Different Claude models have different minimum cacheable token thresholds (512 / 1,024 / 2,048 / 4,096), and the threshold is not proportional to the model version number: for example, Claude Opus 4.8 is 1,024, Claude Opus 4.7 is 2,048, and Claude Opus 4.6 / 4.5 and Claude Haiku 4.5 are 4,096. See the full breakdown under “Cache limitations” below. Content below the threshold will not be written to the cache even if marked with
cache_control, and no error is returned.How prompt caching works
When you send a request with prompt caching enabled:- The system checks if a prompt prefix, up to a specified cache breakpoint, is already cached from a recent query.
- If found, it uses the cached version, reducing processing time and costs.
- Otherwise, it processes the full prompt and caches the prefix once the response begins. This is especially useful for:
- Prompts with many examples
- Large amounts of context or background information
- Repetitive tasks with consistent instructions
- Long multi-turn conversations
Common mistake: “writing the cache but never reading it”
The most common failure looks like this: every request has a largecache_creation_input_tokens (the cache is being written constantly), but cache_read_input_tokens stays at 0 (it’s never read back) — so you save nothing.
There’s only one root cause: the content before the cache breakpoint (cache_control) changed between two requests. A cache hit requires that the breakpoint and everything before it (in tools → system → messages order) be byte-for-byte identical; if even a single character before the breakpoint changes, the entire prefix cache is invalidated and rewritten.
❌ Wrong: putting the per-turn question before the breakpoint
✅ Correct: large document first + breakpoint + question last
Measured comparison (claude-opus-4-6, a few seconds between the two calls)
Key points:
- Put the fixed, large block (reference document, long context) at the very front of the
messagesuser message, withcache_controlat its end, and do not change a single character of it; - Put the per-turn question/instruction after the breakpoint (after the large document within the same
usermessage, or in subsequent messages); in multi-turn conversations, only append — never go back and edit earlier messages; - When
thinkingis enabled, thinking blocks in earlier assistant turns must be passed back verbatim, otherwise the prefix breaks the same way (see “What cannot be cached” below); - If a block is smaller than the minimum cache threshold (which varies by model, from 512 to 4,096 tokens — see “Cache limitations” below), it won’t be written to the cache even if marked with
cache_control— this is expected behavior, see “Cache limitations” below.
Pricing
Prompt caching introduces a new pricing structure. The table below shows the price per million tokens for each supported model:
Note:
- 5-minute cache write tokens are 1.25 times the base input tokens price
- 1-hour cache write tokens are 2 times the base input tokens price
- Cache read tokens are 0.1 times the base input tokens price
- Regular input and output tokens are priced at platform standard rates
How to implement prompt caching
Supported models
Prompt caching is supported across all Anthropic Claude models, including the current Claude Opus 4.8 / 4.7 / 4.6 / 4.5, Claude Sonnet 5 / 4.6 / 4.5, Claude Haiku 4.5, and Claude Fable 5, as well as earlier models such as Claude Opus 4, Sonnet 4, Sonnet 3.7, Sonnet 3.5, Haiku 3.5, Haiku 3, and Opus 3. See the minimum threshold for each model under “Cache limitations” below.Automatic caching (top-level cache_control)
Add a singlecache_control field at the top level of the request body to enable automatic caching: the system automatically applies the cache breakpoint to the last cacheable block and moves it forward as the conversation grows, which suits rolling caching in multi-turn conversations. The automatic breakpoint uses 1 of the 4 breakpoint slots and can be combined with block-level explicit breakpoints. Automatic caching is not supported on Amazon Bedrock.
Structuring your prompt
Place static content (tool definitions, system instructions, context, examples) at the beginning of your prompt. Mark the end of the reusable content for caching using thecache_control parameter.
Cache prefixes are created in the following order: tools, system, then messages.
Using the cache_control parameter, you can define up to 4 cache breakpoints, allowing you to cache different reusable sections separately. For each breakpoint, the system will automatically check for cache hits at previous positions and use the longest matching prefix if one is found.
Cache limitations
The minimum cacheable prompt length varies by model, and is not proportional to the model version number:
Shorter prompts cannot be cached, even if marked with
cache_control. Any requests to cache fewer than this number of tokens will be processed without caching. To see if a prompt was cached, see the response usage fields.
For concurrent requests, note that a cache entry only becomes available after the first response begins. If you need cache hits for parallel requests, wait for the first response before sending subsequent requests.
