Installation en un clic du plugin Aihubmix
Cliquez simplement sur le lien ci-dessous et appuyez sur le bouton Install sur la page du Marketplace Dify : 👉 Accéder à la page du plugin Dify Image d’exemple :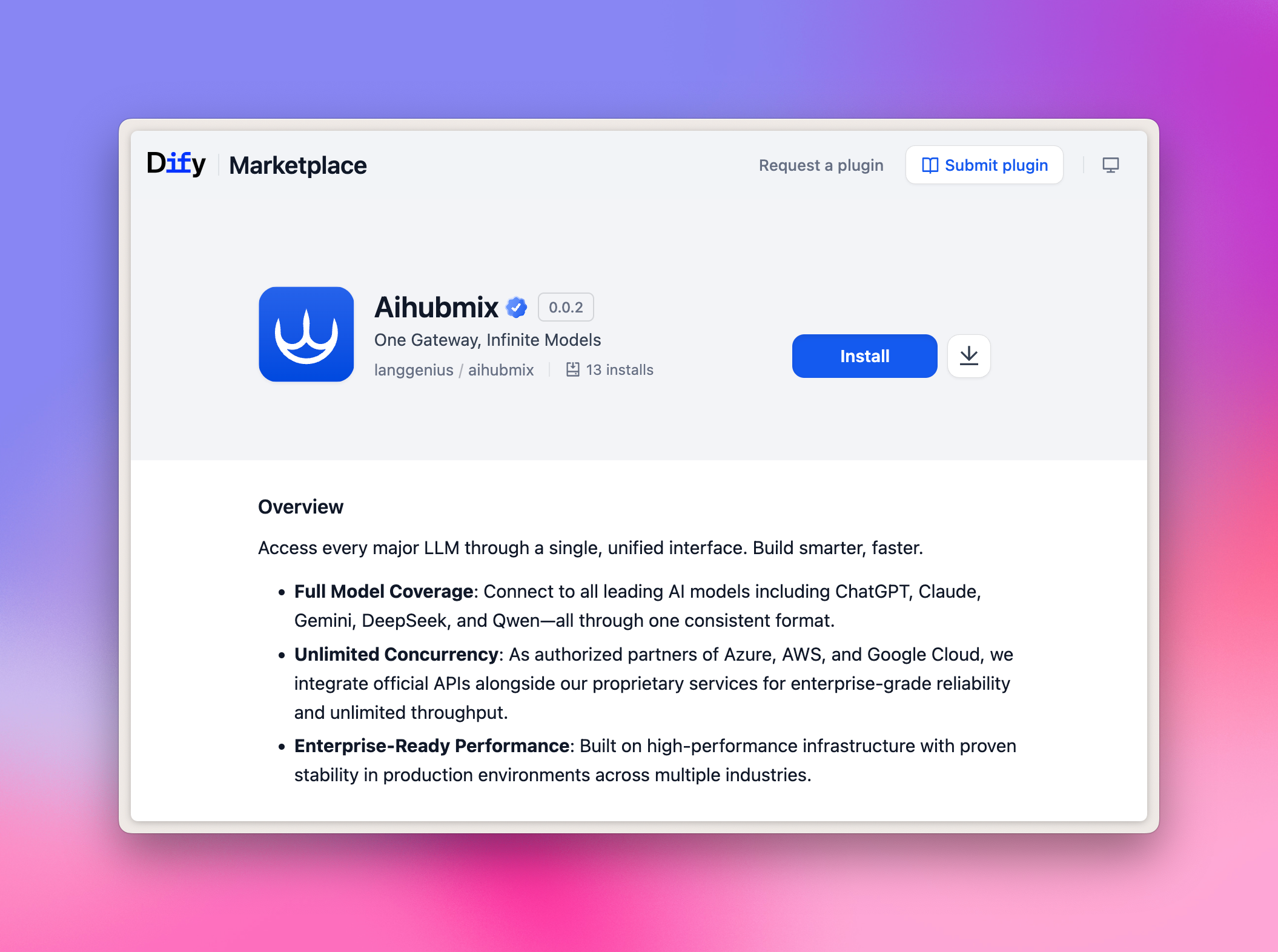
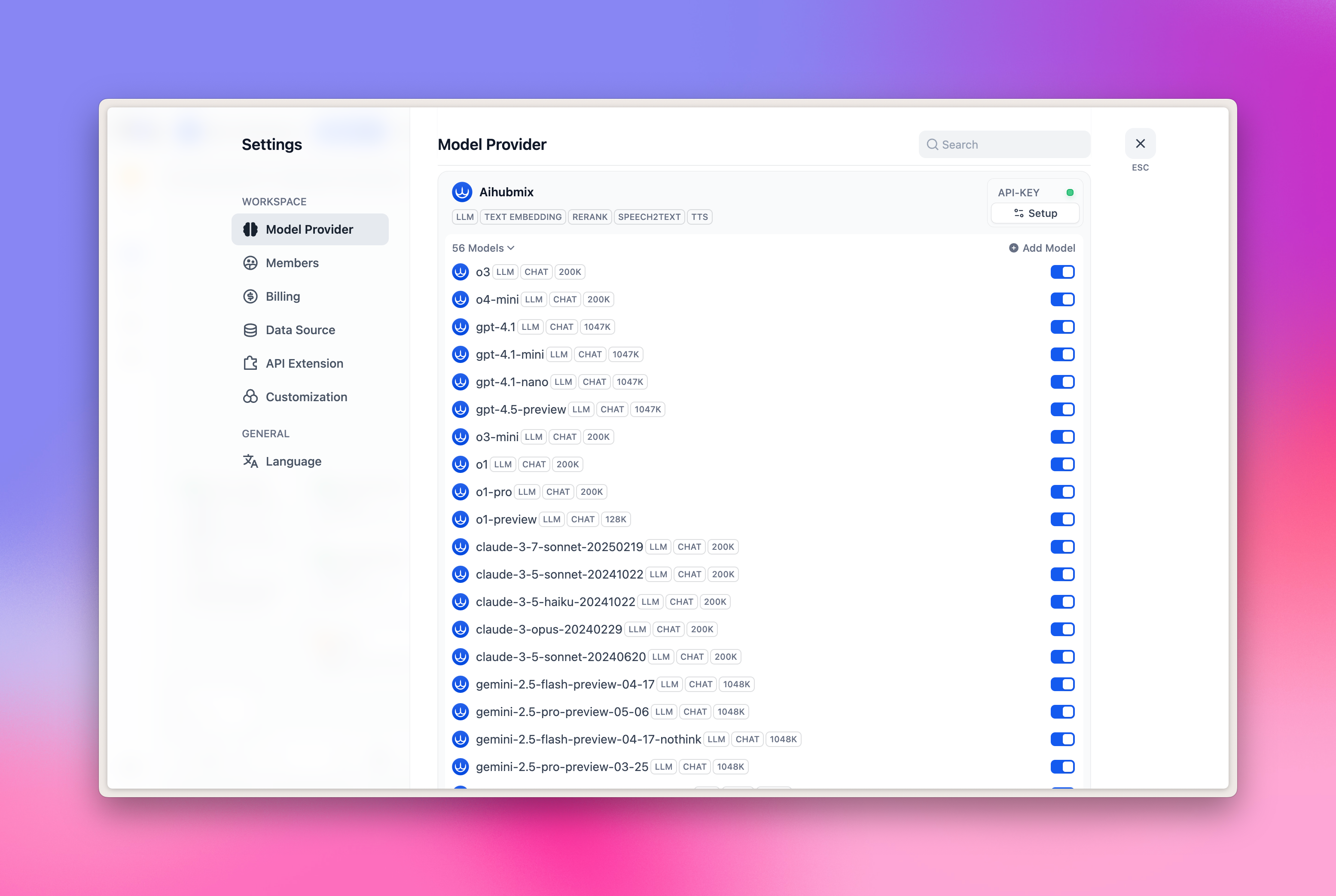
Configuration
- Cliquez sur l’avatar en haut à droite de la page → Sélectionnez « Settings »
