Instalação com Um Clique do Plugin Aihubmix
Basta clicar no link abaixo e pressionar o botão Instalar na página do Dify Marketplace: 👉 Ir para a Página do Plugin Dify Imagem de exemplo: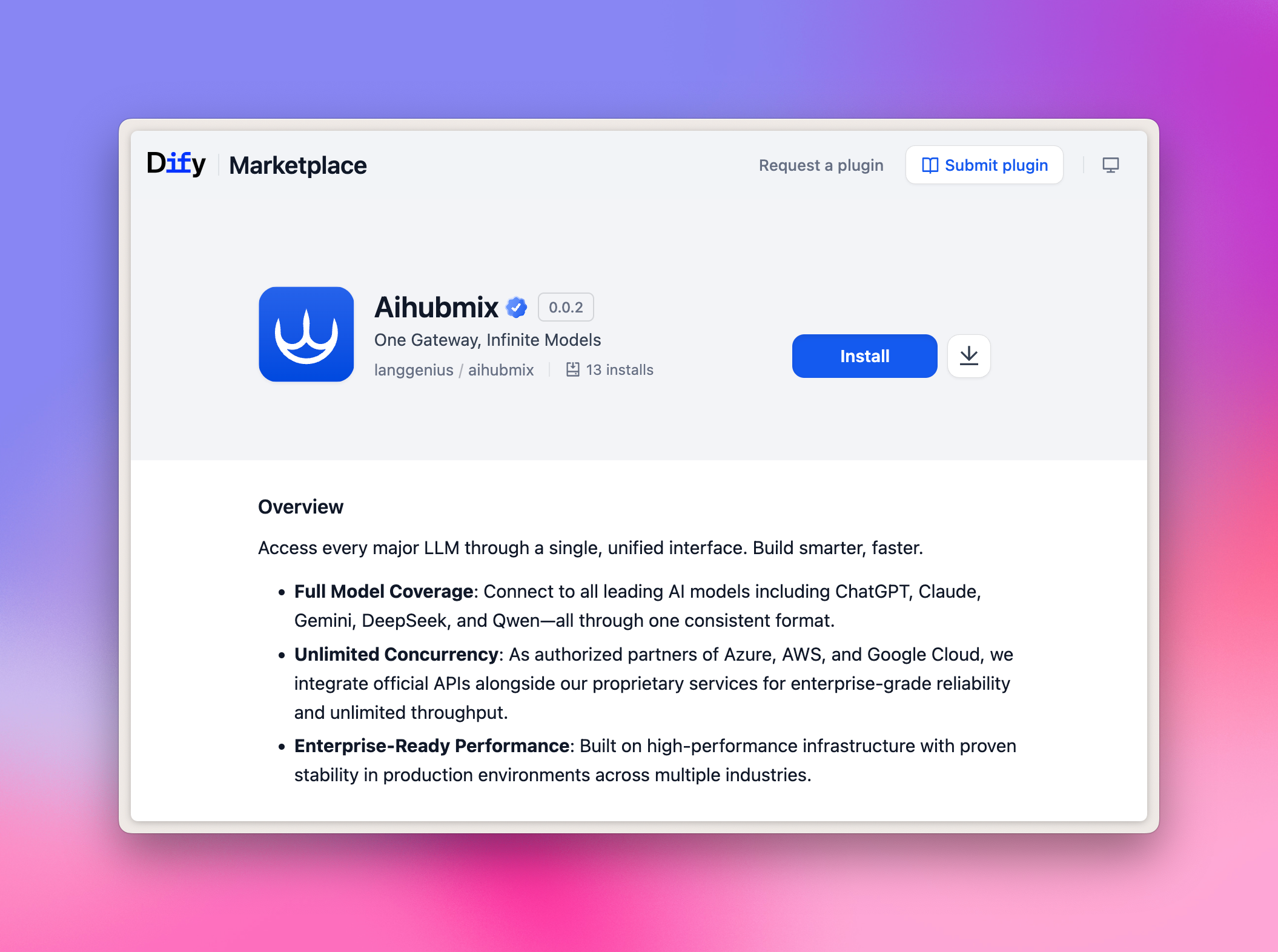
Configuração
- Clique no avatar no canto superior direito da página → Selecione ‘Configurações’
- Clique na aba ‘Provedor de Modelos’
