Le seuil minimum de mise en cache varie selon le modèle Claude (512 / 1 024 / 2 048 / 4 096) et n’est pas proportionnel au numéro de version : par exemple Opus 4.8 = 1 024, Opus 4.7 = 2 048, Opus 4.6 / Opus 4.5 et Haiku 4.5 = 4 096. La répartition complète figure dans la section « Limitations du cache » ci-dessous. Un contenu inférieur au seuil n’est pas écrit dans le cache, même s’il est marqué avec
cache_control, et aucune erreur n’est renvoyée.Fonctionnement de la mise en cache des prompts
Lorsque vous envoyez une requête avec la mise en cache des prompts activée :- Le système vérifie si un préfixe de prompt, jusqu’à un point de rupture de cache spécifié, est déjà mis en cache à partir d’une requête récente.
- S’il est trouvé, il utilise la version mise en cache, réduisant le temps de traitement et les coûts.
- Sinon, il traite l’intégralité du prompt et met en cache le préfixe dès que la réponse commence. Cela est particulièrement utile pour :
- Les prompts contenant de nombreux exemples
- De grandes quantités de contexte ou d’informations de fond
- Les tâches répétitives avec des instructions cohérentes
- Les longues conversations multi-tours
Erreur courante : « écrire le cache sans jamais le lire »
L’échec le plus courant ressemble à ceci : à chaque requête,cache_creation_input_tokens est élevé (le cache est écrit en permanence), mais cache_read_input_tokens reste à 0 (il n’est jamais relu) — vous n’économisez donc rien.
Il n’y a qu’une seule cause racine : le contenu placé avant le point de rupture de cache (cache_control) a changé entre deux requêtes. Un hit de cache exige que le point de rupture et tout ce qui le précède (dans l’ordre tools → system → messages) soient identiques octet par octet ; si ne serait-ce qu’un seul caractère avant le point de rupture change, l’intégralité du préfixe en cache est invalidée et réécrite.
❌ Mauvaise approche : placer la question variable à chaque tour avant le point de rupture
✅ Bonne approche : grand document en premier + point de rupture + question en dernier
Comparaison mesurée (claude-opus-4-6, quelques secondes entre les deux appels)
Points clés :
- Placez le bloc fixe et volumineux (document de référence, contexte long) tout au début du message utilisateur
messages, aveccache_controlà sa fin, et n’en modifiez pas un seul caractère ; - Placez la question/instruction variable à chaque tour après le point de rupture (après le grand document dans le même message
user, ou dans les messages suivants) ; dans les conversations multi-tours, ajoutez uniquement — ne revenez jamais en arrière pour modifier les messages précédents ; - Lorsque
thinkingest activé, les blocs thinking des tours assistant précédents doivent être renvoyés tels quels, sinon le préfixe se brise de la même manière (voir « Ce qui ne peut pas être mis en cache » ci-dessous) ; - Si un bloc est plus petit que le seuil minimum de cache (de 512 à 4 096 jetons selon le modèle, voir la section « Limitations du cache » ci-dessous), il ne sera pas écrit dans le cache même s’il est marqué avec
cache_control— c’est le comportement attendu, voir « Limitations du cache » ci-dessous.
