Ne laissez pas une panne amont devenir votre panne.AIHubMix propose deux capacités au niveau de la Key. Configurez-les une seule fois dans la console et elles s’appliquent sans aucune modification du code client :
- Le Mappage de modèle est la capacité de la couche Gateway qui réécrit l’alias de modèle d’une requête client vers le véritable modèle amont.
- Le Fallback en cas d’erreur est la capacité par laquelle, lorsque l’appel du modèle principal échoue, la Gateway essaie automatiquement les modèles de secours dans un ordre de priorité préconfiguré, de façon transparente pour le client.
AIHubMix permet de configurer le mappage de noms de modèles et le Fallback en cas d’erreur au niveau de la Key, et facture selon le modèle qui répond réellement. Les deux se configurent par API Key sur la page de gestion des Keys AIHubMix.
Model name mapping et Fallback models on error du panneau :
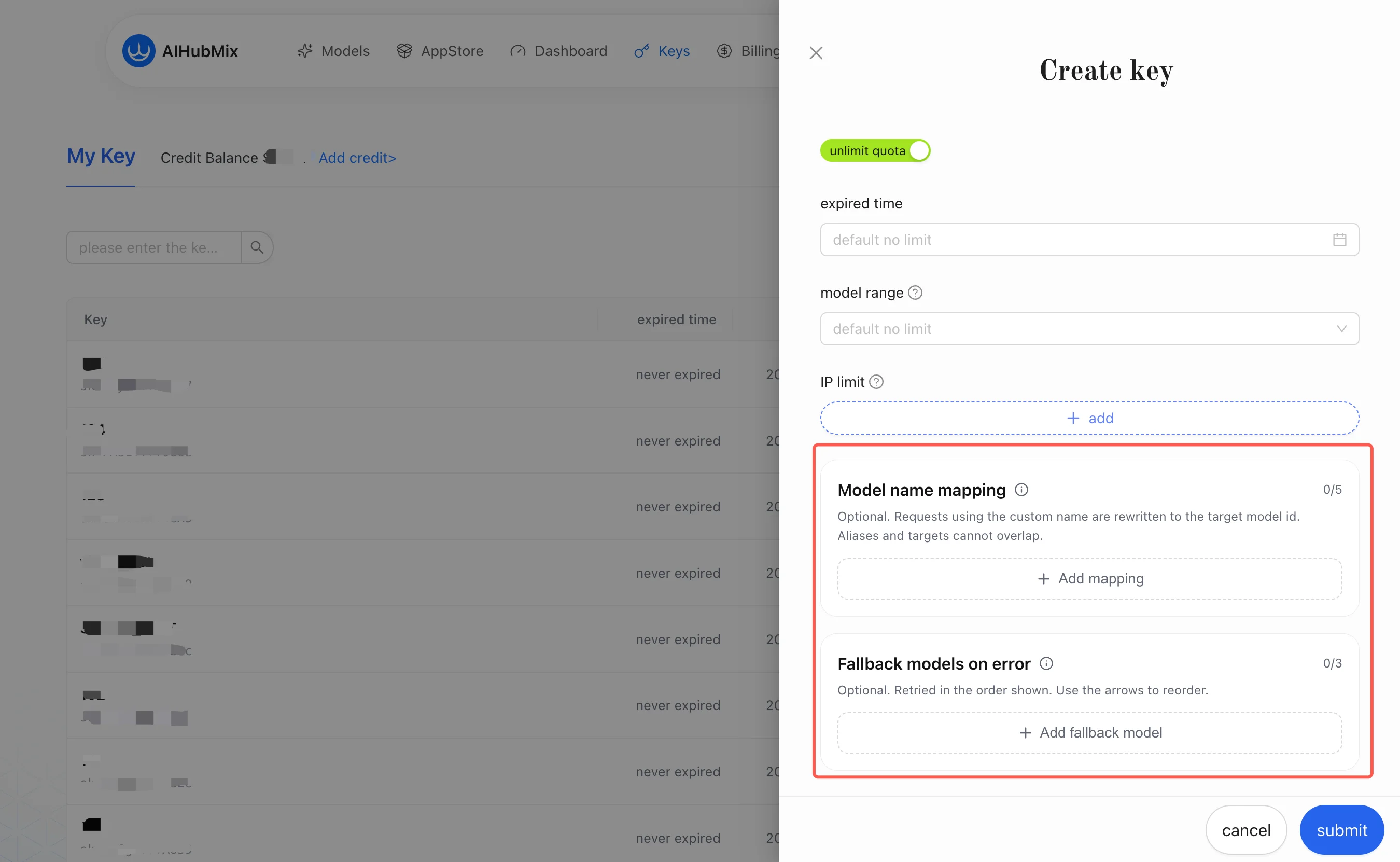
1. Mappage de noms de modèles
Le mappage de noms de modèles gère la divergence entre « le nom de modèle que voit le client » et « le modèle qu’AIHubMix appelle réellement ». Il s’agit d’une réécriture d’alias par key : il réécrit l’alias de la requête vers le modèle cible que vous avez configuré sur la Key.Une fois un canal sélectionné pour le modèle cible, la plateforme effectue en interne un autre mappage au niveau du canal vers le véritable modèle amont. Cette couche est transparente pour vous et ne nécessite aucune configuration. Vous n’avez à vous soucier que de la couche « alias → modèle cible ».Exemple :
Tous les noms de modèles du tableau ci-dessus peuvent être recherchés sur la page des modèles AIHubMix.Usages courants :
- Le client restreint le format du nom de modèle. Par exemple, Claude Desktop exige des noms de modèles au style Claude (voir la Section 5).