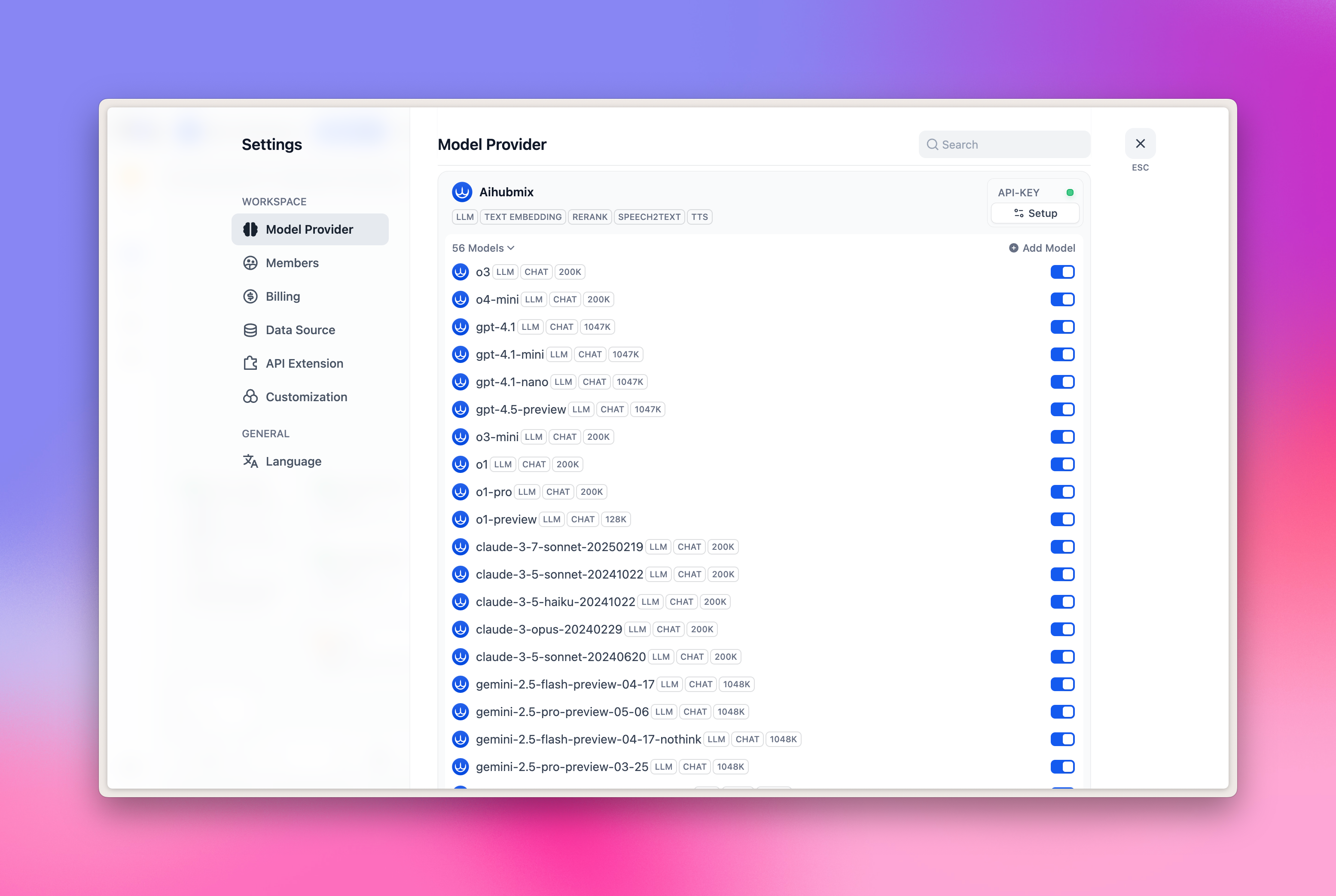
- Encontre a Aihubmix no lado direito → Expanda Configuração e preencha sua chave de API
 Atualmente, as seguintes 5 categorias de modelos estão pré-configuradas:
Atualmente, as seguintes 5 categorias de modelos estão pré-configuradas:
- LLM: Grande modelo de linguagem