Tarification
La mise en cache des prompts introduit une nouvelle structure tarifaire. Le tableau ci-dessous indique le prix par million de jetons pour chaque modèle pris en charge :
Remarques :
- Les jetons d’écriture en cache (5 minutes) sont 1,25 fois le prix des jetons d’entrée de base
- Les jetons d’écriture en cache (1 heure) sont 2 fois le prix des jetons d’entrée de base
- Les jetons de lecture en cache sont 0,1 fois le prix des jetons d’entrée de base
- Les jetons d’entrée et de sortie réguliers sont facturés aux tarifs standard de la plateforme
Comment implémenter la mise en cache des prompts
Modèles pris en charge
Toute la gamme des modèles Anthropic Claude prend en charge la mise en cache des prompts, y compris les modèles actuels Opus 4.8 / 4.7 / 4.6 / 4.5, Sonnet 5 / 4.6 / 4.5, Haiku 4.5, Fable 5, ainsi que les modèles antérieurs Opus 4, Sonnet 4, Sonnet 3.7, Sonnet 3.5, Haiku 3.5, Haiku 3 et Opus 3. Le seuil minimum de chaque modèle figure dans la section « Limitations du cache » ci-dessous.Mise en cache automatique (cache_control au niveau racine)
Ajoutez un champcache_control à la racine du corps de requête pour activer la mise en cache automatique : le système applique automatiquement le point de rupture de cache au dernier bloc pouvant être mis en cache et le fait avancer à mesure que la conversation s’allonge, ce qui convient à la mise en cache glissante des conversations multi-tours. Le point de rupture automatique occupe 1 des 4 emplacements de points de rupture et peut être combiné avec des points de rupture explicites au niveau des blocs. Amazon Bedrock ne prend pas en charge la mise en cache automatique.
Structuration de votre prompt
Placez le contenu statique (définitions d’outils, instructions système, contexte, exemples) au début de votre prompt. Marquez la fin du contenu réutilisable à mettre en cache à l’aide du paramètrecache_control.
Les préfixes de cache sont créés dans l’ordre suivant : tools, system, puis messages.
À l’aide du paramètre cache_control, vous pouvez définir jusqu’à 4 points de rupture de cache, ce qui vous permet de mettre en cache séparément différentes sections réutilisables. Pour chaque point de rupture, le système vérifiera automatiquement les correspondances en cache aux positions précédentes et utilisera le préfixe correspondant le plus long s’il en trouve un.
Limitations du cache
La longueur minimale d’un prompt pouvant être mis en cache dépend du modèle :
Les prompts plus courts ne peuvent pas être mis en cache, même s’ils sont marqués avec
cache_control. Toute requête tentant de mettre en cache moins que ce nombre de jetons sera traitée sans mise en cache. Pour savoir si un prompt a été mis en cache, consultez les champs usage dans la réponse.
Pour les requêtes concurrentes, notez qu’une entrée de cache n’est disponible qu’après le début de la première réponse. Si vous avez besoin de hits de cache pour des requêtes parallèles, attendez la première réponse avant d’envoyer les requêtes suivantes.
Durées de vie de cache actuellement prises en charge :
- « ephemeral » : durée de vie par défaut de 5 minutes
- Cache d’1 heure : réglez
"ttl": "1h"danscache_control, pour les scénarios nécessitant une durée de cache plus longue
Durée de cache d’1 heure
Pour les scénarios nécessitant une durée de cache plus longue, nous proposons une option de cache d’1 heure. Il suffit d’inclurettl dans la définition de cache_control, aucun en-tête supplémentaire n’est requis :
Quand utiliser le cache d’1 heure
Le cache d’1 heure est particulièrement adapté à :- Traitement par lots : traitement de gros volumes de requêtes avec des préfixes communs
- Sessions de longue durée : conversations nécessitant le maintien du contexte sur des périodes prolongées
- Analyse de documents volumineux : plusieurs types d’analyses différentes sur le même document
- Questions-réponses sur du code : multiples requêtes sur la même base de code sur des périodes prolongées
Mélanger différents TTL
Vous pouvez mélanger différentes durées de cache au sein d’une même requête :Ce qui peut être mis en cache
Chaque bloc de la requête peut être désigné pour mise en cache avec cache_control. Cela inclut :- Outils : définitions d’outils dans le tableau
tools - Messages système : blocs de contenu dans le tableau
system - Messages : blocs de contenu dans le tableau
messages.content, à la fois pour les tours utilisateur et assistant - Images et documents : blocs de contenu dans le tableau
messages.content, dans les tours utilisateur - Utilisation d’outils et résultats d’outils : blocs de contenu dans le tableau
messages.content, à la fois pour les tours utilisateur et assistant
cache_control pour activer la mise en cache de cette portion de la requête.
