coloque modelos pagos na lista de reserva. Quando o modelo principal gratuito atinge uma cota / limite de taxa, ele faz fallback automaticamente para um modelo reserva pago. Normalmente você economiza usando a cota gratuita e, após o limite de taxa, troca perfeitamente para um modelo pago para garantir disponibilidade. Este é um dos usos mais comuns do fallback.
3. AIHubMix vs OpenRouter / LiteLLM
Mapeamento e fallback de modelos não são conceitos novos; OpenRouter, LiteLLM e outros oferecem capacidades semelhantes. O que diferencia a AIHubMix é o menor custo de configuração:
Em uma frase: Sem gateway próprio, sem uma única linha de código alterada no cliente — configure uma vez na Key e ele entra em vigor.
4. Configuração e verificação
4.1 Configuração
- Configure o mapeamento de alias na Key: o alias à esquerda deve corresponder ao nome do modelo que o cliente realmente envia caractere a caractere.
- Configure a lista de modelos reserva (uma lista ordenada por prioridade) na mesma Key.
- A lista de reserva deve conter apenas modelos pagos / disponíveis, não modelos gratuitos (eles serão pulados).
- Os modelos da lista de reserva devem estar dentro da faixa de modelos disponíveis da Key (modelos fora do escopo serão pulados).
4.2 Verificação (verifique primeiro os cabeçalhos da resposta, não os logs)
Ao investigar problemas, não olhe apenas qual modelo o cliente selecionou. A forma mais confiável e automatizável é ler os cabeçalhos da resposta:X-Aihubmix-Fallback: true: ocorreu um fallback nesta requisição (adicionado quando o modelo final ≠ o modelo principal).X-Aihubmix-Model: o modelo que efetivamente respondeu nesta requisição e foi cobrado de acordo.
5. Cenário Um Claude Desktop
O Claude Desktop se conecta à AIHubMix através doGateway, um cenário típico de mapeamento de nome de modelo.
Esta seção pressupõe que você já concluiu a integração básica do Claude Desktop. Para o passo a passo completo da integração (download e instalação, modo desenvolvedor, configuração do Gateway, esquema de autenticação etc.), veja Conectar a AIHubMix no Claude Desktop. Esta seção cobre apenas a configuração incremental para mapeamento e fallback.
5.1 Por que o mapeamento é necessário
O Claude Desktop se conecta viaGateway (compatível com Anthropic), e o cliente restringe os nomes de modelo ao estilo Claude, de modo que os nomes de modelo precisam usar o prefixo claude-.
Isso cria um conflito: o lado do cliente só consegue escrever nomes no estilo claude-, mas o que você realmente quer chamar é gpt-5.5, gemini-3.1-pro-preview e similares. O mapeamento de nome de modelo foi feito exatamente para isso — o cliente escreve o alias claude-g-p-t-5.5, e a AIHubMix o mapeia para o gpt-5.5 real.
O Claude Desktop usa a interface nativa /v1/messages do Claude, então, nos exemplos deste artigo, tanto o mapeamento quanto o Fallback entram em vigor.
