Diferentes modelos Claude têm limites mínimos de cache diferentes (512 / 1.024 / 2.048 / 4.096 tokens), e esse valor não acompanha o número da versão: por exemplo, Opus 4.8 = 1.024, Opus 4.7 = 2.048, e Opus 4.6/4.5 e Haiku 4.5 = 4.096. A tabela completa por faixa está na seção “Limitações do cache” abaixo. Conteúdo abaixo do limite não é escrito no cache mesmo marcado com
cache_control, e nenhum erro é retornado.Como funciona o cache de prompt
Quando você envia uma requisição com o cache de prompt habilitado:- O sistema verifica se um prefixo de prompt, até um ponto de quebra de cache especificado, já está cacheado de uma consulta recente.
- Se encontrado, ele usa a versão cacheada, reduzindo o tempo de processamento e os custos.
- Caso contrário, processa o prompt completo e cacheia o prefixo assim que a resposta começa. Isso é especialmente útil para:
- Prompts com muitos exemplos
- Grandes quantidades de contexto ou informações de background
- Tarefas repetitivas com instruções consistentes
- Conversas longas com múltiplos turnos
Erro comum: escrever no cache mas “só escrever, nunca ler”
O cenário de falha mais comum é este: em cada turno a requisição temcache_creation_input_tokens alto (sempre escrevendo no cache), mas cache_read_input_tokens permanece 0 (nunca lê), o que equivale a não economizar nada.
A causa raiz é única: o conteúdo anterior ao ponto de quebra de cache (cache_control) mudou entre duas requisições. Um acerto de cache exige que o ponto de quebra e todo o conteúdo anterior a ele (na ordem tools → system → messages) sejam idênticos byte a byte; basta que um único caractere antes do ponto de quebra mude para que todo o cache do prefixo seja invalidado e reescrito.
❌ Forma errada: colocar a pergunta que muda a cada turno antes do ponto de quebra
✅ Forma correta: documento grande primeiro + ponto de quebra + pergunta no final
Comparação real (claude-opus-4-6, com alguns segundos de intervalo entre as duas chamadas)
Pontos-chave:
- Coloque o bloco fixo e grande (documento de referência, contexto longo) bem no início da mensagem
useremmessages, com ocache_controlmarcado em seu final, e esse conteúdo não pode mudar nem um caractere; - Coloque a pergunta/instrução que muda a cada turno depois do ponto de quebra (após o documento grande na mesma mensagem
user, ou em mensagens subsequentes); em conversas de múltiplos turnos, apenas acrescente ao final, sem voltar para modificar mensagens do histórico; - Com
thinkinghabilitado, os blocos de thinking dos turnos de assistente anteriores devem ser reenviados sem alteração, caso contrário o prefixo também será quebrado (veja “O que não pode ser cacheado” abaixo); - Se um bloco for menor que o limite mínimo de cache (varia de 512 a 4.096 tokens conforme o modelo, veja a seção “Limitações do cache” abaixo), ele não será escrito no cache mesmo marcado com
cache_control— isso é comportamento esperado, veja “Limitações do cache” abaixo.
Preços
O cache de prompt introduz uma nova estrutura de preços. A tabela abaixo mostra o preço por milhão de tokens para cada modelo suportado:
Observação:
- Tokens de escrita de cache de 5 minutos são 1,25 vezes o preço base dos tokens de entrada
- Tokens de escrita de cache de 1 hora são 2 vezes o preço base dos tokens de entrada
- Tokens de leitura de cache são 0,1 vezes o preço base dos tokens de entrada
- Tokens regulares de entrada e saída são cobrados às taxas padrão da plataforma
Como implementar o cache de prompt
Modelos suportados
Todos os modelos da linha Claude da Anthropic suportam o cache de prompt, incluindo os atuais Opus 4.8/4.7/4.6/4.5, Sonnet 5/4.6/4.5, Haiku 4.5 e Fable 5, além dos anteriores Opus 4, Sonnet 4, Sonnet 3.7, Sonnet 3.5, Haiku 3.5, Haiku 3 e Opus 3. O limite mínimo de cada modelo está na seção “Limitações do cache” abaixo.Cache automático (cache_control de nível superior)
Adicione um campocache_control no nível superior do corpo da requisição para habilitar o cache automático: o sistema aplica automaticamente o ponto de quebra de cache ao último bloco cacheável e o move para frente à medida que a conversa cresce, o que é adequado para cache rolante em conversas de múltiplos turnos. O ponto de quebra automático ocupa 1 dos 4 slots de ponto de quebra e pode ser combinado com pontos de quebra explícitos em nível de bloco. O Amazon Bedrock não suporta o cache automático.