- Cliquez sur l’onglet « Model Provider »
- Trouvez Aihubmix dans la partie droite → Développez Setup et renseignez votre clé API
 Actuellement, les 5 catégories de modèles suivantes sont préconfigurées :
Actuellement, les 5 catégories de modèles suivantes sont préconfigurées :
- LLM : grand modèle de langage
- TEXT EMBEDDING : modèle d’embedding vectoriel
- RERANK : modèle de reranking
- SPEECH2TEXT : modèle de reconnaissance vocale
- TTS : modèle de synthèse vocale
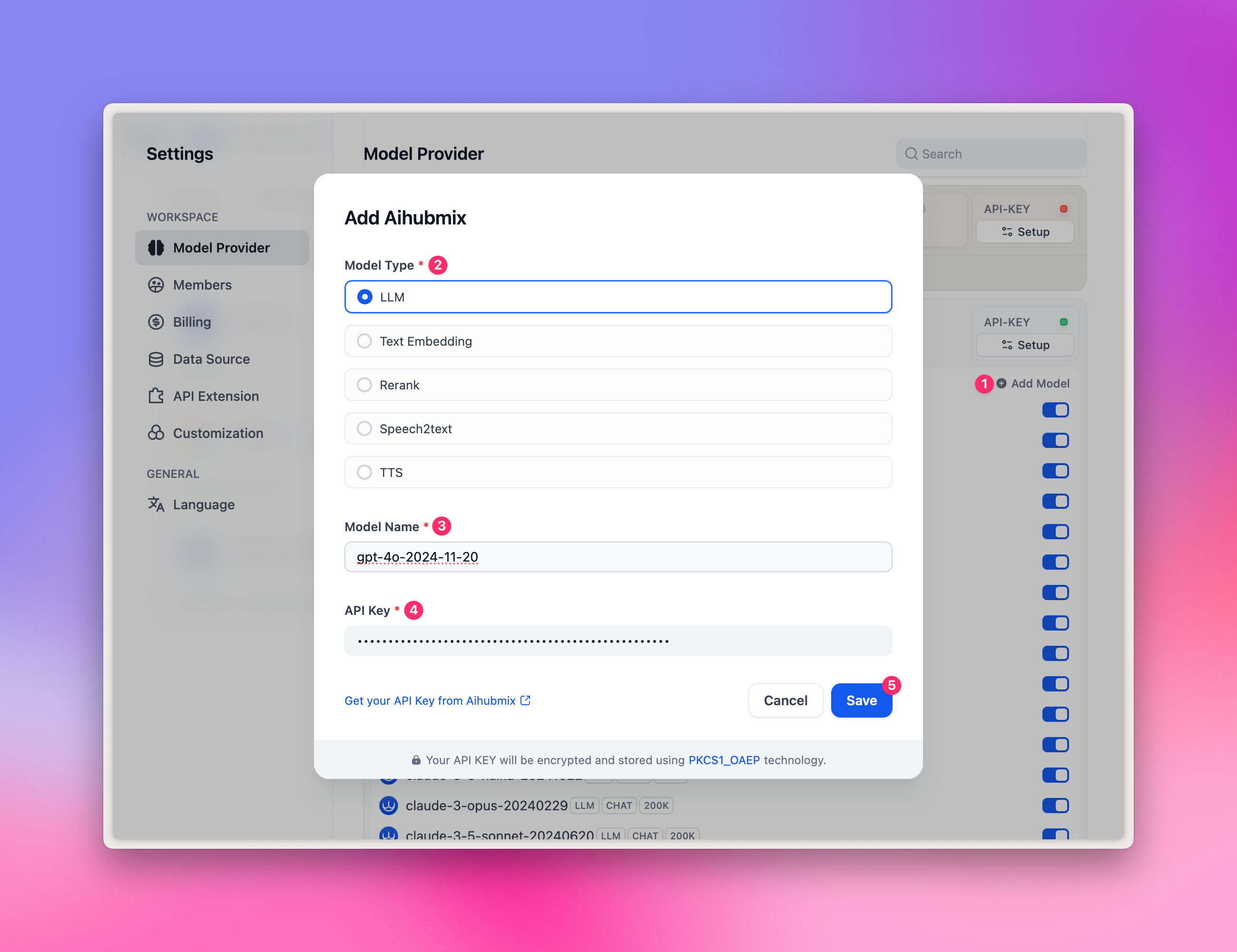
- Renseignez n’importe quel ID de modèle de la galerie de modèles, par exemple
gpt-4o-2024-11-20. - Saisissez votre clé API et cliquez sur « Save ».
gpt-image-1 ne peuvent pas être ajoutés.