Currently supported cache lifetimes:
- “ephemeral”: Default 5-minute lifetime
- 1-hour cache: Set
"ttl": "1h"incache_control, for scenarios requiring longer cache duration
1-hour cache duration
For scenarios requiring longer cache duration, we provide a 1-hour cache option. Includettl in the cache_control definition; no additional request header is required:
When to use 1-hour cache
1-hour cache is particularly suitable for:- Batch processing: Processing large volumes of requests with common prefixes
- Long-running sessions: Conversations requiring context maintenance over extended periods
- Large document analysis: Multiple different types of analysis on the same document
- Codebase Q&A: Multiple queries on the same codebase over extended periods
Mixing different TTLs
You can mix different cache durations within the same request:What can be cached
Every block in the request can be designated for caching with cache_control. This includes:- Tools: Tool definitions in the
toolsarray - System messages: Content blocks in the
systemarray - Messages: Content blocks in the
messages.contentarray, for both user and assistant turns - Images & Documents: Content blocks in the
messages.contentarray, in user turns - Tool use and tool results: Content blocks in the
messages.contentarray, in both user and assistant turns
cache_control to enable caching for that portion of the request.
What cannot be cached
While most request blocks can be cached, there are some exceptions:- Thinking blocks cannot be cached directly with
cache_control. However, thinking blocks CAN be cached alongside other content when they appear in previous assistant turns. When cached this way, they DO count as input tokens when read from cache. - Sub-content blocks (like citations) themselves cannot be cached directly. Instead, cache the top-level block.
- Empty text blocks cannot be cached.
Tracking cache performance
Monitor cache performance using these API response fields, withinusage in the response (or message_start event if streaming):
cache_creation_input_tokens: Number of tokens written to the cache when creating a new entry.cache_read_input_tokens: Number of tokens retrieved from the cache for this request.input_tokens: Number of input tokens which were not read from or used to create a cache.
Best practices for effective caching
To optimize prompt caching performance:- Cache stable, reusable content like system instructions, background information, large contexts, or frequent tool definitions.
- Place cached content at the prompt’s beginning for best performance.
- Use cache breakpoints strategically to separate different cacheable prefix sections.
- Regularly analyze cache hit rates and adjust your strategy as needed.
- For long-term content, consider using 1-hour cache for better cost efficiency.
Optimizing for different use cases
Tailor your prompt caching strategy to your scenario:- Conversational agents: Reduce cost and latency for extended conversations, especially those with long instructions or uploaded documents.
- Coding assistants: Improve autocomplete and codebase Q&A by keeping relevant sections or a summarized version of the codebase in the prompt.
- Large document processing: Incorporate complete long-form material including images in your prompt without increasing response latency.
- Detailed instruction sets: Share extensive lists of instructions, procedures, and examples to fine-tune Claude’s responses. Developers often include an example or two in the prompt, but with prompt caching you can get even better performance by including 20+ diverse examples of high quality answers.
- Agentic tool use: Enhance performance for scenarios involving multiple tool calls and iterative code changes, where each step typically requires a new API call.
- Talk to books, papers, documentation, podcast transcripts, and other longform content: Bring any knowledge base alive by embedding the entire document(s) into the prompt, and letting users ask it questions.
Troubleshooting common issues
If experiencing unexpected behavior:- Ensure cached sections are identical and marked with cache_control in the same locations across calls
- Check that calls are made within the cache lifetime (5 minutes or 1 hour)
- Verify that
tool_choiceand image usage remain consistent between calls - Validate that you are caching at least the minimum number of tokens
- While the system will attempt to use previously cached content at positions prior to a cache breakpoint, you may use an additional
cache_controlparameter to guarantee cache lookup on previous portions of the prompt, which may be useful for queries with very long lists of content blocks
Cache storage and sharing
- Organization Isolation: Caches are isolated between organizations. Different organizations never share caches, even if they use identical prompts.
- Exact Matching: Cache hits require 100% identical prompt segments, including all text and images up to and including the block marked with cache control. The same block must be marked with cache_control during cache reads and creation.
- Output Token Generation: Prompt caching has no effect on output token generation. The response you receive will be identical to what you would get if prompt caching was not used.
Enabling Claude caching in clients / platforms
Many clients have no field to fill incache_control directly; instead they inject it for you via their own “syntactic sugar” or toggles. The underlying rule is exactly the same as above — the cached prefix must stay verbatim across every turn, and changing content goes after the cache breakpoint — otherwise you’ll “write but never read” (see “Common mistake” above).