Estruturando seu prompt
Coloque o conteúdo estático (definições de ferramentas, instruções de sistema, contexto, exemplos) no início do seu prompt. Marque o fim do conteúdo reutilizável para cache usando o parâmetrocache_control.
Os prefixos de cache são criados na seguinte ordem: tools, system, depois messages.
Usando o parâmetro cache_control, você pode definir até 4 pontos de quebra de cache, permitindo cachear diferentes seções reutilizáveis separadamente. Para cada ponto de quebra, o sistema verificará automaticamente se há acertos de cache em posições anteriores e usará o prefixo correspondente mais longo, se encontrado.
Limitações do cache
O comprimento mínimo de prompt cacheável é:
Prompts mais curtos não podem ser cacheados, mesmo se marcados com
cache_control. Quaisquer requisições para cachear menos do que esse número de tokens serão processadas sem cache. Para ver se um prompt foi cacheado, veja os campos de uso na resposta.
Para requisições concorrentes, observe que uma entrada de cache só fica disponível após o início da primeira resposta. Se precisa de acertos de cache para requisições paralelas, espere pela primeira resposta antes de enviar requisições subsequentes.
Vidas úteis de cache suportadas atualmente:
- “ephemeral”: Vida útil padrão de 5 minutos
- Cache de 1 hora: Defina
"ttl": "1h"emcache_control, para cenários que requerem duração de cache mais longa
Duração de cache de 1 hora
Para cenários que requerem duração de cache mais longa, fornecemos uma opção de cache de 1 hora. Basta incluirttl na definição de cache_control; nenhum cabeçalho adicional é necessário:
Quando usar cache de 1 hora
O cache de 1 hora é particularmente adequado para:- Processamento em lote: Processar grandes volumes de requisições com prefixos comuns
- Sessões de longa duração: Conversas que requerem manutenção de contexto por períodos prolongados
- Análise de documentos grandes: Múltiplos tipos diferentes de análise no mesmo documento
- Q&A em codebase: Múltiplas consultas no mesmo codebase por períodos prolongados
Misturando diferentes TTLs
Você pode misturar diferentes durações de cache na mesma requisição:O que pode ser cacheado
Cada bloco na requisição pode ser designado para cache com cache_control. Isso inclui:- Ferramentas: Definições de ferramentas no array
tools - Mensagens de sistema: Blocos de conteúdo no array
system - Mensagens: Blocos de conteúdo no array
messages.content, tanto para turnos de usuário quanto de assistente - Imagens & Documentos: Blocos de conteúdo no array
messages.content, em turnos de usuário - Uso de ferramentas e resultados de ferramentas: Blocos de conteúdo no array
messages.content, em turnos de usuário e assistente
cache_control para habilitar o cache para aquela parte da requisição.
O que não pode ser cacheado
Embora a maioria dos blocos de requisição possa ser cacheada, existem algumas exceções:- Blocos de thinking não podem ser cacheados diretamente com
cache_control. Não entanto, blocos de thinking PODEM ser cacheados junto com outro conteúdo quando aparecem em turnos anteriores de assistente. Quando cacheados desta forma, eles CONTAM como tokens de entrada quando lidos do cache. - Sub-blocos de conteúdo (como citações) por si só não podem ser cacheados diretamente. Em vez disso, cacheie o bloco de nível superior.
- Blocos de texto vazios não podem ser cacheados.
Rastreando desempenho do cache
Monitore o desempenho do cache usando estes campos de resposta da API, dentro deusage na resposta (ou evento message_start se estiver usando streaming):
cache_creation_input_tokens: Número de tokens escritos no cache ao criar uma nova entrada.cache_read_input_tokens: Número de tokens recuperados do cache para esta requisição.input_tokens: Número de tokens de entrada que não foram lidos do cache nem usados para criar um cache.
Melhores práticas para cache eficaz
Para otimizar o desempenho do cache de prompt:- Cacheie conteúdo estável e reutilizável como instruções de sistema, informações de background, contextos grandes ou definições frequentes de ferramentas.
- Coloque o conteúdo cacheado no início do prompt para melhor desempenho.
- Use pontos de quebra de cache estrategicamente para separar diferentes seções de prefixo cacheáveis.