Sélection de LLM
Dans le nœud Workflow, sélectionnez « LLM » et vous pouvez choisir les modèles fournis par Aihubmix. Image d’exemple :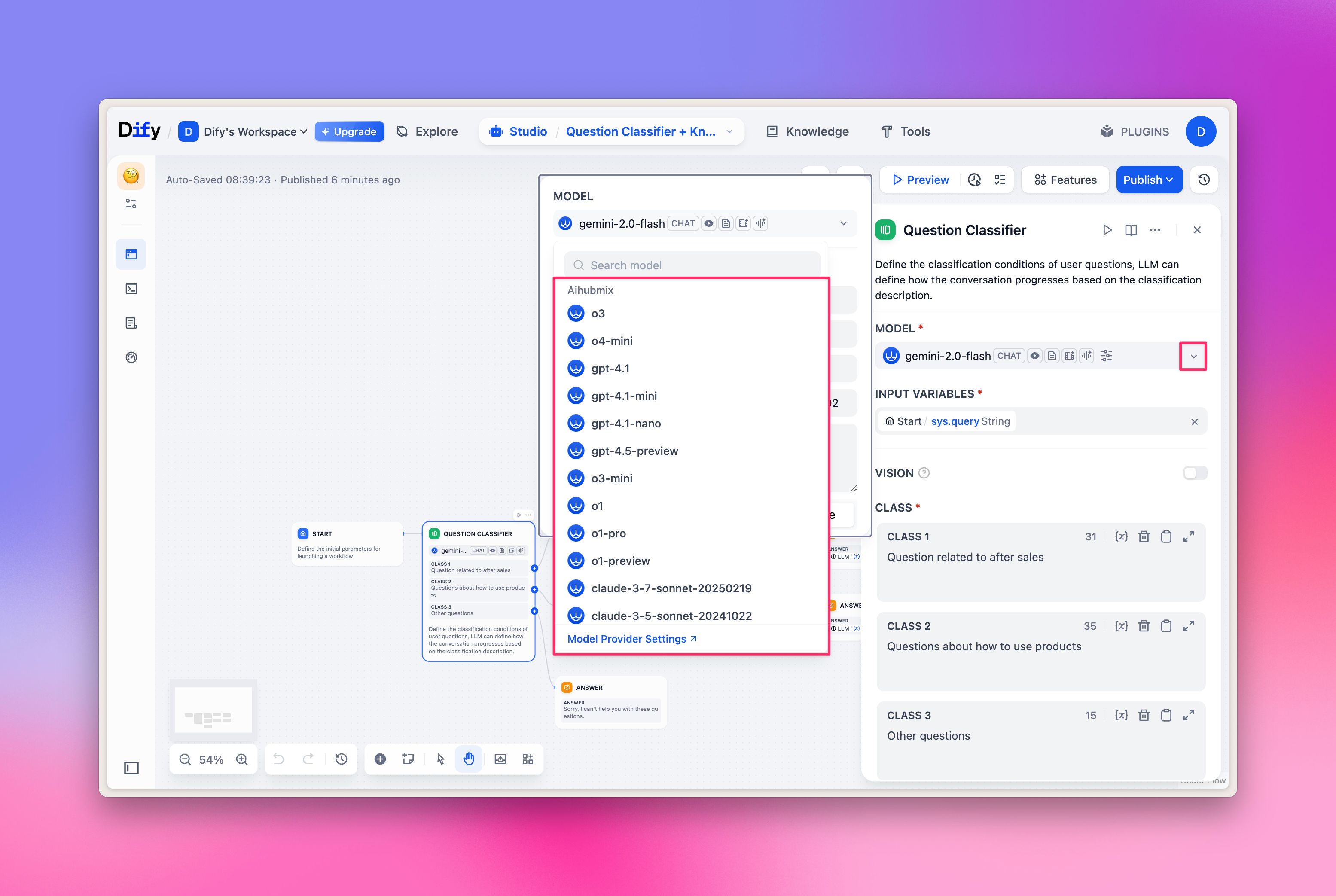
Sélection de modèles Embeddings/Reranker
Les modèles Embeddings/Reranker sont principalement utilisés pour les questions-réponses sur base de connaissances. Vous pouvez les essayer rapidement dans l’onglet Knowledge en haut, et également sélectionner le modèle correspondant dans le