- TEXT EMBEDDING: Modelo de embedding vetorial
- RERANK: Modelo de re-ranking
- SPEECH2TEXT: Modelo de fala-para-texto
- TTS: Modelo de texto-para-fala
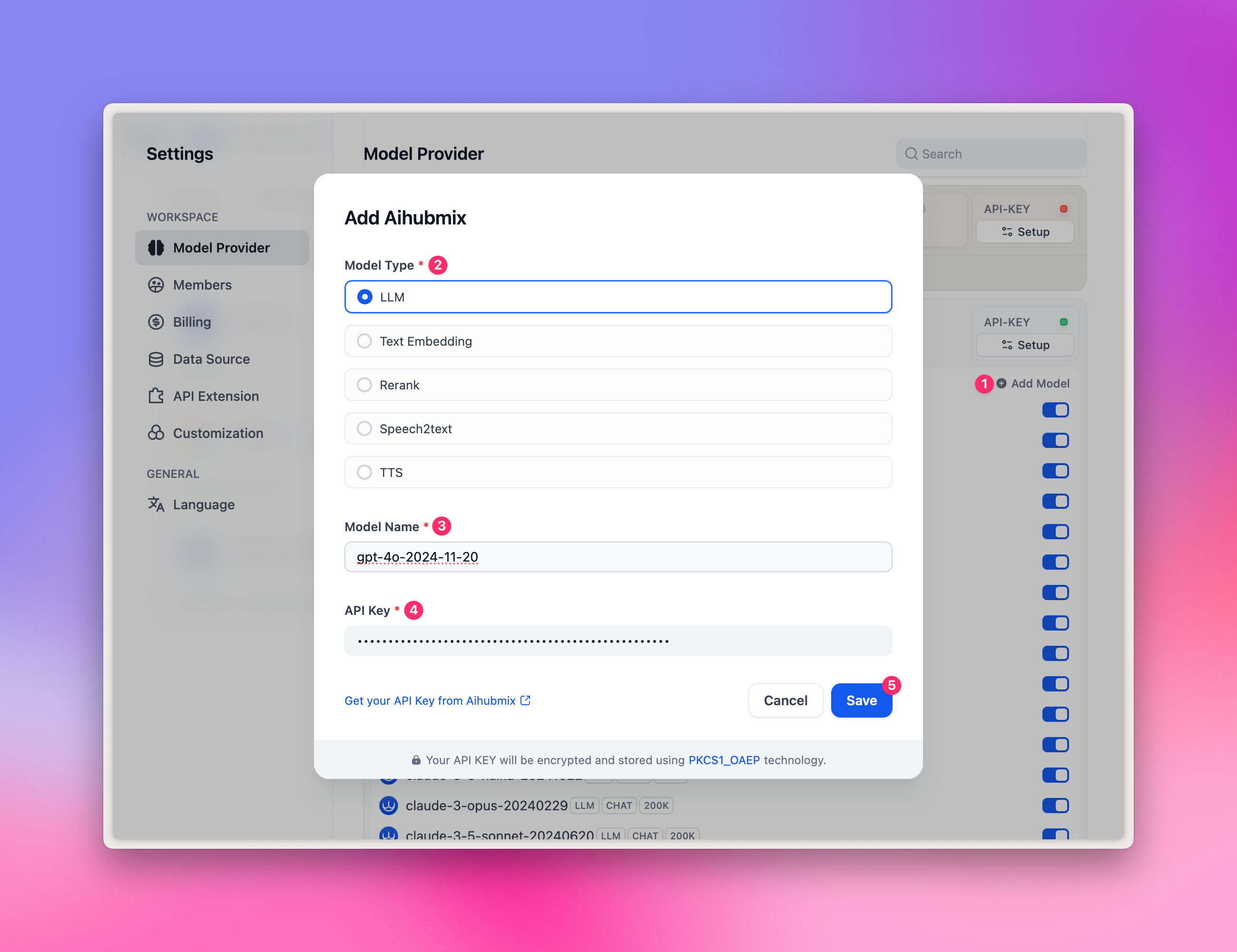
- Preencha com qualquer ID de modelo da galeria de modelos, como
gpt-4o-2024-11-20. - Preencha sua chave de API e clique em ‘Salvar’.
gpt-image-1 não podem ser adicionados.