Dify (via the Aihubmix plugin)
The Aihubmix Dify plugin inherits the syntactic sugar of Anthropic’s official plugin. Enable it in two steps:- Wrap the prompt you want to cache (the fixed system prompt / long context) in
<cache>…</cache>, and the plugin will automatically convert it into acache_controlbreakpoint at that point; - In the model parameters, set the “auto-cache threshold for large messages” to a positive integer: the cache is only actually written once the content reaches that token threshold (still subject to the minimum cache requirement in “Cache limitations” below, which is 4096 tokens for Opus 4.5/4.6 and Haiku 4.5); setting it to 0 or leaving it blank disables it.
Cherry Studio
When Cherry Studio calls Claude through Aihubmix, caching is off by default (the “Cache Token Threshold” defaults to0); you need to turn it on in the provider’s “API Settings”.
- Click the gear to the right of the Aihubmix provider name to open “API Settings”:
- Configure the following three items, and the client will automatically inject
cache_controlfor Claude accordingly:
- Cache Token Threshold: a cache breakpoint is only injected once the content exceeds this number of tokens (set a positive number to enable, 0 or blank to disable);
- Cache System Message: when enabled, a cache breakpoint is placed on the
systemmessage (good for caching a fixed long system prompt); - Cache Last N Messages: places a cache breakpoint on the most recent N messages (good for rolling caching in multi-turn conversations).
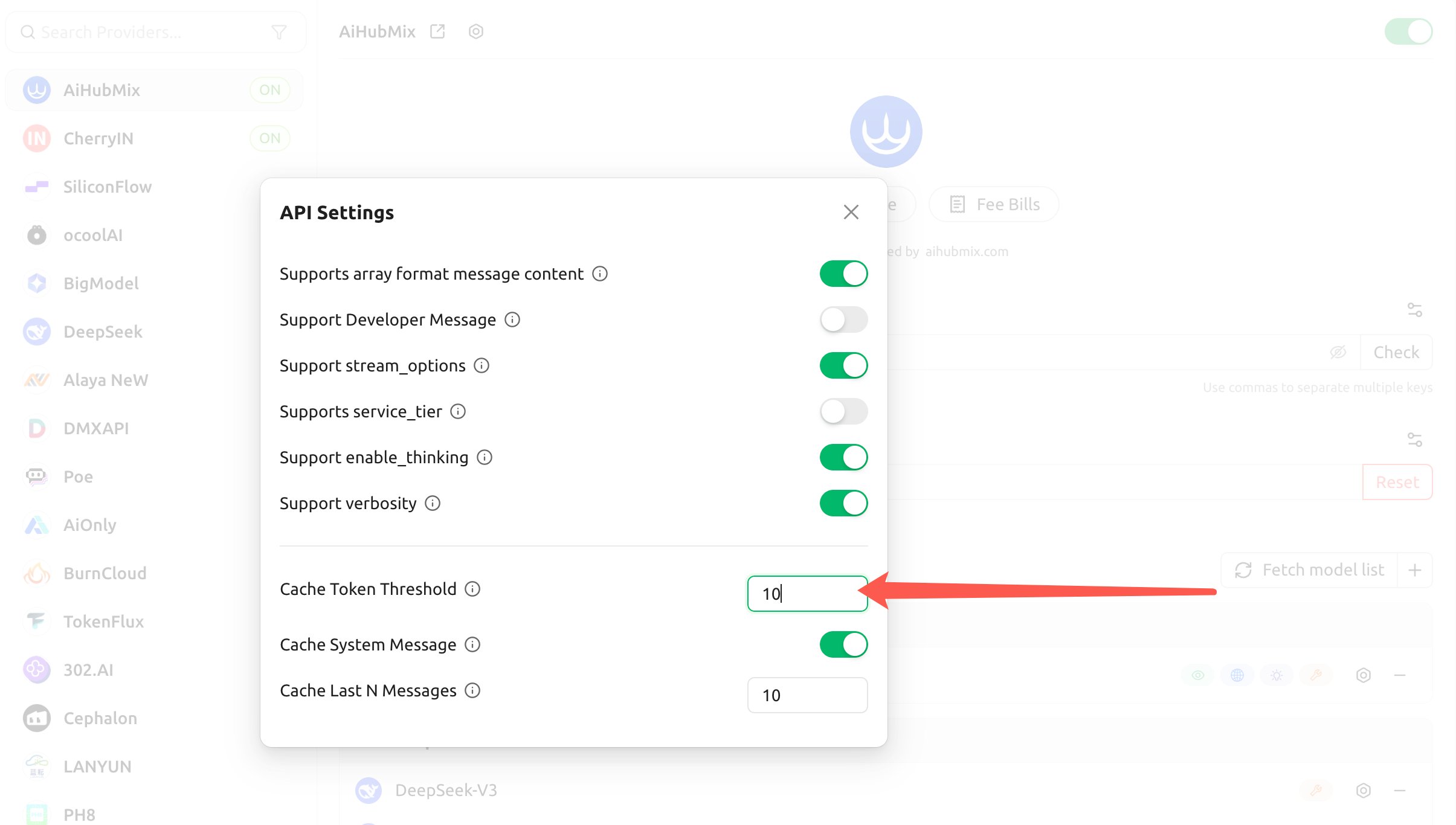
The thresholds above only determine “when the client injects a breakpoint”; they do not change Anthropic’s minimum cache requirement: the actual write still requires the cached content to reach the minimum cache tokens (4096 for Opus 4.5/4.6 and Haiku 4.5). If you put content that changes every turn (such as a rotating instruction) into the cached system prompt, you’ll likewise “write but never read”.