- Définir un alias plus court et plus stable pour un Model ID complexe.
- Garder la configuration du client inchangée tout en changeant le véritable modèle dans le backend AIHubMix.
- Plusieurs plateformes partagent une même convention de nommage de connexion mais routent vers des modèles différents selon la Key.
Correspondance caractère par caractère : le nom de modèle envoyé par le client doit correspondre au côté gauche du mappage caractère par caractère. Par exemple,my-gpt-5.5etmy-gpt-5-5sont deux chaînes différentes ; si elles ne correspondent pas, le mappage ne sera pas déclenché.
2. Fallback en cas d’erreur
Le Fallback en cas d’erreur essaie les modèles de secours dans l’ordre lorsque le modèle principal échoue. Ce n’est pas une nouvelle tentative côté client ; c’est un changement de modèle effectué côté Gateway AIHubMix sous la même configuration de Key. L’intégrateur n’a besoin de transmettre aucun paramètre de routage supplémentaire à chaque requête. Vous pouvez considérer le Fallback comme un « mappage vers une liste ordonnée » : après l’échec du modèle principal, la Gateway descend automatiquement la liste vers le modèle de secours suivant. Exemple (configuré sur la même Key) :2.1 Conditions de déclenchement
Le Fallback ne se produit que lorsque toutes les conditions suivantes sont réunies :- La Key est configurée avec une liste de modèles de secours non vide.
- Chaque canal du modèle principal a été essayé et tous ont échoué avec une « erreur réessayable » (canaux épuisés).
- La réponse n’a pas encore commencé à être renvoyée (le premier octet / en-tête n’a pas été envoyé au client).
- L’erreur n’est pas une erreur au niveau de la Key / de l’utilisateur (voir le tableau comparatif 2.2 ci-dessous).
2.2 Ce qui déclenche un Fallback et ce qui n’en déclenche pas
Remarque : « Key invalide » signifie ici que votre propre Key AIHubMix est invalide, ce qui ne déclenche pas de Fallback. Si la key d’un canal amont est défectueuse, la Gateway change de canal, et une fois les canaux épuisés elle peut quand même déclencher un Fallback. Ne confondez pas les deux.
2.3 Base de facturation
Facturé selon le modèle qui répond réellement. Si le modèle de Fallback finit par répondre, la facturation, les capacités et les limites de contexte sont toutes basées sur le modèle qui répond réellement. Ce modèle est aussi reflété dans l’en-tête de réponse (voir la Section 4).2.4 Règle des modèles gratuits
Un modèle gratuit ne peut pas être utilisé comme option de Fallback — un modèle gratuit ne peut être que le modèle principal. Le placer dans la liste de secours fait qu’il est silencieusement ignoré et la Gateway continue à l’entrée suivante. Ne mettez donc pas de modèles gratuits dans la liste de Fallback.Usage typique : définissez un modèle gratuit comme modèle principal et placez des modèles payants dans la liste de secours. Lorsque le modèle principal gratuit atteint un quota / une limite de débit, il bascule automatiquement vers un modèle de secours payant. Normalement, vous économisez en utilisant le quota gratuit, et après limitation de débit vous passez de façon transparente à un modèle payant pour garantir la disponibilité. C’est l’un des usages les plus courants du Fallback.