Seleção de LLM
Não nó Workflow, selecione ‘LLM’, e você poderá selecionar os modelos fornecidos pela Aihubmix. Imagem de exemplo: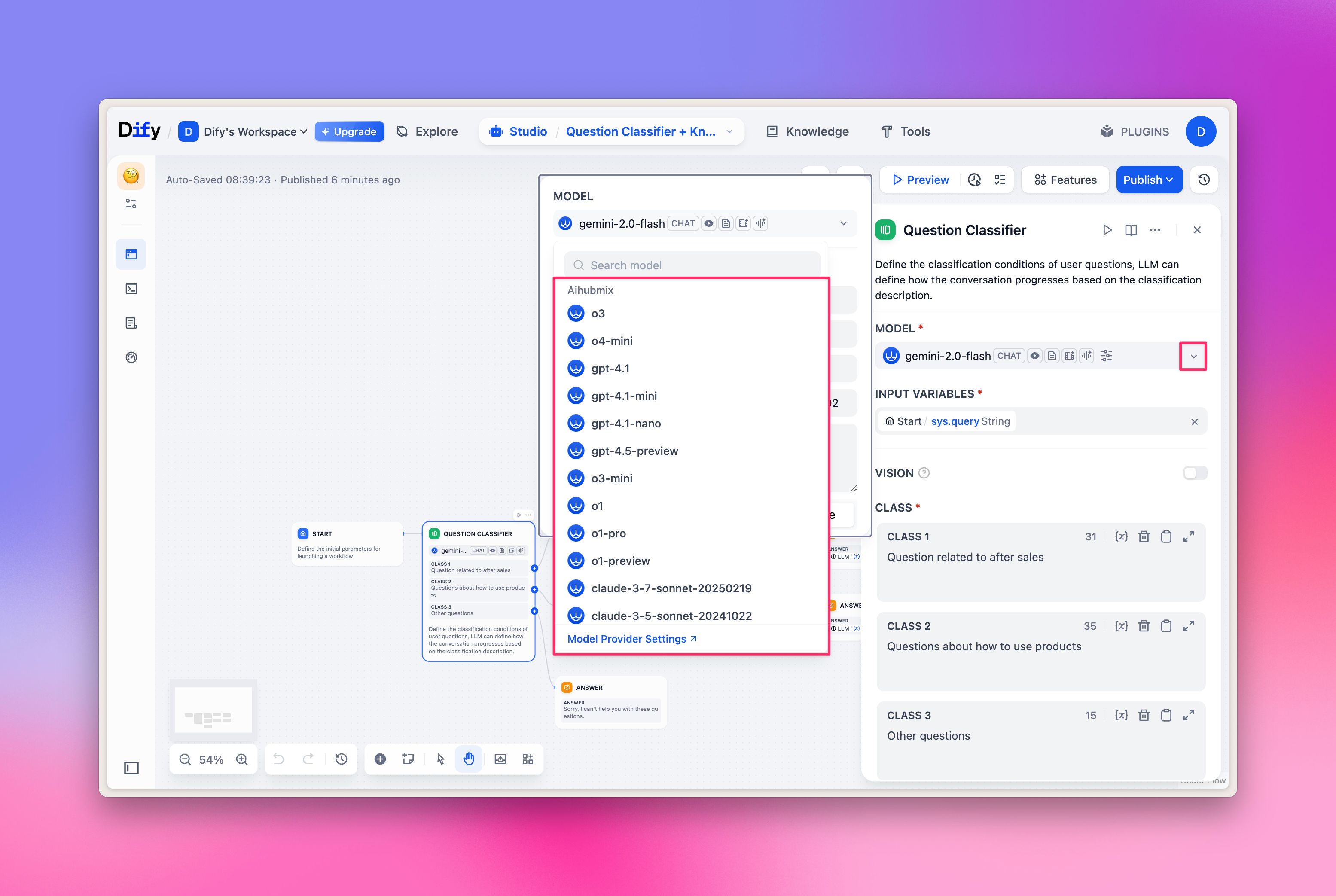
Seleção do modelo de Embeddings/Reranker
Os modelos de Embeddings/Reranker são usados principalmente para perguntas e respostas em base de conhecimento; você pode experimentá-los rapidamente na aba Knowledge no topo, e também selecionar o modelo