FAQ
Why is the cache being written (cache_creation_input_tokens is large) but never read (cache_read_input_tokens is 0)?
Because the content before the cache breakpoint (cache_control) changed between two requests. A hit requires the breakpoint and everything before it to be byte-for-byte identical; once you put content that changes every turn before the breakpoint, the entire prefix cache is invalidated and rewritten on every turn. Put the fixed content first and the changing content after the breakpoint — see “Common mistake” above.
What is the minimum number of tokens needed for caching?
Content below the minimum cache length won’t be cached even if marked withcache_control. It’s 4096 tokens for Claude Opus 4.5/4.6 and Haiku 4.5; most other Claude models are 1024 tokens, and Haiku 3/3.5 are 2048 tokens. See “Cache limitations” above.
How long does the cache last? Can it be changed to 1 hour?
By default 5 minutes, refreshed at no cost on every hit. For a longer duration, set"ttl": "1h" in cache_control; no additional request header is required. 1-hour cache writes are billed at 2x the base input rate. See “1-hour cache duration” above.
How do I enable caching in Dify / Cherry Studio?
These clients don’t takecache_control directly: Dify wraps the content to cache in <cache>…</cache> and sets an “auto-cache threshold for large messages”; Cherry Studio sets “Cache Token Threshold / Cache System Message / Cache Last N Messages” under “API Settings”. See “Enabling Claude caching in clients / platforms” above.
Support Across Different Models
- Whether Prompt Caching is supported depends on the model itself.
- If the model inherently supports caching without requiring explicit parameter declarations, it can be supported through OpenAI-compatible forwarding.
- OpenAI supports prompt caching by default, applied automatically (prefix of 1,024 tokens or more). On models before GPT-5.6, cache writes have no additional fee and caches are cleared after 5-10 minutes of inactivity; on GPT-5.6 and later, cache writes are billed at 1.25x the input rate, cache reads at 0.1x, caches are retained for at least 30 minutes, and explicit cache breakpoints are supported. See GPT Prompt Caching.
- Claude requires the native
cache_control: { type: "ephemeral" }declaration. Caching rate is 1.25 times the standard input cost (5-minute) or 2 times (1-hour), cached token retrieval costs 0.1 times the normal rate, with a 5-minute or 1-hour lifecycle. Details - Deepseek V3 and R1 natively support caching. Caching rate equals the standard input cost, cached token retrieval costs 0.1 times the normal rate. Details
- Gemini implicit caching support:
- Implicit Caching: Enabled by default for all Gemini 2.5 models. If your request hits the cache, cost savings are automatically applied. This feature is effective as of May 8, 2025. The minimum input token count for context caching is 1,024 for Gemini 2.5 Flash and 2,048 for Gemini 2.5 Pro.
- Tips to improve implicit cache hit rate:
- Try placing large, frequently reused content at the beginning of the prompt.
- Try sending requests with similar prefixes within a short time window.
- You can view the number of cache-hit tokens in the
usage_metadatafield of the response object. - Cost savings are calculated based on prefilled cache hits. Only prefill cache and YouTube video preprocessing cache are eligible for implicit caching.
Last updated: 2026-07-10