3. AIHubMix vs OpenRouter / LiteLLM
Le mappage de modèle et le Fallback ne sont pas des concepts nouveaux ; OpenRouter, LiteLLM et d’autres offrent des capacités similaires. Ce qui distingue AIHubMix, c’est le coût de configuration le plus faible :
En une phrase : aucune Gateway maison, pas une seule ligne de code client modifiée — configurez une fois sur la Key et c’est effectif.
4. Configuration et vérification
4.1 Configuration
- Configurez le mappage d’alias sur la Key : l’alias à gauche doit correspondre caractère par caractère au nom de modèle effectivement envoyé par le client.
- Configurez la liste des modèles de secours (une liste de priorité ordonnée) sur la même Key.
- La liste de secours ne doit contenir que des modèles payants / disponibles, pas des modèles gratuits (ils seront ignorés).
- Les modèles de la liste de secours doivent faire partie de la plage des modèles disponibles de la Key (les modèles hors plage seront ignorés).
4.2 Vérification — examinez d’abord les en-têtes de réponse, pas les journaux
Lors d’un dépannage, ne regardez pas seulement quel modèle le client a sélectionné. La méthode la plus fiable et la plus automatisable consiste à lire les en-têtes de réponse :X-Aihubmix-Fallback: true: un Fallback s’est produit sur cette requête (ajouté lorsque le modèle final ≠ le modèle principal).X-Aihubmix-Model: le modèle qui a réellement répondu à cette requête et qui a été facturé en conséquence.
5. Scénario un Claude Desktop
Claude Desktop se connecte à AIHubMix viaGateway, un scénario typique de mappage de noms de modèles.