5.2 Configuração de mapeamento e Fallback na AIHubMix
Exemplo de configuração: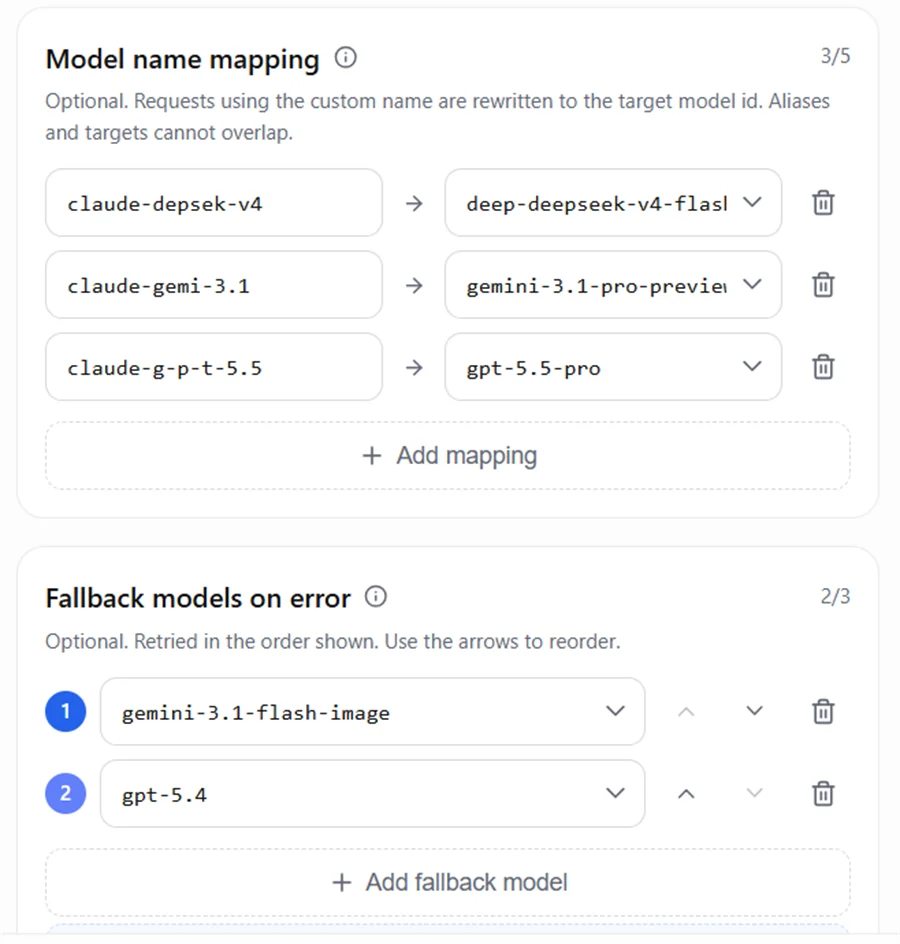
5.3 Lista de modelos do Claude Desktop
O que você configura naModel list do Claude Desktop é o alias antes do mapeamento — ou seja, o nome de modelo que o Claude Desktop envia para a AIHubMix, não o nome do modelo upstream real.
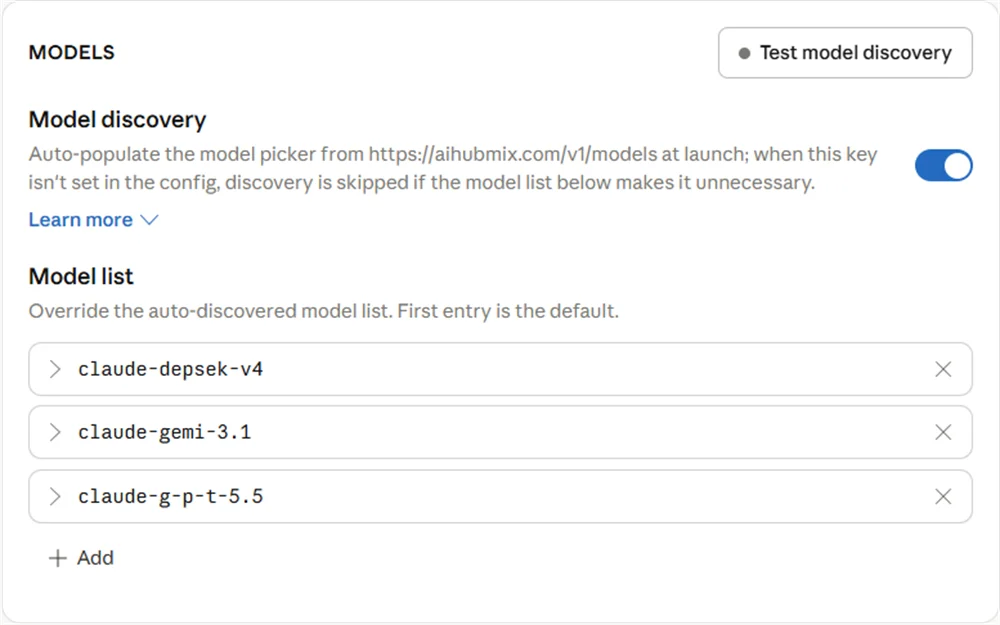
- Use o prefixo
claude-para oModel ID. - Não escreva diretamente nomes reais de famílias de modelos como
gpt,geminioudeepseek; use aliases comog-p-t,gemi,depsek. - O
Model IDdeve corresponder ao lado esquerdo do mapeamento da AIHubMix caractere a caractere, caso contrário a requisição não acionará o mapeamento esperado e poderá continuar descendo até o modelo de fallback de erro.