correspondente no nó Workflow. Imagem de exemplo: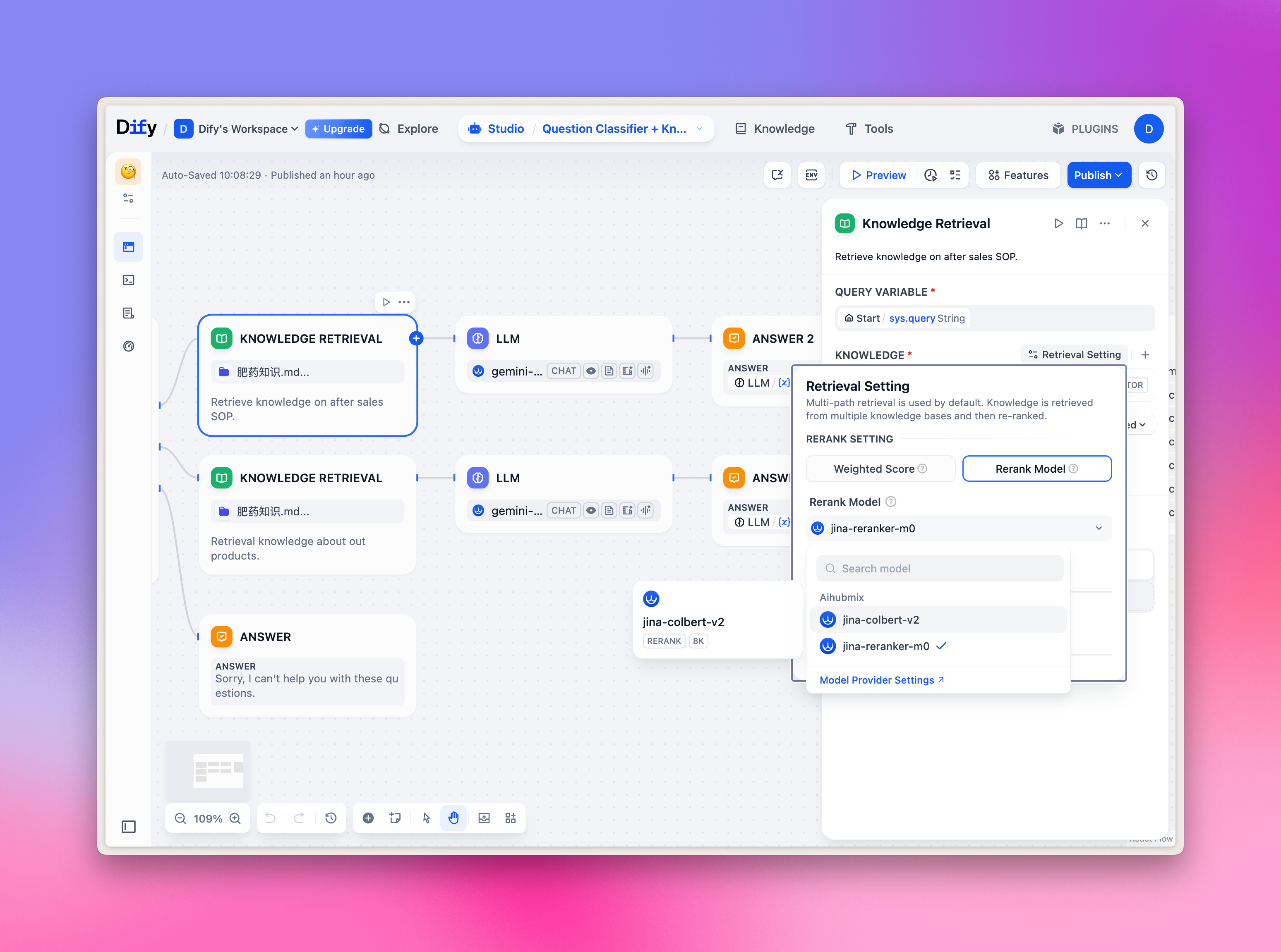
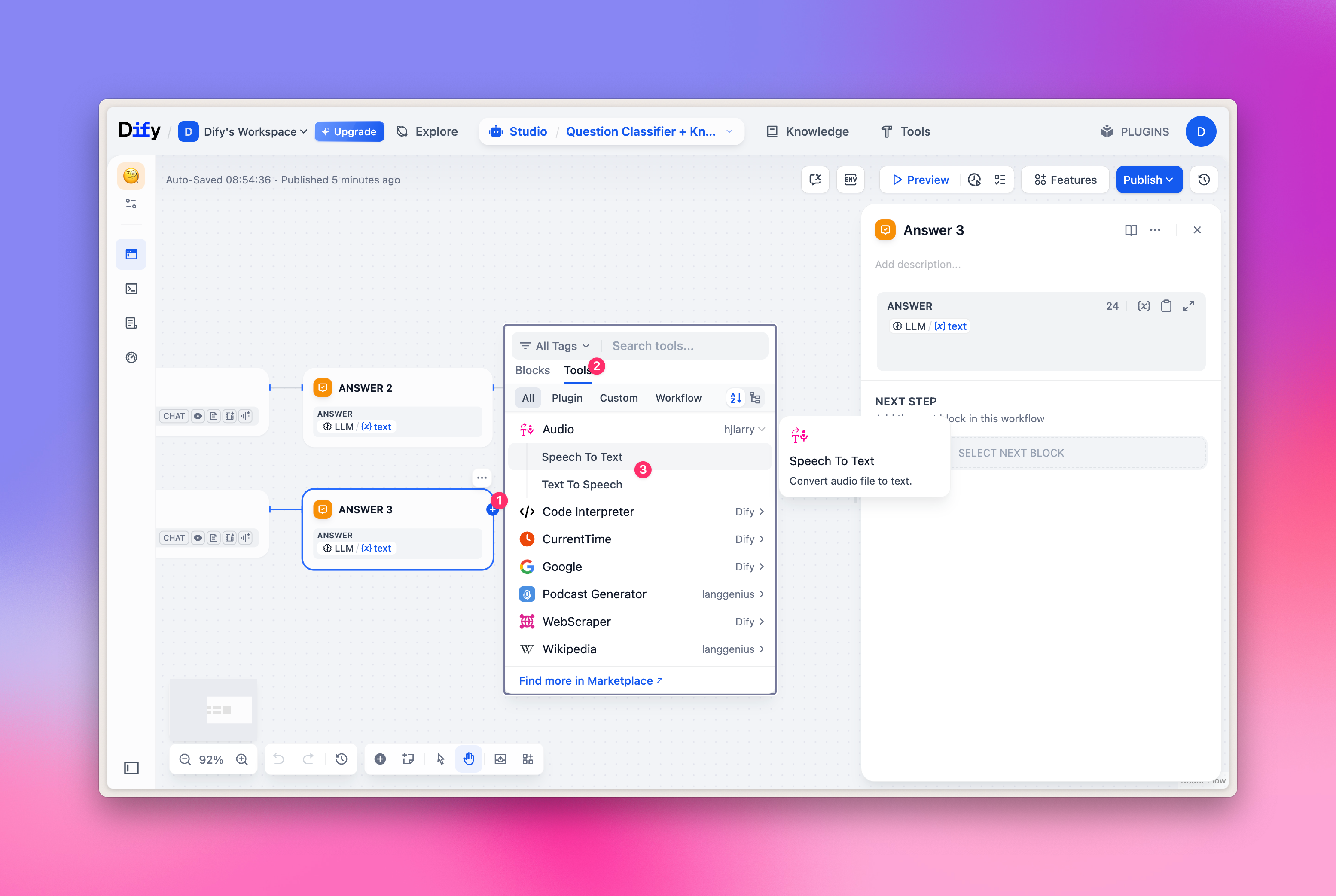
Seleção de TTS/SST
Os modelos TTS/SST são usados principalmente para análise e síntese de fala; ao selecionar ferramentas, o correspondente não é o ‘LLM’ regular, mas o tipo ‘Audio’ na aba ‘Tools’. Relação correspondente:- TTS texto-para-fala: selecione ‘Text to Speech’
- SST fala-para-texto: selecione ‘Speech to Text’
Cache de Prompt do Claude
Para habilitar o cache de prompt para modelos Claude no Dify por meio deste plugin: envolva o prompt a ser cacheado com<cache>…</cache> e defina o “limite de cache automático para mensagens grandes” nos parâmetros do modelo como um inteiro positivo. O uso completo e os pontos-chave para acertar o cache estão em Cache de Prompt do Claude.
Última atualização: 2026-06-01