Cette section suppose que vous avez déjà terminé l’intégration de base de Claude Desktop. Pour les étapes d’intégration complètes (téléchargement et installation, mode développeur, configuration de la Gateway, schéma d’authentification, etc.), voir Connecter AIHubMix dans Claude Desktop. Cette section ne couvre que la configuration supplémentaire pour le mappage et le Fallback.
5.1 Pourquoi le mappage est nécessaire
Claude Desktop se connecte viaGateway (compatible Anthropic), et le client contraint les noms de modèles au style Claude, donc les noms de modèles doivent utiliser le préfixe claude-.
Cela crée un conflit : côté client, on ne peut écrire que des noms au style claude-, mais ce que vous voulez réellement appeler, c’est gpt-5.5, gemini-3.1-pro-preview, et autres. Le mappage de noms de modèles est fait exactement pour cela — le client écrit l’alias claude-g-p-t-5.5, et AIHubMix le mappe vers le véritable gpt-5.5.
Claude Desktop utilise l’interface native Claude /v1/messages, donc dans les exemples de cet article le mappage et le Fallback s’appliquent tous les deux.
5.2 Configuration du mappage et du Fallback AIHubMix
Exemple de configuration :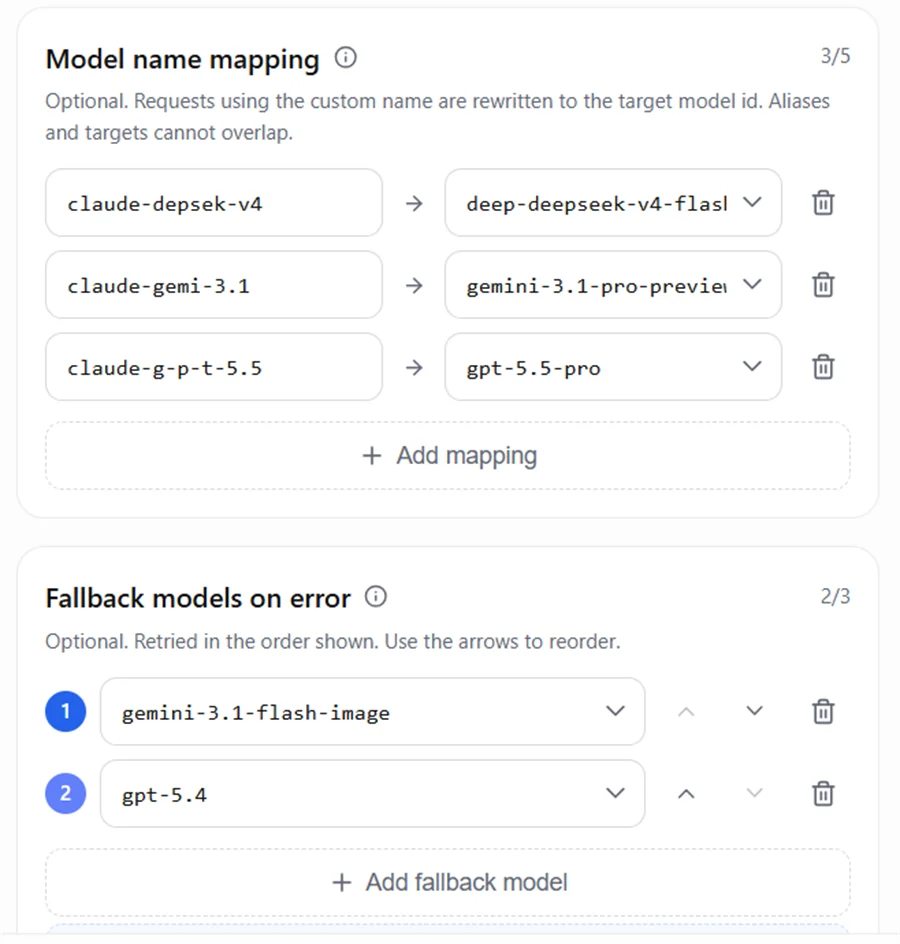
5.3 Liste de modèles de Claude Desktop
Ce que vous configurez dans laModel list de Claude Desktop est l’alias avant mappage — c’est-à-dire le nom de modèle que Claude Desktop envoie à AIHubMix, et non le véritable nom du modèle amont.
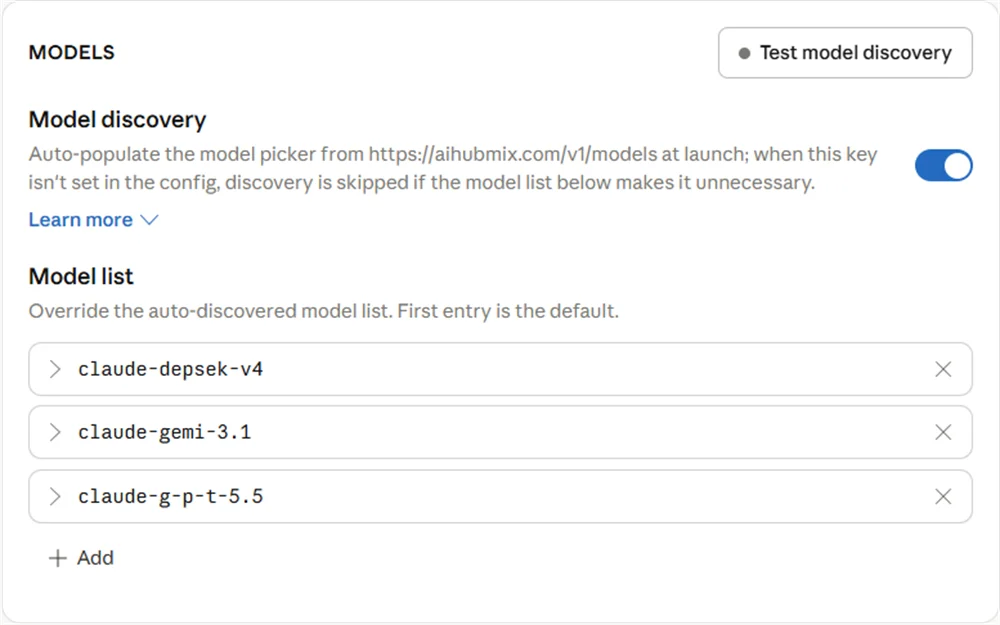
- Utilisez le préfixe
claude-pour leModel ID. - N’écrivez pas directement de vrais noms de familles de modèles comme
gpt,geminioudeepseek; utilisez des alias tels queg-p-t,gemi,depsek. - Le
Model IDdoit correspondre au côté gauche du mappage AIHubMix caractère par caractère, sinon la requête ne déclenchera pas le mappage attendu et pourra continuer jusqu’au modèle de Fallback en cas d’erreur.