6. Cenário Dois Fallback de capacidade multimodal
O fallback de capacidade multimodal lida com o cenário em que “o modelo principal consegue responder texto, mas não suporta o tipo de entrada atual”. Por exemplo, o cliente envia uma imagem ou vídeo enquanto o modelo principal só tem capacidade de entrada de texto; a AIHubMix pode continuar tentando modelos da lista de fallback que suportem a modalidade correspondente. Abaixo está um caminho de teste real. A configuração de mapeamento e fallback desta Key é a seguinte (veja a captura de tela abaixo). O ponto-chave é que a lista de fallback contém tanto um modelo de texto quanto um modelo que suporta entendimento de imagem:claude-g-l-m-4.6 — um modelo que só suporta entrada de texto. O usuário enviou uma captura de tela da página da lista de modelos da AIHubMix e perguntou “para que serve este site”. Como a requisição continha uma imagem, o modelo de texto não conseguiu lidar diretamente com a entrada, o que acionou o fallback.
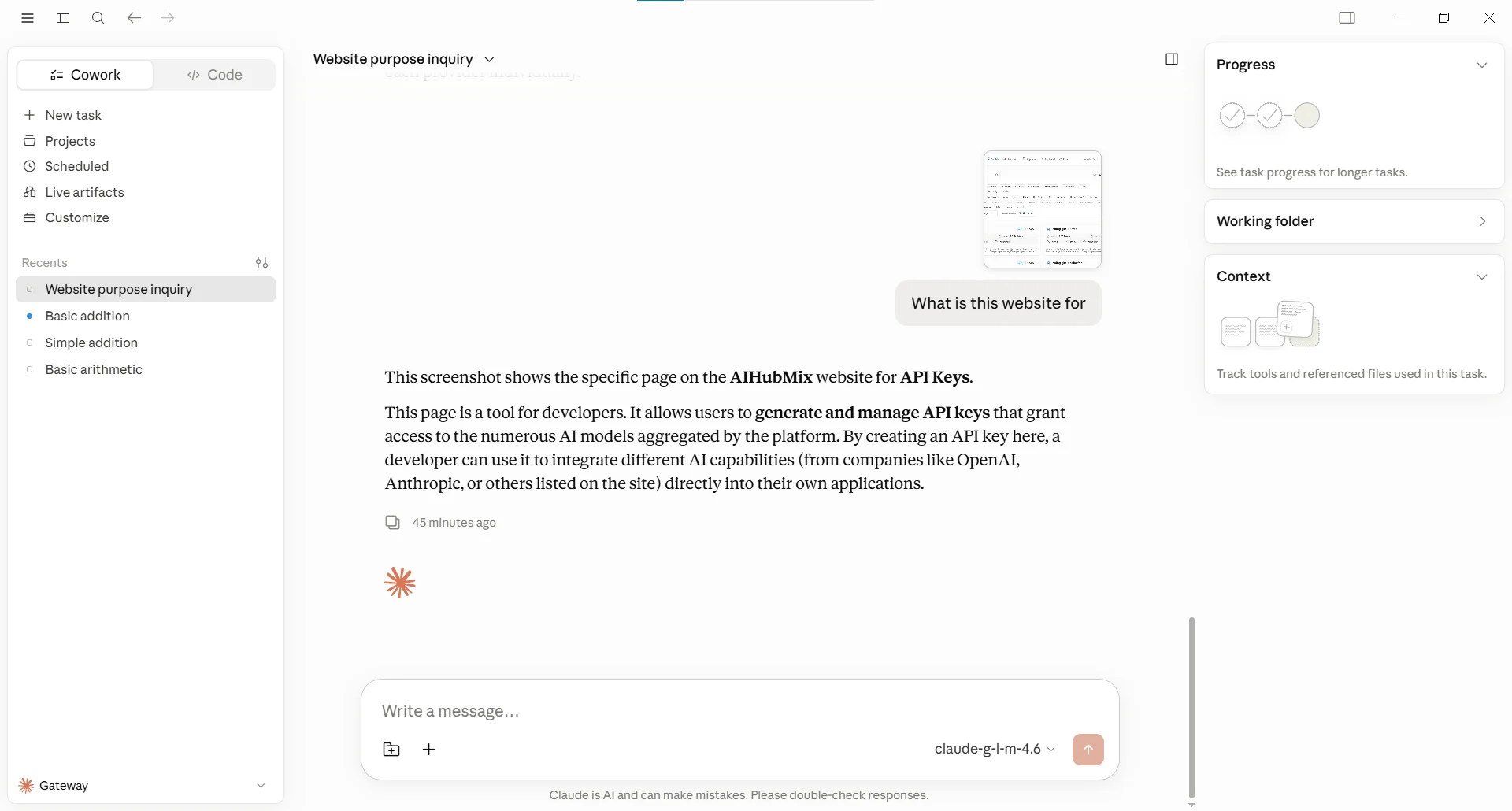
Google AI Studio/gemini-3.1-flash-image, a 2ª entrada da lista de fallback. A 1ª entrada, gpt-5.4, também não suporta essa entrada de imagem e continuou retornando um erro recuperável para esta requisição, então o gateway continuou descendo e parou em gemini-3.1-flash-image, que suporta entendimento de imagem.