Ce qui ne peut pas être mis en cache
Bien que la plupart des blocs de requête puissent être mis en cache, il existe certaines exceptions :- Les blocs thinking ne peuvent pas être mis en cache directement avec
cache_control. Cependant, les blocs thinking PEUVENT être mis en cache aux côtés d’autres contenus lorsqu’ils apparaissent dans des tours assistant précédents. Lorsqu’ils sont mis en cache de cette manière, ils COMPTENT comme jetons d’entrée lorsqu’ils sont lus depuis le cache. - Les sous-blocs de contenu (comme les citations) ne peuvent pas être mis en cache directement. Mettez plutôt en cache le bloc de niveau supérieur.
- Les blocs de texte vides ne peuvent pas être mis en cache.
Suivi des performances du cache
Surveillez les performances du cache à l’aide de ces champs de réponse API, dansusage dans la réponse (ou dans l’événement message_start si vous utilisez le streaming) :
cache_creation_input_tokens: nombre de jetons écrits dans le cache lors de la création d’une nouvelle entrée.cache_read_input_tokens: nombre de jetons récupérés depuis le cache pour cette requête.input_tokens: nombre de jetons d’entrée qui n’ont pas été lus depuis ou utilisés pour créer un cache.
Bonnes pratiques pour une mise en cache efficace
Pour optimiser les performances de la mise en cache des prompts :- Mettez en cache du contenu stable et réutilisable comme les instructions système, les informations de fond, les contextes volumineux ou les définitions d’outils fréquentes.
- Placez le contenu mis en cache au début du prompt pour de meilleures performances.
- Utilisez les points de rupture de cache de manière stratégique pour séparer différentes sections de préfixe pouvant être mises en cache.
- Analysez régulièrement les taux de succès du cache et ajustez votre stratégie au besoin.
- Pour le contenu à long terme, envisagez d’utiliser le cache d’1 heure pour une meilleure efficacité des coûts.
Optimisation selon les cas d’usage
Adaptez votre stratégie de mise en cache des prompts à votre scénario :- Agents conversationnels : réduisez le coût et la latence pour les conversations prolongées, en particulier celles avec de longues instructions ou des documents téléchargés.
- Assistants de programmation : améliorez l’auto-complétion et les questions-réponses sur la base de code en gardant les sections pertinentes ou une version résumée de la base de code dans le prompt.
- Traitement de documents volumineux : intégrez du contenu long complet, y compris des images, dans votre prompt sans augmenter la latence de réponse.
- Ensembles d’instructions détaillées : partagez des listes étendues d’instructions, de procédures et d’exemples pour affiner les réponses de Claude. Les développeurs incluent souvent un ou deux exemples dans le prompt, mais avec la mise en cache des prompts, vous pouvez obtenir de meilleures performances en incluant plus de 20 exemples variés de réponses de haute qualité.
- Utilisation agentique d’outils : améliorez les performances pour les scénarios impliquant plusieurs appels d’outils et modifications itératives de code, où chaque étape nécessite généralement un nouvel appel d’API.
- Dialoguer avec des livres, articles, documentations, transcriptions de podcasts et autres contenus longs : donnez vie à n’importe quelle base de connaissances en intégrant l’ensemble du ou des documents dans le prompt, et permettez aux utilisateurs de poser des questions.
Dépannage des problèmes courants
En cas de comportement inattendu :- Assurez-vous que les sections mises en cache sont identiques et marquées avec cache_control aux mêmes emplacements à travers les appels
- Vérifiez que les appels sont effectués dans la durée de vie du cache (5 minutes ou 1 heure)
- Vérifiez que
tool_choiceet l’utilisation des images restent cohérents entre les appels - Vérifiez que vous mettez en cache au moins le nombre minimum de jetons
- Bien que le système tentera d’utiliser le contenu précédemment mis en cache aux positions antérieures à un point de rupture de cache, vous pouvez utiliser un paramètre
cache_controlsupplémentaire pour garantir la recherche en cache sur les portions précédentes du prompt, ce qui peut être utile pour les requêtes contenant de très longues listes de blocs de contenu
Stockage et partage du cache
- Isolation par organisation : les caches sont isolés entre les organisations. Différentes organisations ne partagent jamais leurs caches, même si elles utilisent des prompts identiques.