6. Scénario deux Fallback de capacité multimodale
Le Fallback de capacité multimodale gère le scénario où « le modèle principal peut répondre à du texte mais ne prend pas en charge le type d’entrée actuel ». Par exemple, le client envoie une image ou une vidéo alors que le modèle principal n’a qu’une capacité d’entrée texte ; AIHubMix peut continuer à essayer les modèles de la liste de Fallback qui prennent en charge la modalité correspondante. Voici un parcours de test réel. La configuration de mappage et de Fallback de cette Key est la suivante (voir la capture d’écran ci-dessous). Le point essentiel est que la liste de Fallback contient à la fois un modèle texte et un modèle qui prend en charge la compréhension d’image :claude-g-l-m-4.6 — un modèle qui ne prend en charge que l’entrée texte. L’utilisateur a téléversé une capture d’écran de la page de la liste des modèles AIHubMix et a demandé « à quoi sert ce site ». Comme la requête contenait une image, le modèle texte ne pouvait pas traiter directement l’entrée, ce qui a déclenché le Fallback.
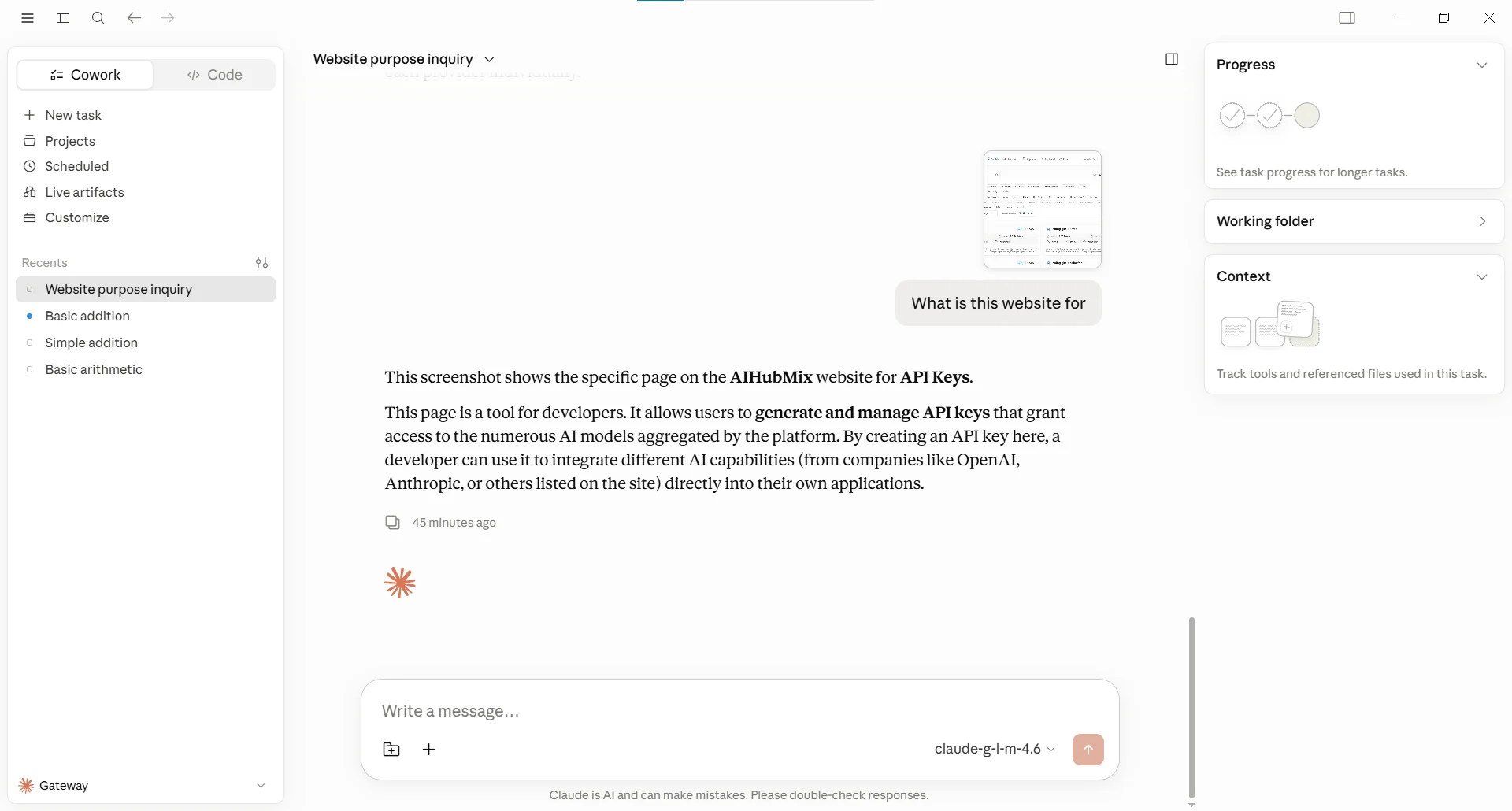
Google AI Studio/gemini-3.1-flash-image, la 2e entrée de la liste de Fallback. La 1re entrée, gpt-5.4, ne prend pas non plus en charge cette entrée image et a continué à renvoyer une erreur réessayable pour cette requête, donc la Gateway a continué et a abouti à gemini-3.1-flash-image, qui prend en charge la compréhension d’image.