- Analise regularmente as taxas de acerto do cache e ajuste sua estratégia conforme necessário.
- Para conteúdo de longo prazo, considere usar cache de 1 hora para melhor eficiência de custo.
Otimizando para diferentes casos de uso
Adapte sua estratégia de cache de prompt ao seu cenário:- Agentes conversacionais: Reduza custo e latência para conversas estendidas, especialmente aquelas com instruções longas ou documentos enviados.
- Assistentes de codificação: Melhore o autocompletar e Q&A em codebase mantendo seções relevantes ou uma versão resumida do codebase no prompt.
- Processamento de documentos grandes: Incorpore material longo completo incluindo imagens em seu prompt sem aumentar a latência de resposta.
- Conjuntos de instruções detalhadas: Compartilhe listas extensivas de instruções, procedimentos e exemplos para ajustar finamente as respostas do Claude. Desenvolvedores frequentemente incluem um exemplo ou dois no prompt, mas com cache de prompt você pode obter desempenho ainda melhor incluindo 20+ exemplos diversificados de respostas de alta qualidade.
- Uso agêntico de ferramentas: Aumente o desempenho para cenários envolvendo múltiplas chamadas de ferramentas e mudanças iterativas de código, onde cada etapa tipicamente requer uma nova chamada de API.
- Converse com livros, papers, documentação, transcrições de podcasts e outros conteúdos longos: Dê vida a qualquer base de conhecimento incorporando o(s) documento(s) inteiro(s) no prompt e deixando os usuários fazerem perguntas.
Solucionando problemas comuns
Se experimentar comportamento inesperado:- Garanta que seções cacheadas sejam idênticas e marcadas com cache_control nos mesmos locais em todas as chamadas
- Verifique se as chamadas são feitas dentro da vida útil do cache (5 minutos ou 1 hora)
- Verifique que
tool_choicee uso de imagem permanecem consistentes entre chamadas - Valide que está cacheando pelo menos o número mínimo de tokens
- Embora o sistema tente usar conteúdo previamente cacheado em posições anteriores a um ponto de quebra de cache, você pode usar um parâmetro
cache_controladicional para garantir a busca no cache em porções anteriores do prompt, o que pode ser útil para consultas com listas muito longas de blocos de conteúdo
Armazenamento e compartilhamento de cache
- Isolamento da Organização: Os caches são isolados entre organizações. Organizações diferentes nunca compartilham caches, mesmo se usarem prompts idênticos.
- Correspondência Exata: Acertos de cache requerem segmentos de prompt 100% idênticos, incluindo todo texto e imagens até e incluindo o bloco marcado com cache_control. O mesmo bloco deve ser marcado com cache_control durante as leituras e criação do cache.
- Geração de Tokens de Saída: O cache de prompt não tem efeito na geração de tokens de saída. A resposta que você recebe será idêntica ao que você obteria se o cache de prompt não fosse usado.
Habilitando o cache do Claude em clientes / plataformas
Muitos clientes não têm na interface um lugar para preencher diretamente ocache_control; em vez disso, eles usam seu próprio “açúcar sintático” ou interruptores para injetá-lo por você. A regra subjacente é exatamente a mesma da seção acima — o prefixo cacheado deve ser idêntico, caractere por caractere, a cada turno, e o conteúdo que muda deve ficar depois do ponto de quebra de cache, caso contrário você cairá no “só escrever, nunca ler” (veja “Erro comum” acima).
Dify (via plugin Aihubmix)
O plugin Dify da Aihubmix herda o açúcar sintático do plugin oficial da Anthropic, e é habilitado em dois passos:- Envolva o prompt a ser cacheado (prompt de sistema fixo / contexto longo) com
<cache>…</cache>; o plugin converte automaticamente esse ponto em um ponto de quebracache_control; - Nos parâmetros do modelo, defina o “limite de cache automático para mensagens grandes” como um inteiro positivo: o cache só é realmente escrito quando o conteúdo atinge esse limite de tokens (ainda sujeito à restrição de cache mínimo da seção “Limitações do cache” abaixo: 4096 tokens para Opus 4.5/4.6, Haiku 4.5); definir 0 ou deixar em branco desativa.
Cherry Studio
Ao chamar o Claude via Aihubmix, o Cherry Studio não habilita o cache por padrão (o “Cache Token Threshold” é0 por padrão); é preciso ativá-lo nas “API Settings” do provedor.