- Correspondance exacte : les hits de cache nécessitent des segments de prompt 100 % identiques, y compris tous les textes et images jusqu’au bloc marqué avec cache_control (inclus). Le même bloc doit être marqué avec cache_control lors des lectures et créations de cache.
- Génération de jetons de sortie : la mise en cache des prompts n’a aucun effet sur la génération des jetons de sortie. La réponse que vous recevez sera identique à celle que vous obtiendriez sans la mise en cache des prompts.
Activer la mise en cache Claude dans les clients / plateformes
De nombreux clients n’offrent aucun champ pour renseigner directementcache_control ; à la place, ils l’injectent pour vous via leur propre « sucre syntaxique » ou des commutateurs. La règle sous-jacente est exactement la même que ci-dessus — le préfixe mis en cache doit rester identique mot pour mot à chaque tour, et le contenu variable doit être placé après le point de rupture de cache — sinon vous « écrirez sans jamais lire » (voir « Erreur courante » ci-dessus).
Dify (via le plugin Aihubmix)
Le plugin Dify d’Aihubmix hérite du sucre syntaxique du plugin officiel d’Anthropic. Activez-le en deux étapes :- Encadrez le prompt à mettre en cache (le prompt système fixe / le contexte long) avec
<cache>…</cache>; le plugin le convertira automatiquement en un point de rupturecache_controlà cet endroit ; - Dans les paramètres du modèle, réglez le « seuil de mise en cache automatique des messages volumineux » sur un entier positif : le cache n’est réellement écrit qu’une fois que le contenu atteint ce seuil de jetons (toujours soumis à l’exigence de cache minimum décrite dans « Limitations du cache » ci-dessous, soit 4096 jetons pour Opus 4.5/4.6 et Haiku 4.5) ; le régler à 0 ou le laisser vide le désactive.
Cherry Studio
Lorsque Cherry Studio appelle Claude via Aihubmix, la mise en cache est désactivée par défaut (le « Cache Token Threshold » vaut0 par défaut) ; vous devez l’activer dans les « API Settings » du fournisseur.
- Cliquez sur l’engrenage à droite du nom du fournisseur Aihubmix pour ouvrir les « API Settings » :
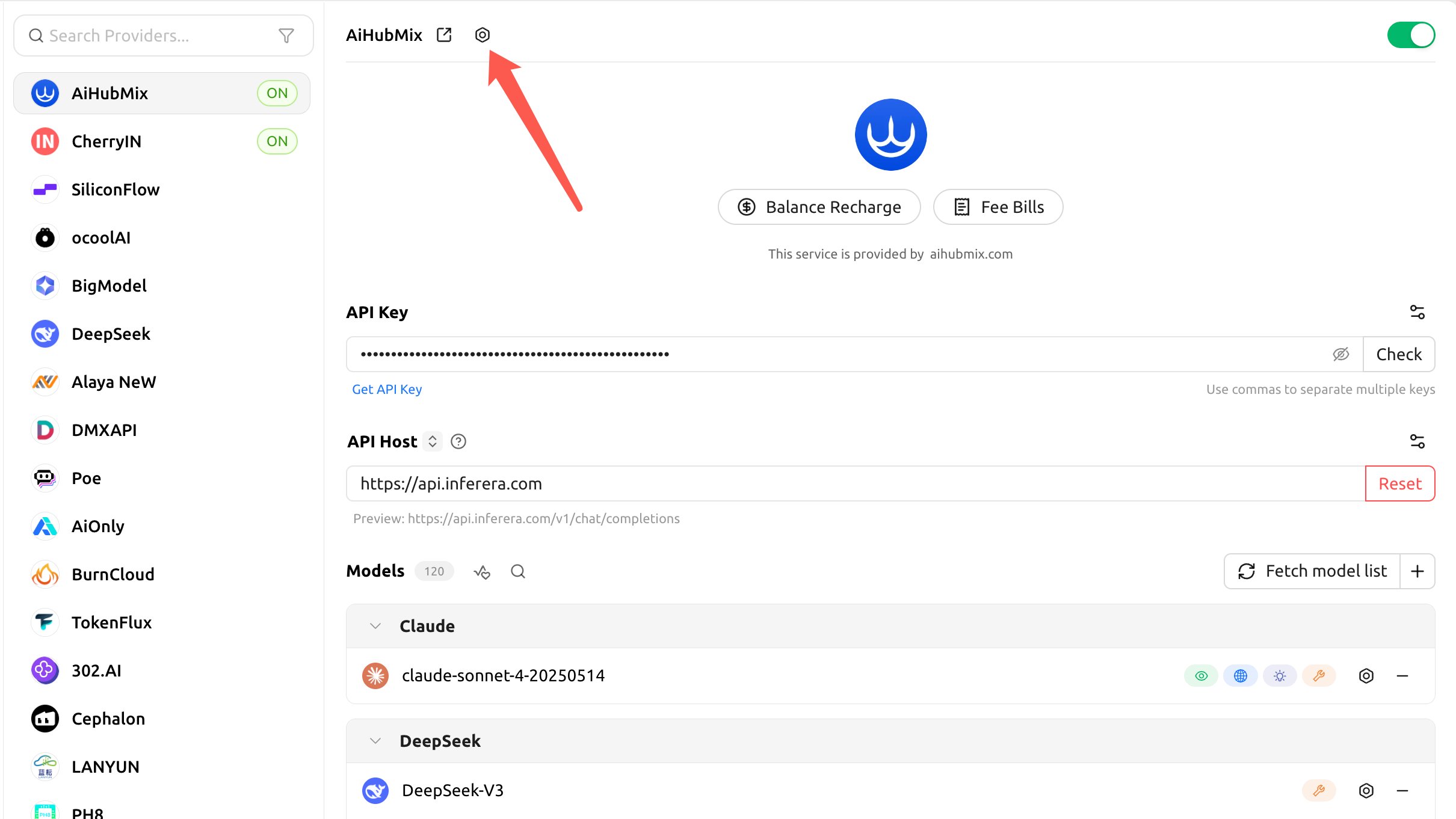
- Configurez les trois éléments suivants, et le client injectera automatiquement
cache_controlpour Claude en conséquence :
- Cache Token Threshold : un point de rupture de cache n’est injecté qu’une fois que le contenu dépasse ce nombre de jetons (réglez un nombre positif pour activer, 0 ou vide pour désactiver) ;
- Cache System Message : une fois activé, un point de rupture de cache est placé sur le message
system(idéal pour mettre en cache un prompt système long et fixe) ; - Cache Last N Messages : place un point de rupture de cache sur les N messages les plus récents (idéal pour une mise en cache glissante dans les conversations multi-tours).