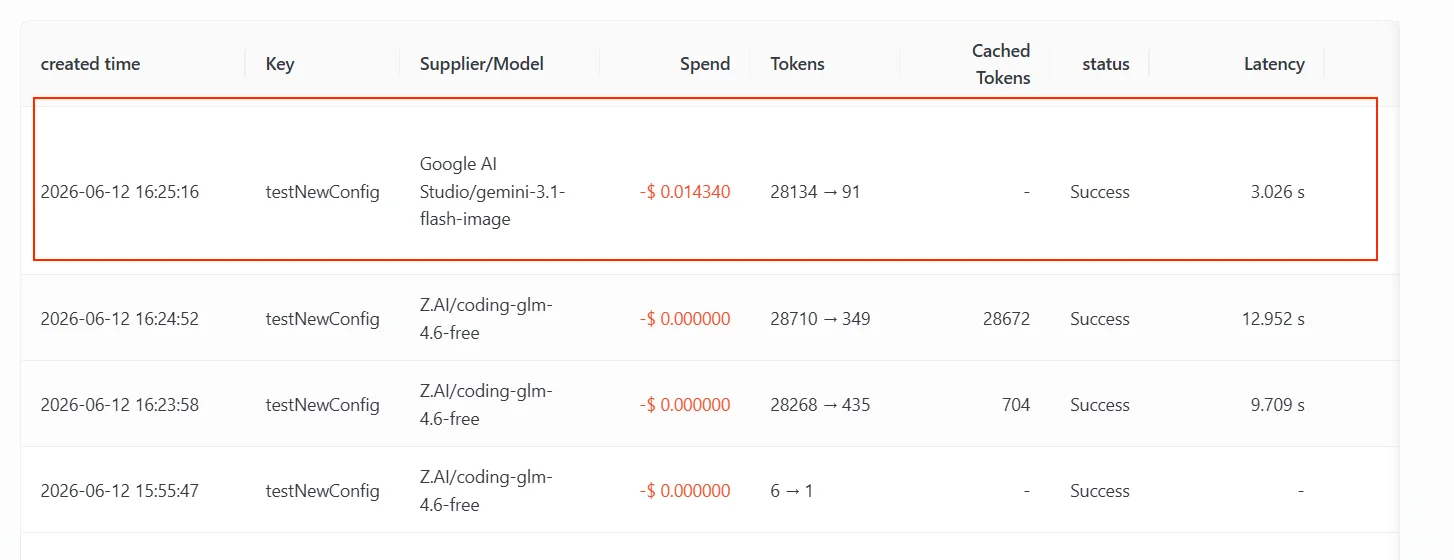
Soyez clair sur la raison du déclenchement : le Fallback ici se produit parce que l’amont a renvoyé une erreur réessayable pour cette entrée image et que les canaux du modèle principal étaient épuisés — c’est le même mécanisme de Fallback que « basculer après que le modèle principal est limité en débit », simplement déclenché par un type d’erreur différent (le premier est une entrée non prise en charge, le second un quota / une limite de débit).
Distinguez compréhension et génération : il s’agit ici du Fallback de compréhension d’image / de vidéo, et non de génération d’image ou de génération de vidéo. Une requête de chat ne se transforme pas automatiquement en un endpoint de génération ; pour tester le dessin ou la génération de vidéo, vous devez utiliser l’endpoint et le modèle de génération correspondants. Les capacités d’un modèle sont déterminées par les Input Modalities actuellement indiquées sur la page des modèles AIHubMix.