- Clique na engrenagem à direita do nome do provedor Aihubmix para abrir as “API Settings”:
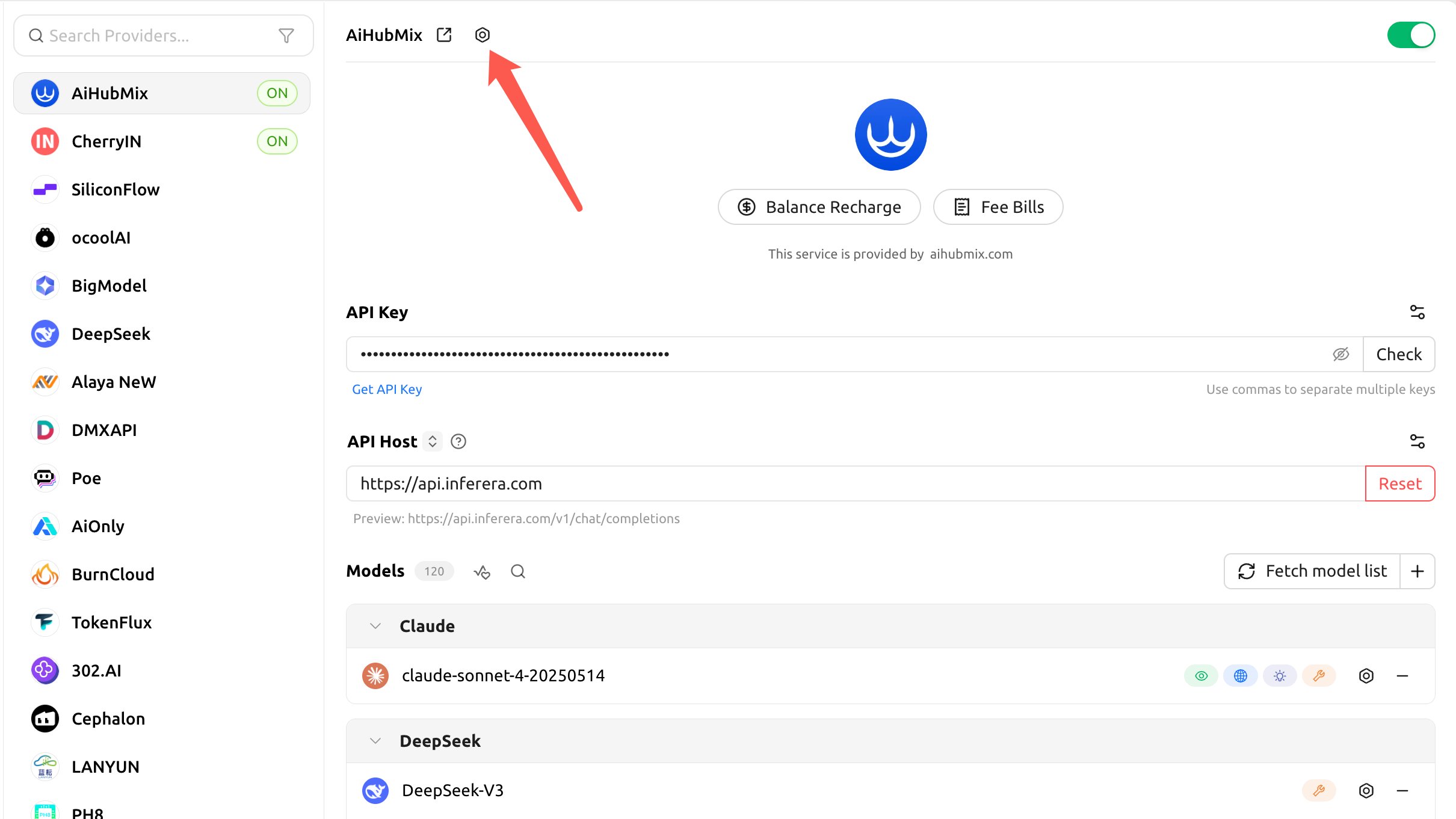
- Configure os três itens a seguir, e o cliente injetará automaticamente o
cache_controlpara o Claude com base neles:
- Cache Token Threshold: o ponto de quebra de cache só é injetado quando o conteúdo ultrapassa esse número de tokens (defina um número positivo para ativar, 0 ou em branco para desativar);
- Cache System Message: quando ativado, marca um ponto de quebra de cache na mensagem
system(adequado para cachear um prompt de sistema longo e fixo); - Cache Last N Messages: marca um ponto de quebra de cache nas N mensagens mais recentes (adequado para cache rolante em conversas de múltiplos turnos).