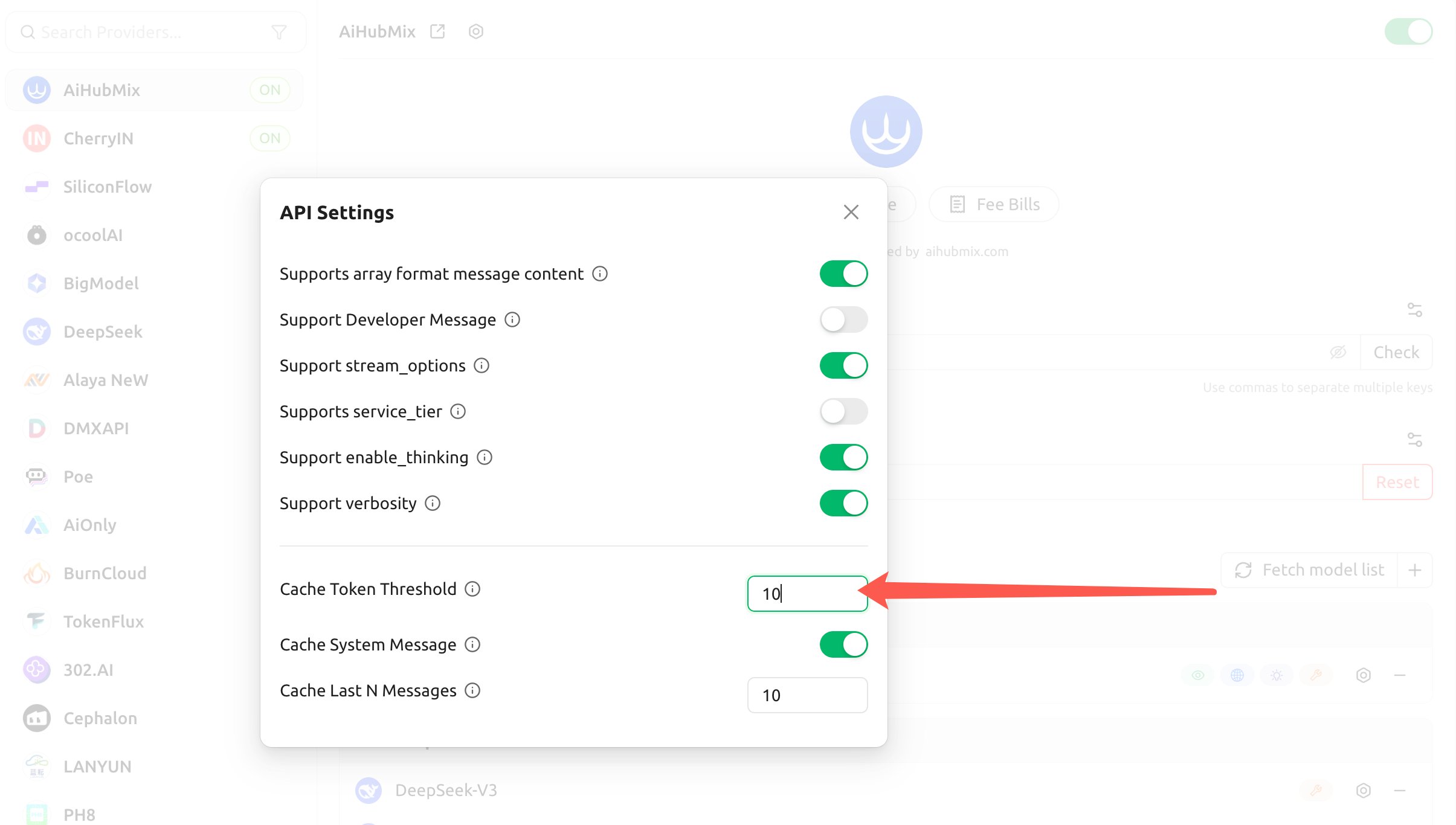
Les seuils ci-dessus déterminent uniquement « quand le client injecte un point de rupture » ; ils ne modifient pas l’exigence de cache minimum d’Anthropic : l’écriture effective requiert toujours que le contenu mis en cache atteigne le nombre minimum de jetons de cache (4096 pour Opus 4.5/4.6 et Haiku 4.5). Si vous placez du contenu qui change à chaque tour (comme une instruction tournante) dans le prompt système mis en cache, vous « écrirez sans jamais lire » de la même manière.
Foire aux questions (FAQ)
Pourquoi le cache est-il écrit (cache_creation_input_tokens élevé) mais jamais lu (cache_read_input_tokens à 0) ?
Parce que le contenu placé avant le point de rupture de cache (cache_control) a changé entre deux requêtes. Un hit exige que le point de rupture et tout ce qui le précède soient identiques octet par octet ; dès que vous placez du contenu qui change à chaque tour avant le point de rupture, l’intégralité du préfixe en cache est invalidée et réécrite à chaque tour. Placez le contenu fixe en premier et le contenu variable après le point de rupture, voir « Erreur courante » ci-dessus.