7. Scénario trois Fallback de modèle gratuit
C’est l’un des usages les plus courants du Fallback : définir un modèle gratuit comme modèle principal et placer des modèles payants dans la liste de secours. Normalement, toutes les requêtes passent par le modèle gratuit et économisent des coûts ; une fois que le modèle principal gratuit atteint un quota / une limite de débit, la Gateway bascule automatiquement vers un modèle de secours payant, garantissant que le service n’est pas interrompu. Exemple de configuration de Key :- Tant que le quota gratuit est encore suffisant, la requête est traitée par le modèle principal
coding-glm-5.2-freeet facturée comme gratuite. - Après que le modèle principal gratuit est limité en débit, il bascule automatiquement vers
gpt-5.4; sigpt-5.4est également indisponible, il essaie ensuitegemini-3.1-pro-preview. - Quel que soit le modèle qui répond finalement, c’est celui qui vous est facturé (voir 2.3).
Remarque : un modèle gratuit ne peut être que le modèle principal et ne peut pas être placé dans la liste de Fallback (si vous le faites, il sera ignoré ; voir 2.4). La bonne façon de réaliser un « Fallback de modèle gratuit » est donc : gratuit en principal, payant en secours, et non l’inverse.La vérification se fait à nouveau en lisant les en-têtes de réponse : lorsqu’un Fallback se produit,
X-Aihubmix-Fallback: true est renvoyé, et X-Aihubmix-Model indique le modèle qui répond réellement (voir la Section 4).
8. Endpoints pris en charge
Le mappage de modèle et le Fallback en cas d’erreur prennent actuellement en charge les catégories d’interfaces suivantes :
Points clés :
- Le mappage de modèle et le Fallback en cas d’erreur prennent en charge trois catégories d’interfaces : les interfaces compatibles OpenAI, la native Claude
/v1/messageset OpenAI Responses/v1/responses. - Les autres interfaces de passthrough natif (Gemini natif, Ideogram, vidéo, TTS, Stability, OCR, predictions, etc.), le passthrough de canal spécifique et les interfaces de récupération par ID de ressource / type de fichier ne sont pas encore pris en charge.
- Claude Desktop utilise la native Claude
/v1/messages, donc dans les exemples de cet article le mappage et le Fallback s’appliquent tous les deux.
9. FAQ
Q : Que dois-je faire si Claude Desktop affiche « model not found » ? R : Vérifiez si leModel ID dans Claude Desktop correspond au côté gauche du mappage AIHubMix caractère par caractère ; s’ils ne correspondent pas, le mappage ne sera pas déclenché.
Q : Le Fallback affecte-t-il la facturation ?
R : Facturé selon le modèle qui répond réellement. Quel que soit le modèle qui répond finalement, vous êtes facturé selon le prix, les capacités et les limites de contexte de ce modèle.
Q : Comment confirmer si cette requête a réellement utilisé le Fallback ?
R : Regardez les en-têtes de réponse X-Aihubmix-Fallback: true (un Fallback s’est produit) et X-Aihubmix-Model (le modèle qui répond réellement) ; voir la Section 4.
Q : Quelles erreurs déclenchent un Fallback et lesquelles non ?
R : Voir le tableau comparatif 2.2. En bref : le Fallback ne se produit que sur un échec amont réessayable, des canaux épuisés et une réponse pas encore commencée ; un canal spécifique, une réponse déjà commencée, une déconnexion / un délai d’attente client, et les erreurs au niveau de la Key / de l’utilisateur ne déclenchent pas de Fallback.
Q : Un modèle gratuit peut-il être placé dans la liste de Fallback ?
R : Non, il sera ignoré. Un modèle gratuit ne peut être que le modèle principal.
Q : En quoi est-ce différent de l’alias de modèle / Fallback d’OpenRouter / LiteLLM ?
R : AIHubMix est au niveau de la Key et géré par la plateforme — configurez-le une fois dans la console et c’est effectif, sans modification du code client et sans Gateway maison. Voir la Section 3 pour les détails.
Ressources associées
- Connecter AIHubMix dans Claude Desktop : étapes complètes pour le mode développeur, la configuration de la Gateway, le schéma d’authentification, et plus.
- Page des modèles AIHubMix : recherchez les noms de modèles, les prix et les
Input Modalities. - Connecter AIHubMix dans LiteLLM : une référence lorsque vous avez besoin d’une Gateway maison + mappage de modèle / Fallback.