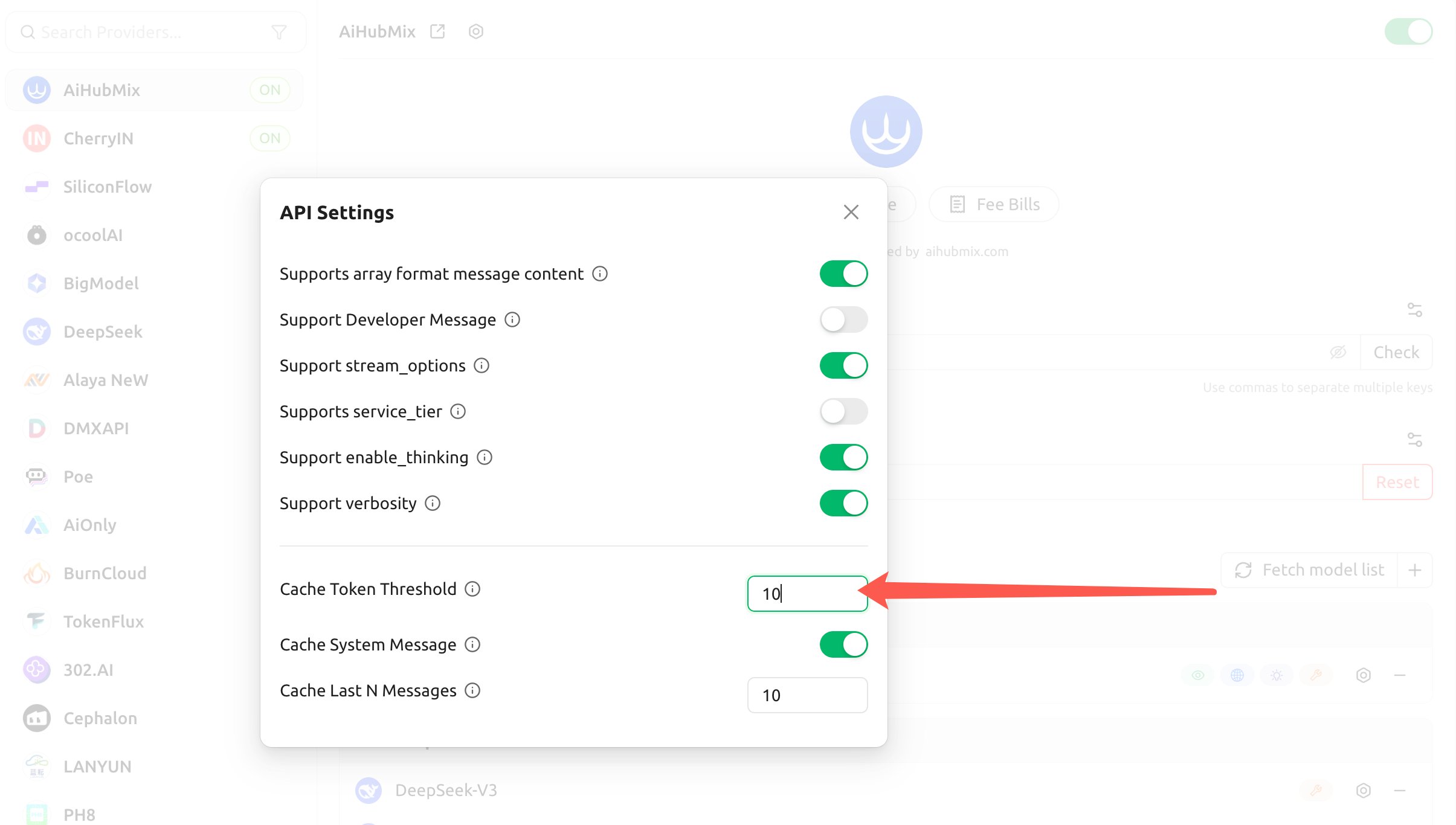
Os limites acima determinam apenas “quando o cliente injeta o ponto de quebra”, e não alteram o requisito mínimo de cache da Anthropic: a escrita real ainda exige que o conteúdo cacheado atinja o token mínimo de cache (4096 para Opus 4.5/4.6, Haiku 4.5). Se você colocar conteúdo que muda a cada turno (como instruções rotativas) dentro do prompt de sistema cacheado, também cairá no “só escrever, nunca ler”.