Combien de jetons faut-il au minimum pour la mise en cache ?
Le contenu en dessous de la longueur minimale de cache n’est pas mis en cache, même s’il est marqué aveccache_control. Pour Claude Opus 4.5/4.6 et Haiku 4.5, le seuil est de 4096 jetons ; la plupart des autres modèles Claude sont à 1024 jetons, et Haiku 3/3.5 à 2048 jetons. Voir « Limitations du cache » ci-dessus.
Combien de temps le cache reste-t-il valide ? Peut-on passer à 1 heure ?
Par défaut 5 minutes, rafraîchi sans frais à chaque hit. Pour une durée plus longue, réglez"ttl": "1h" dans cache_control, aucun en-tête supplémentaire n’est requis. L’écriture en cache au palier 1 heure est facturée à 2 fois le prix d’entrée de base. Voir « Durée de cache d’1 heure » ci-dessus.
Comment activer la mise en cache dans Dify / Cherry Studio ?
Ces clients ne permettent pas de renseigner directementcache_control : Dify encadre le contenu à mettre en cache avec <cache>…</cache> et règle le « seuil de mise en cache automatique des messages volumineux » ; Cherry Studio configure « Cache Token Threshold / Cache System Message / Cache Last N Messages » dans les « API Settings ». Voir « Activer la mise en cache Claude dans les clients / plateformes » ci-dessus.
Prise en charge selon les différents modèles
- La prise en charge de la mise en cache des prompts dépend du modèle lui-même.
- Si le modèle prend en charge nativement la mise en cache sans nécessiter de déclarations de paramètres explicites, cela peut être pris en charge via la redirection compatible OpenAI.
- OpenAI prend en charge la mise en cache des prompts par défaut, avec application automatique (préfixe ≥1024 jetons). Pour les modèles antérieurs à GPT-5.6, l’écriture en cache est sans facturation supplémentaire et le cache est effacé automatiquement après 5 à 10 minutes d’inactivité ; pour GPT-5.6 et suivants, l’écriture en cache est facturée à 1,25 fois le prix d’entrée, la lecture à 0,1 fois, le cache est conservé au moins 30 minutes et les points de rupture de cache explicites sont pris en charge. Détails sur Mise en cache des prompts GPT.
- Claude nécessite la déclaration native
cache_control: { type: "ephemeral" }. Le taux de mise en cache est 1,25 fois le coût d’entrée standard (5 minutes) ou 2 fois (1 heure), la récupération des jetons en cache coûte 0,1 fois le tarif normal, avec un cycle de vie de 5 minutes ou 1 heure. Détails - Deepseek V3 et R1 prennent en charge nativement la mise en cache. Le taux de mise en cache est égal au coût d’entrée standard, la récupération des jetons en cache coûte 0,1 fois le tarif normal. Détails
- Gemini prise en charge du cache implicite :
- Mise en cache implicite : activée par défaut pour tous les modèles Gemini 2.5. Si votre requête atteint le cache, les économies de coûts sont automatiquement appliquées. Cette fonctionnalité est effective depuis le 8 mai 2025. Le nombre minimum de jetons d’entrée pour la mise en cache du contexte est de 1 024 pour Gemini 2.5 Flash et 2 048 pour Gemini 2.5 Pro.
- Astuces pour améliorer le taux de succès du cache implicite :
- Essayez de placer le contenu volumineux et fréquemment réutilisé au début du prompt.
- Essayez d’envoyer des requêtes avec des préfixes similaires dans une courte fenêtre temporelle.
- Vous pouvez voir le nombre de jetons en cache hit dans le champ
usage_metadatade l’objet de réponse. - Les économies de coûts sont calculées sur la base des hits de cache de prefill. Seuls le cache de prefill et le cache de prétraitement vidéo YouTube sont éligibles à la mise en cache implicite.
Dernière mise à jour : 2026-07-10