nœud Workflow. Image d’exemple :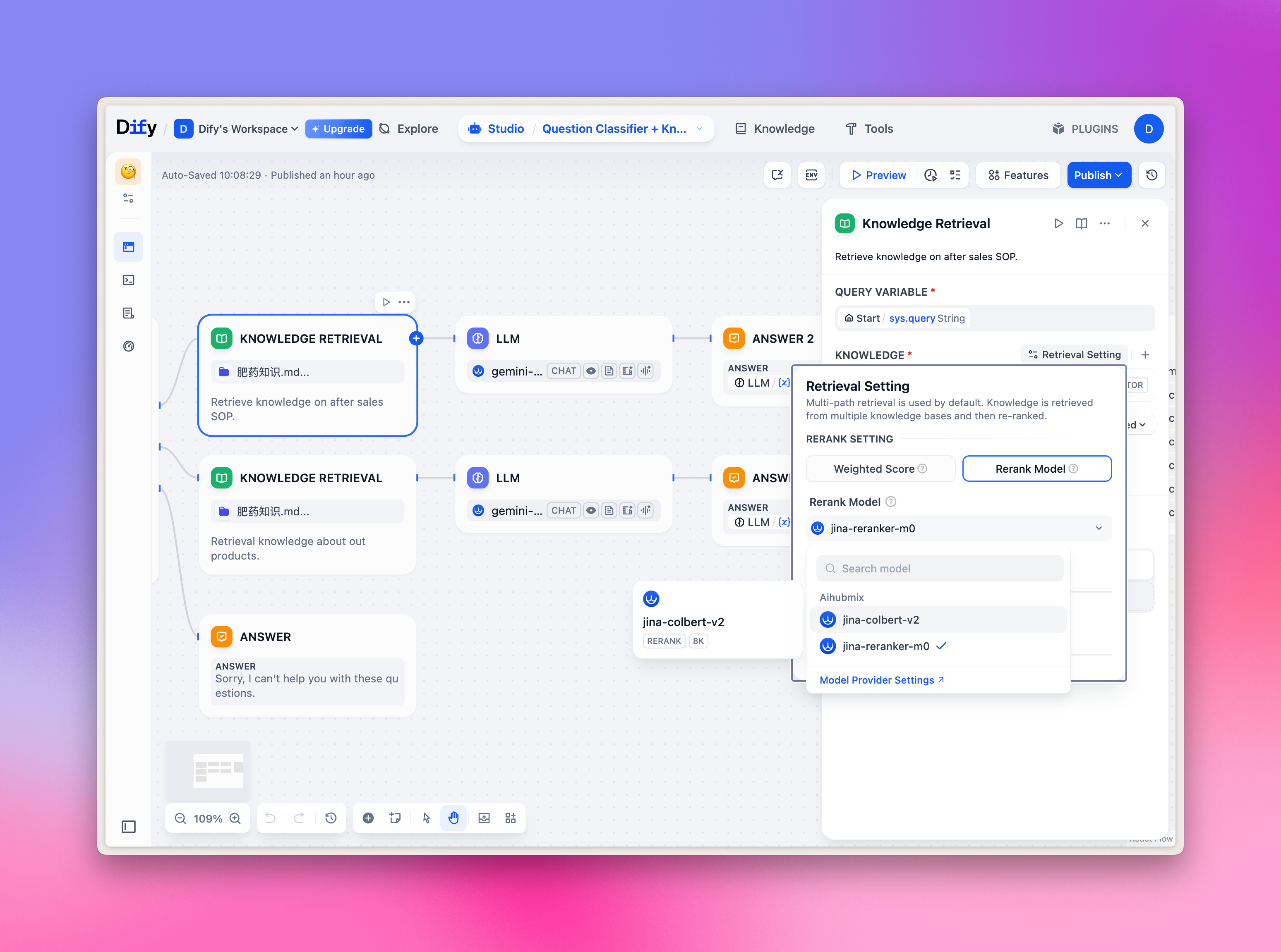
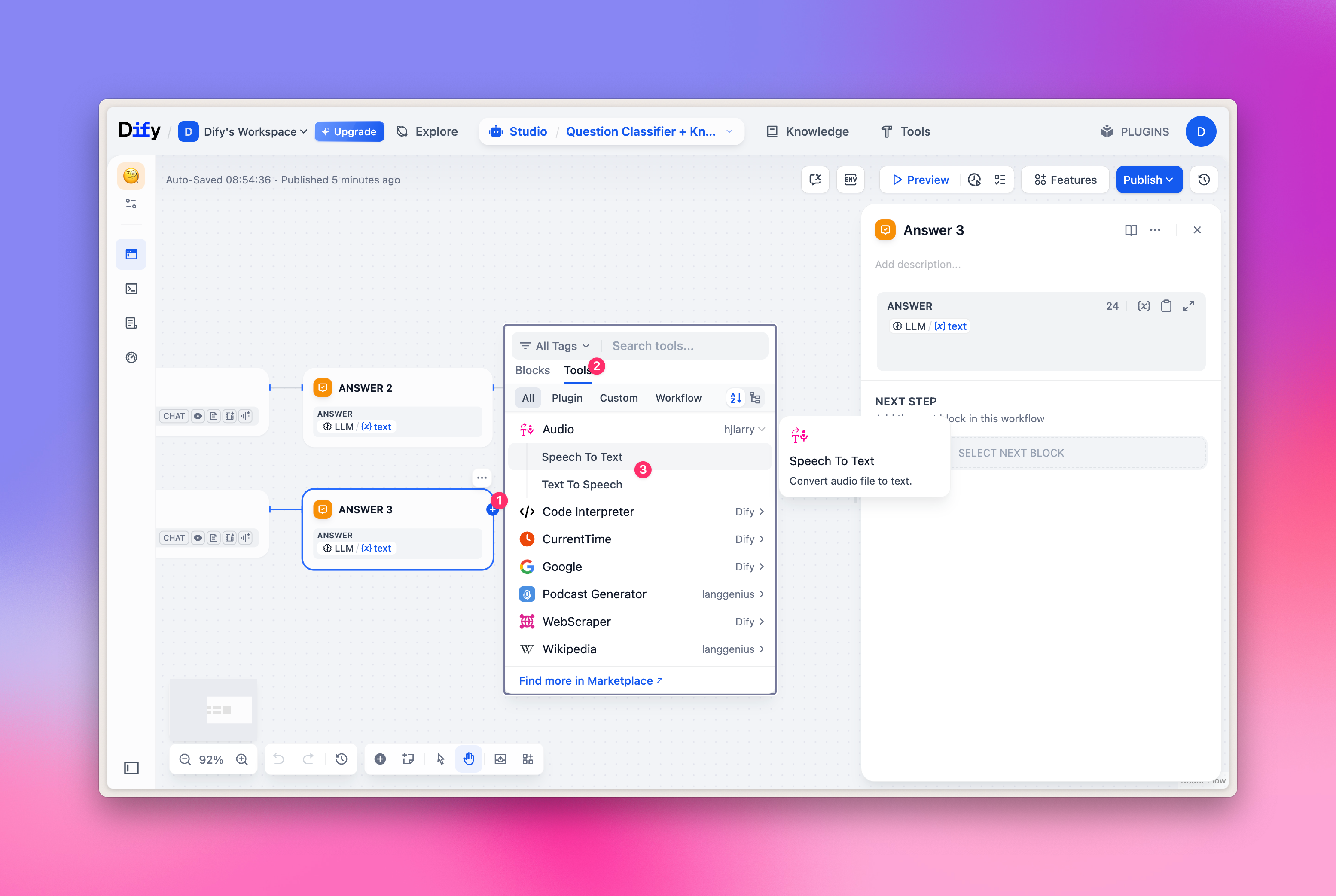
Sélection TTS/SST
Les modèles TTS/SST sont principalement utilisés pour l’analyse et la synthèse vocale. Lors de la sélection des outils, il ne s’agit pas du « LLM » habituel, mais du type « Audio » dans l’onglet « Tools ». Correspondance :- TTS, synthèse vocale : sélectionnez « Text to Speech »
- SST, reconnaissance vocale : sélectionnez « Speech to Text »
Mise en cache des prompts Claude
Activez la mise en cache des prompts pour les modèles Claude dans Dify via ce plugin : encadrez le prompt à mettre en cache avec<cache>…</cache>, et réglez le « seuil de mise en cache automatique des messages volumineux » dans les paramètres du modèle sur un entier positif. Pour l’utilisation complète et les conseils sur les hits de cache, voir Mise en cache des prompts Claude.
Dernière mise à jour : 2026-06-01