Perguntas Frequentes (FAQ)
Por que o cache é escrito (cache_creation_input_tokens alto) mas nunca lido (cache_read_input_tokens igual a 0)?
Porque o conteúdo anterior ao ponto de quebra de cache (cache_control) mudou entre duas requisições. Um acerto exige que o ponto de quebra e todo o conteúdo anterior a ele sejam idênticos byte a byte; assim que você coloca conteúdo que muda a cada turno antes do ponto de quebra, todo o cache do prefixo é invalidado e reescrito a cada turno. Basta colocar o conteúdo fixo no início e o conteúdo variável depois do ponto de quebra. Veja “Erro comum” acima.
Quantos tokens no mínimo o cache precisa?
Conteúdo abaixo do comprimento mínimo de cache não é cacheado, mesmo marcado comcache_control. Claude Opus 4.5/4.6, Haiku 4.5: 4096 tokens; os demais modelos Claude geralmente são 1024 tokens, e Haiku 3/3.5 são 2048 tokens. Veja “Limitações do cache” acima.
Quanto tempo dura o cache? Dá para mudar para 1 hora?
Por padrão, 5 minutos, atualizado sem custo a cada acerto. Para uma duração maior, defina"ttl": "1h" em cache_control; nenhum cabeçalho adicional é necessário. A escrita de cache na faixa de 1 hora é cobrada a 2 vezes o preço base de entrada. Veja “Duração de cache de 1 hora” acima.
Como habilitar o cache no Dify / Cherry Studio?
Esses clientes não preenchem ocache_control diretamente: o Dify usa <cache>…</cache> para envolver o conteúdo a ser cacheado e define o “limite de cache automático para mensagens grandes”; o Cherry Studio define “Cache Token Threshold / Cache System Message / Cache Last N Messages” nas “API Settings”. Veja “Habilitando o cache do Claude em clientes / plataformas” acima.
Suporte em Diferentes Modelos
- O suporte ao Cache de Prompt depende do próprio modelo.
- Se o modelo inerentemente suporta cache sem exigir declarações explícitas de parâmetros, pode ser suportado através de encaminhamento compatível com OpenAI.
- A OpenAI suporta Cache de Prompt por padrão, com ativação automática (prefixo ≥1024 tokens). Nos modelos anteriores ao GPT-5.6, a escrita de cache não tem cobrança adicional e o cache é limpo automaticamente após 5-10 minutos de inatividade; no GPT-5.6 e posteriores, a escrita de cache é cobrada a 1,25 vezes o preço de entrada, a leitura a 0,1 vez, o cache é mantido por no mínimo 30 minutos e há suporte a pontos de quebra de cache explícitos. Detalhes em Cache de Prompt do GPT.
- O Claude requer a declaração nativa
cache_control: { type: "ephemeral" }. A taxa de cache é 1,25 vezes o custo padrão de entrada (5 minutos) ou 2 vezes (1 hora), a recuperação de tokens cacheados custa 0,1 vez a taxa normal, com ciclo de vida de 5 minutos ou 1 hora. Detalhes - Deepseek V3 e R1 suportam cache nativamente. A taxa de cache é igual ao custo padrão de entrada, a recuperação de tokens cacheados custa 0,1 vez a taxa normal. Detalhes
- Suporte a cache implícito do Gemini:
- Cache Implícito: Habilitado por padrão para todos os modelos Gemini 2.5. Se sua requisição acertar o cache, as economias de custo são aplicadas automaticamente. Esse recurso é efetivo a partir de 8 de maio de 2025. A contagem mínima de tokens de entrada para cache de contexto é 1.024 para Gemini 2.5 Flash e 2.048 para Gemini 2.5 Pro.
- Dicas para melhorar a taxa de acerto do cache implícito:
- Tente colocar conteúdo grande e frequentemente reutilizado no início do prompt.
- Tente enviar requisições com prefixos similares dentro de uma janela curta de tempo.
- Você pode visualizar o número de tokens com acerto de cache no campo
usage_metadatado objeto de resposta. - As economias de custo são calculadas com base nos acertos do cache de prefill. Apenas o cache de prefill e o cache de pré-processamento de vídeos do YouTube são elegíveis para cache implícito.
Última atualização: 2026-07-10