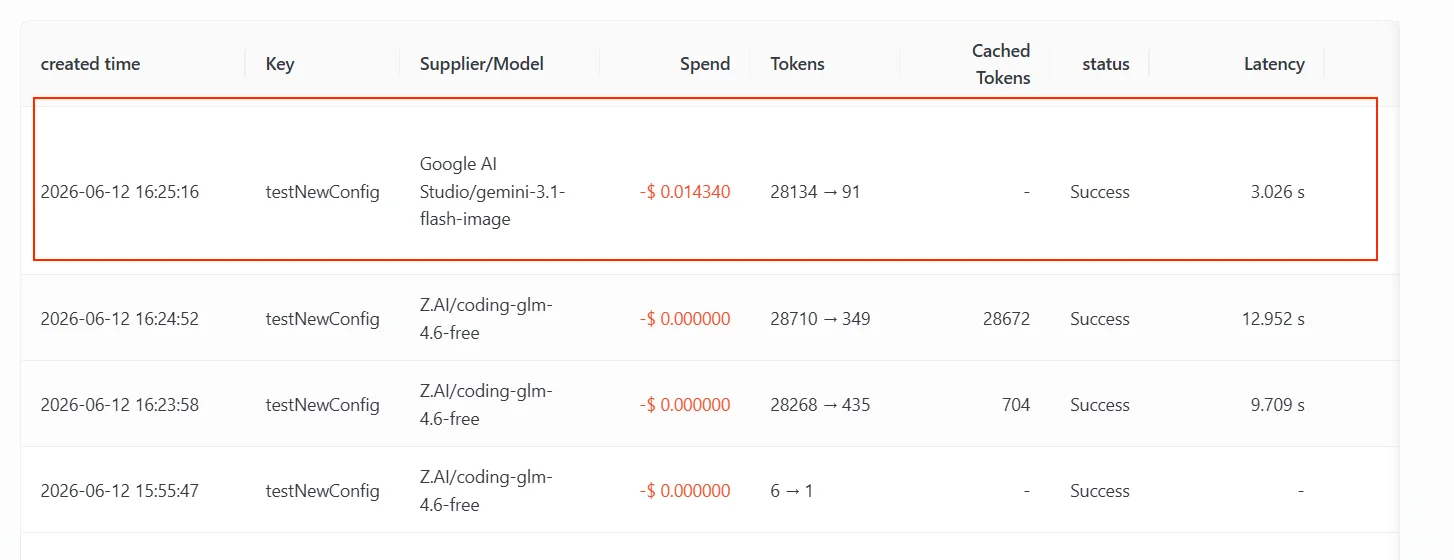
Tenha clareza sobre o motivo do acionamento: O fallback aqui acontece porque o upstream retornou um erro recuperável para esta entrada de imagem e os canais do modelo principal se esgotaram — é o mesmo mecanismo de fallback de “fazer fallback depois que o modelo principal atinge o limite de taxa”, apenas acionado por um tipo de erro diferente (o primeiro é entrada não suportada, o segundo é uma cota / limite de taxa).
Distinga entendimento de geração: Isto se refere ao fallback de entendimento de imagem / vídeo, não de geração de imagem ou geração de vídeo. Uma requisição de chat não se transforma automaticamente em um endpoint de geração; para testar desenho ou geração de vídeo, você deve usar o endpoint e o modelo de geração correspondentes. As capacidades do modelo são determinadas pelas Input Modalities atualmente marcadas na página de modelos da AIHubMix.
7. Cenário Três Fallback de modelo gratuito
Este é um dos usos mais comuns do fallback: definir um modelo gratuito como modelo principal e colocar modelos pagos na lista de reserva. Normalmente todas as requisições passam pelo modelo gratuito e economizam custo; assim que o modelo principal gratuito atinge uma cota / limite de taxa, o gateway faz fallback automaticamente para um modelo reserva pago, garantindo que o serviço não seja interrompido. Exemplo de configuração de Key:- Enquanto a cota gratuita ainda for suficiente, a requisição é respondida pelo modelo principal
coding-glm-5.2-freee cobrada como gratuita. - Depois que o modelo principal gratuito atinge o limite de taxa, ele faz fallback automaticamente para
gpt-5.4; segpt-5.4também estiver indisponível, ele tenta entãogemini-3.1-pro-preview. - Qualquer modelo que responda no final é aquele pelo qual você é cobrado (veja a 2.3).
Observação: Um modelo gratuito só pode ser o modelo principal e não pode ser colocado na lista de fallback (se você o fizer, ele será pulado; veja a 2.4). Portanto, a forma correta de fazer “fallback de modelo gratuito” é: gratuito como principal, pago como reserva, e não o contrário.A verificação é novamente feita lendo os cabeçalhos da resposta: quando ocorre um fallback,
X-Aihubmix-Fallback: true é retornado, e X-Aihubmix-Model mostra o modelo que efetivamente respondeu (veja a Seção 4).
8. Endpoints suportados
O mapeamento de modelo e o fallback de erro atualmente suportam as seguintes categorias de interface:
Pontos-chave:
- O mapeamento de modelo e o fallback de erro suportam três categorias de interface: interfaces compatíveis com OpenAI, nativa do Claude
/v1/messagese OpenAI Responses/v1/responses. - Outras interfaces de passthrough nativo (Gemini nativo, Ideogram, vídeo, TTS, Stability, OCR, predictions etc.), passthrough de canal específico e interfaces de recuperação por ID de recurso / tipo de arquivo ainda não são suportadas.
- O Claude Desktop usa a interface nativa
/v1/messagesdo Claude, então, nos exemplos deste artigo, tanto o mapeamento quanto o Fallback entram em vigor.
9. FAQ
P: O que devo fazer se o Claude Desktop mostrar “model not found”? R: Verifique se oModel ID no Claude Desktop corresponde ao lado esquerdo do mapeamento da AIHubMix caractere a caractere; se não corresponderem, o mapeamento não será acionado.
P: O fallback afeta a cobrança?
R: Cobrança pelo modelo que efetivamente respondeu. Qualquer que seja o modelo que responda no final, você é cobrado com base no preço, nas capacidades e nos limites de contexto desse modelo.
P: Como confirmo se esta requisição realmente usou fallback?
R: Olhe os cabeçalhos da resposta X-Aihubmix-Fallback: true (ocorreu um fallback) e X-Aihubmix-Model (o modelo que efetivamente respondeu); veja a Seção 4.
P: Quais erros acionam o fallback e quais não?
R: Veja a tabela comparativa da 2.2. Em resumo: o fallback só acontece em uma falha recuperável do upstream, com canais esgotados e a resposta ainda não iniciada; canal específico, resposta já iniciada, desconexão / timeout do cliente e erros no nível da Key / do usuário não fazem fallback.
P: Um modelo gratuito pode ser colocado na lista de fallback?
R: Não, ele será pulado. Um modelo gratuito só pode ser o modelo principal.
P: Em que isso difere do alias de modelo / fallback do OpenRouter / LiteLLM?
R: A AIHubMix é no nível da Key e gerenciada pela plataforma — configure uma vez no console e ela entra em vigor, sem alteração de código no cliente e sem gateway próprio. Veja a Seção 3 para detalhes.
Recursos relacionados
- Conectar a AIHubMix no Claude Desktop: passo a passo completo do modo desenvolvedor, configuração do Gateway, esquema de autenticação e mais.
- Página de modelos da AIHubMix: consulte nomes de modelo, preços e
Input Modalities. - Conectar a AIHubMix no LiteLLM: uma referência para quando você precisa de um gateway próprio + mapeamento / fallback de modelo.